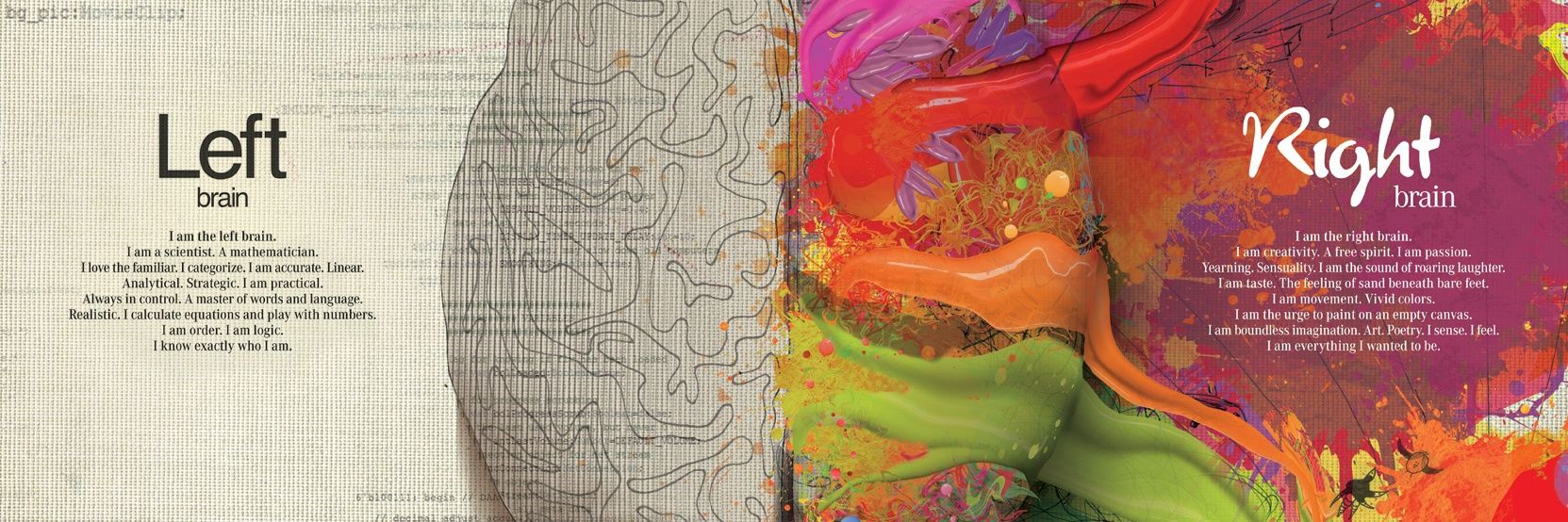
Sabitlenmiş Tweet

Data Science meets classic poetry: a reinterpretation of Dante's Divine Comedy from the point of view of ML lifecycle!
@rmattivi/if-dante-were-a-data-scientist-inferno-data-part-i-4d5ae073ff32" target="_blank" rel="nofollow noopener">medium.com/@rmattivi/if-d…
#chatgpt used to augment my skills and adapt the most famous parts of
• Inferno -> Data
• Purgatorio -> Modelling
• Paradiso -> Prod
English















