друже не дуже
11.9K posts


друже не дуже
@rofh
той ближче до неба, кому нічого не треба
Divagación de cauce y migración de meandros del río Mississippi nos recuerda que el lecho de un río no es fijo en el tiempo. Las obras de ingeniería que quieran fijar un cauce son ilusorias en la dinámica fluvial. Obra maestra cartográfica del geólogo Harold Fisk. 1944 🇺🇸
How it works: - 2x usage on weekdays outside 5–11am PT / 12–6pm GMT - 2x usage all day on weekends - Automatic, nothing to enable




What you're looking at is not a sunrise — it's the Russian LNG tanker ARCTIC METAGAZ (IMO 9243148) struck by a massive explosion in the Mediterranean this morning. Photographed by crew aboard a merchant vessel, via Vanguard Tech.




@Bilka_lisova 😅😅😅





є у мене персональний штучка інтелект помічник Даймон для складних задач, але для сімʼї я зробив меншого тупішого брата, Дімона і додав його в чат. з усіма відключеннями повний піздос і холодіна, але хоча б Дімон старається бути корисним



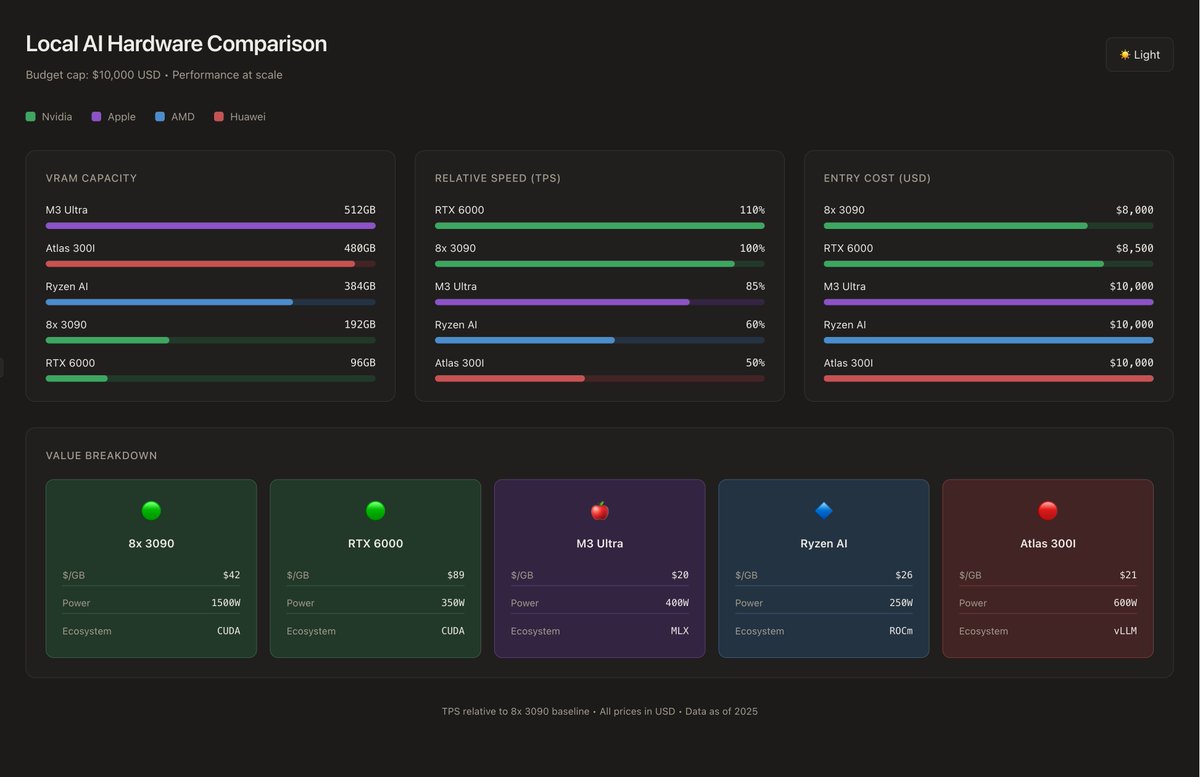
Top 5 builds for AI inference in 2025-2026 I have spent around 6-9 months researching, building, experimenting, and bench-marking AI models, tools, hardware and costs. Top 3 picks will be the safest, best cost to performance ratios. The last 2 will be more interesting experiments that I think are worthwhile for people to take on. This list will be capped at an entry price of 10k USD for an end engine, I do this to avoid wild variance in performance. ---------------- #1. Mac M3 Ultra 512GB RAM This device costs around 10k USD new in the US, 12k new in EU, and around 6-9k used around the world (not often is it available used, but a snag if you have the interest and budget) When I wanted to get into this, the Mac was my first option. I have owned a Macbook Pro M1 Max for over 2 years (it's 4 years old now) and I really believe it can be my daily driver for 10 years to come if they support it. MLX has improved drastically in the last few months, performance is reaching ~100% of Nvidia 3090s, same bandwidth for inference. It is the cheapest way to run Kimi-K2, Deepseek, GLM-4.6, and Minimax-M2 at full context, without extreme quantization. Specifically and most importantly, the power usage is incredibly low, the whole thing at full throttle is less than 1x 3090 Evga max. Pros: > 10K USD~ 500~ GB of usable relatively high bandwidth memory > 400W at PEAK power usage, less than 1 3090 Evga > MLX is very fast, and there's tons of quantizations out there > If you network 2 of these you can HIT 1TB, you'd need minimum 50k USD to do that with NVidia > Easily available, tiny, clean, beautiful OS Cons: > No CUDA, this is a huge con tbh > Higher starting cost, you need 10k~ up front, with Nvidia and DDR4 you can get 96 VRAM and 128 DDR4 at 5k > MLX still becomes very slow after 64k tokens, vllm and sglang hold performance through to the last token. > You don't learn as much, since it's all abstracted away from you > Can't train or finetune on this build Overall I would recommend this for 90% of people --------------------- #2 Nvidia 8x 3090s || 4x 4090D Super || 8x 4080D This is what I ended up choosing (3090s), I put the Chinese mods on the list, as if you're brave enough they could be worth the risk. Nvidia has a choke hold on this market, their GPUs were the first to support LLMs at scale, so a lot of software was built on top of their hardware. Here you can get: - 192GB VRAM for 8x 3090s (24GB VRAM each) || 4x 4090D Super mods from China (48GB VRAM each) - 256GB VRAM for 8x 4080 mods from China (32GB VRAM each) With this you can run: - GLM-4.6-Reap at Q4 (near losses performance for coding, and tech work) . coding - Minimax-m2 at Q4 (Incredible model) . digital assistant - GLM-4.5 Air at FP8 . writing and coding - GPT-OSS-120B . Math and medical - Hermes-70B . Drug knowledge, no censorship - GLM-4.5V & Qwen-3-235B-VL Pros: > Fastest inference money can buy > Have access to anything ever built AI related > Holding retail value decently for now > Can train on these > Lots of learning Cons: > Less VRAM higher cost > Messy as hell > Guzzles electricity, 1500W for full system IF YOU CAP it at 50% wattage (20% inference performance loss) > Market is drying up, at least where I live > Upgrading beyond 8 is impractical, you need to bring in an electrician --------------------- #3. Ryzen AI Max+ (Framework Desktop or DIY AM5 Mini-ITX) This option gives you a very respectable amount of inference RAM for relatively cheap maxing out at about 384GB for 10k USD~ I am a big fan of Framework, and what they're doing but you can DIY this yourself if you want something more custom. You get a fast, quiet, lowish power draw rig which is expandable in 128GB increments at around 3k USD (so you can start with 128GB) You can run almost all the same model at relatively decent speeds, with a still maturing ecosystem of software. this gets you past 4x 3090s for nearly half the price and 1/10th the hassle, but you got some flaws. This is the same build Gosucoder runs, I would check this channel out for a demo with GLM and Qwen Pros: > Cheaper than most options out there > Very impressive amount of RAM > Has stable enough support > Quiet, lower power draw Cons: > No CUDA > Stuck with ROCm, which is not so bad, but under developed > Requires a lot more configuration and finicky software > Supply shortages. > Slower than Nvidia and MLX for raw TPS ----------------------- #4. Nvidia RTX 6000 Blackwell 96GB For those with more disposable income, and are looking for maximum longevity, support, dependability, and upgradability this is the best Nvidia option. They cost between 7-10K USD each, are very clean, small, have high vram per card, run blackwell, and are the best mix of VRAM/Cost/Speed for Nvidia With one of these you can GLM-4.5-Air-4 bit, GPT-OSS-120B, multiple small smart models at the same time at blistering speeds, you get vllm, sglang, and practically every tool out there. You can upgrade to 2, for 192gb VRAM it costs 2x the 3090s for same vram, but at less than half the power draw, with hardware that'll be good for at least 5 years to come. Pros: > Huge VRAM per size/card > Very very fast > Nvidia ecosystem > Modern, clean, has longevity > Upgradability has a good outlook, you can get up to 8 of these for 768GB VRAM on a household circuit > Training beast Cons: > Highest price per GB of VRAM > Assuming you can save 6-10k usd a year it would take you 1 year to add more to your cluster ------------------------ #5. Huawei Atlas 300I Duo 96 During my search for more VRAM I came across these chips from Huawei, they have 400gb/s bandwidth, cost 1600$ USD pre tariffs pr card, and have 96GB VRAM With 10k USD you can get 480GB VRAM, at half the speed of 3090s, which would be incredible for running the big boys. This shouldn't be something you consider seriously if you're not interested in debugging for days, translating Chinese forums, and having your github tickets stuck for months. Pros: > So much VRAM per $ > Decent speeds > Easy to start, try 1, and resell if you don't like it (1.5-2k USD for 96gb vram) > Support for Chinese cards is only growing > You can make some BANGER content, given not many people have touched these cards in the west > vLLM SUPPORT! Cons: > Low bandwidth, lowest on this list > Probably not doable for US citizens > Very finnicky software and hardware > Little information online about this > Gotta order from China