Sabitlenmiş Tweet
Ashish Prajapati
474 posts


Ashish Prajapati
@room_ashish
19 | Building https://t.co/0tNnOpzhMl
india Katılım Mart 2025
40 Takip Edilen32 Takipçiler

Why I'm changing everything, and how I can improve my tutorials
also a face reveal
English
@VaibhavSisinty This is exactly what we're measuring at SkillsBench.
Codex with Skills: 33.2% → 48.1% on verifiable coding tasks.
The agents aren't just running longer — they're getting better
with the right Skills layer on top.
skillsbench.milkeyai.com
English

Codex is WILDDD!!
Ran for 8 hours straight. No heartbeat.
Gave it a brutal task:
rewrite backend + data pipelines end to end
(security, speed, edge functions, DB schemas)
Came back… and it had actually made serious progress.
This wasn’t a script.
This felt like a 5x sr engineer grinding for 8 hours.
Cost: 5,000+ credits 😅
I’ve seen 16-hour runs before, but this hit different.
Feels like we’re moving from “AI tools” → “AI systems you manage”
Shoutout to @gabrielchua and Vasundhara for unlocking me when I was stuck 🙌
What’s the longest you’ve let AI run on its own?

English
Introducing SkillsBench by @MilkeyskillsAI
The first benchmark that measures whether AI agent Skills actually make coding agents better.
Not vibes. Real numbers.
Claude Code Opus 4.7: 32.4% → 51.6% ⚡
Gemini CLI: 34.5% → 53.8% ⚡
Every agent we tested improved with Skills.
Everyone benchmarks the model.
Nobody was benchmarking the Skills layer.
We fixed that.
skillsbench.milkeyai.com 👇
English
@keter_slater appreciate this keter 🙏 consistency is literally the whole thesis — one broken skill update shouldn't silently wreck 10 agents. that's exactly why we built the hosted layer. would love to have you test it and break things 👀
English
Everyone's racing to build AI agents.
Nobody's thinking about what makes them actually work consistently.
The answer is skills — reusable, curated, hosted instructions your agent pulls at runtime.
That's exactly what we built at Milkey.
One platform. Works with Cursor, Claude Code, Codex, Windsurf. No more copying Skills files across every repo.
→ milkeyai.com

English
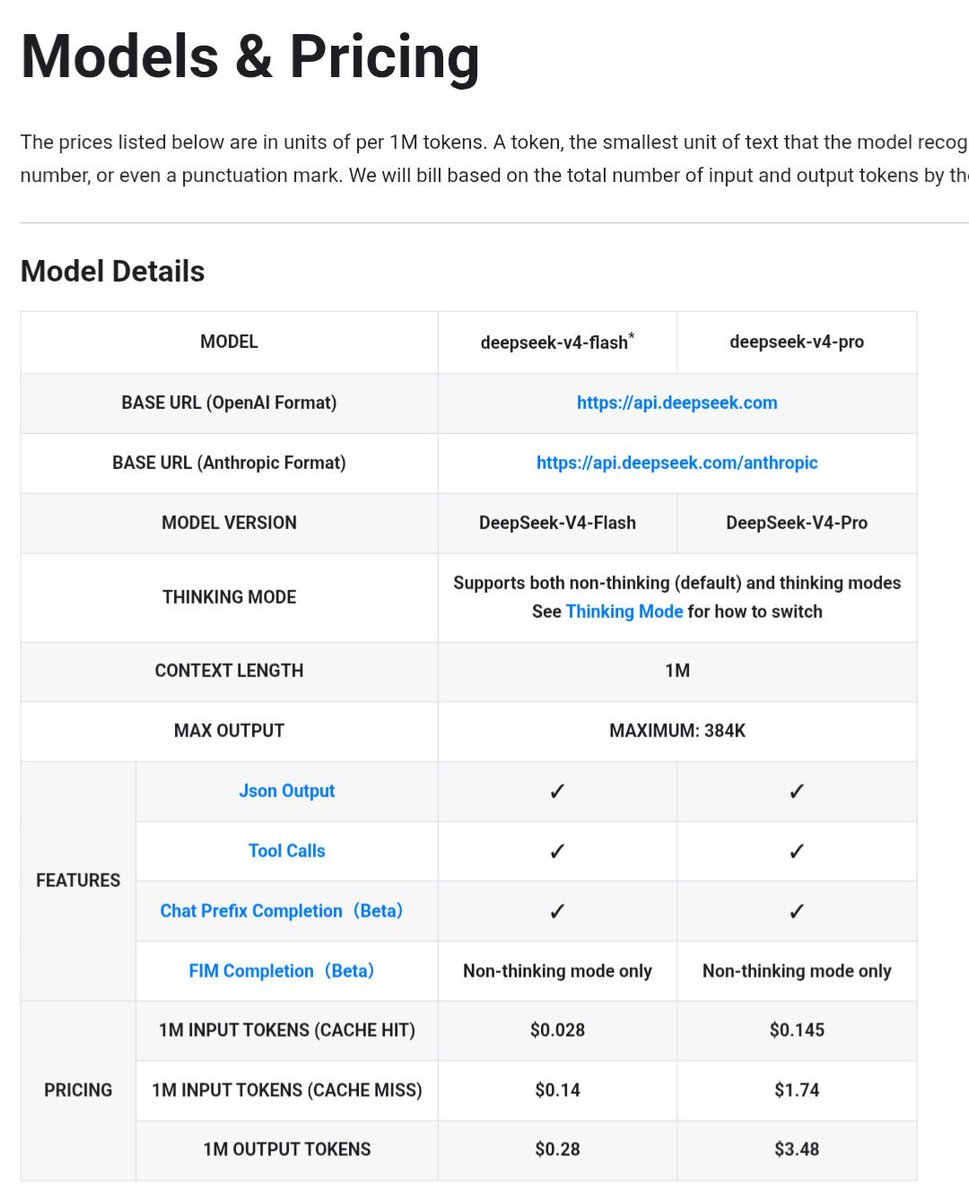
DeepSeek V4 is here 👀
• 1M token context window
• Max output: 384K tokens
• V4-Flash: $0.14/1M input | $0.28/1M output
• V4-Pro: $1.74/1M input | $3.48/1M output
• Supports thinking mode + tool calls + JSON output
• SWE : 80.6
The price-to-performance ratio is insane. This changes everything again 🔥
#DeepSeek #AI #LLM
English


OpenAI has updated codex model list so gpt-5.4 no longer says “latest frontier”

EternalTwilight@eternal_twil
@JasonBotterill github.com/openai/codex/c… gearing up indeed
English

GPT-5.5 and GPT-5.5 Pro just appeared in the OpenRouter model registry.
Both dated 2026-04-23. Today.
openai/gpt-5.5-20260423
openai/gpt-5.5-pro-20260423
The drop is imminent. Hours, not days.
Live testing on stream the second endpoints go live. BridgeBench scores same day.

English
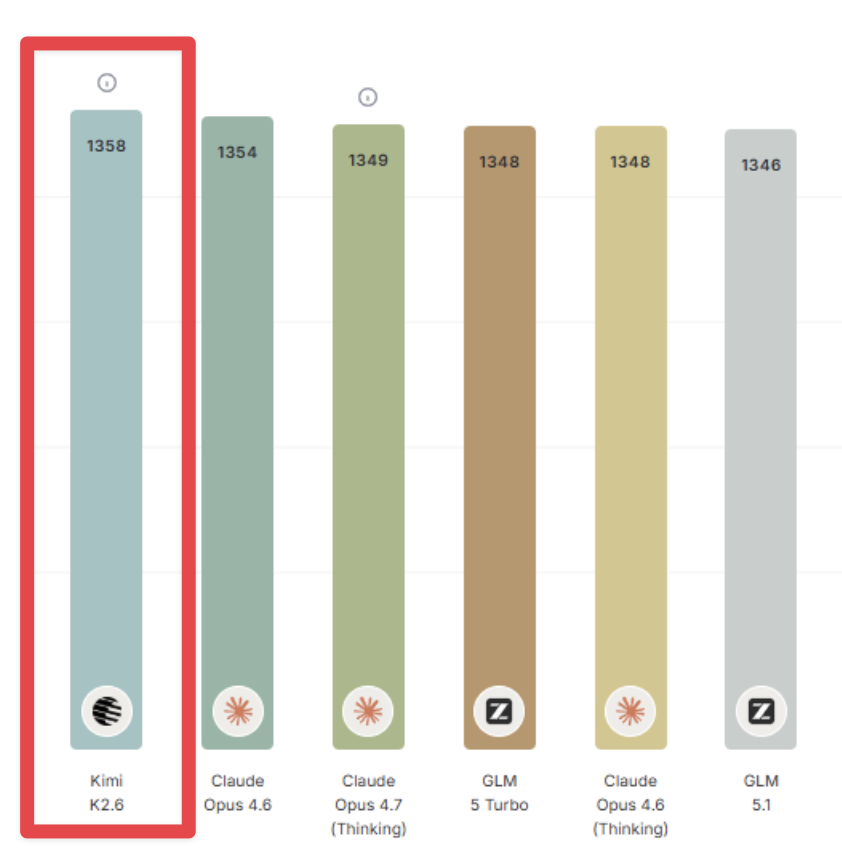
Kimi K2.6 is now #1 on Design Arena.
Ahead of Opus 4.7. Ahead of Opus 4.6. Ahead of GLM 5 Turbo.
An open-source Chinese model just took the design crown from Anthropic.
This is insane.
English
@matthewmillerai lets go! mine also looks similar but grinding is everyday and still waiting for GPT-5.5 😄

English

My GitHub contribution chart for April.
22 days. Zero skipped.
Every green square is a commit on BridgeMind.
Every dark square is a shipping day.
While everyone's waiting for GPT 5.5, I'm shipping.
Consistency compounds.

English
milkeyai.com just got accepted into Momentum by @Devlabs_club 🧡
First ever cohort. We are in it.
Here is what we are building.
AI agents are getting smarter every day. But the skills they run on are a complete mess. Scattered. Copy-pasted. Inconsistent.
Milkey fixes that.
One hosted platform for curated, reusable AI agent skills. Works with Cursor, Claude Code, Codex and more via MCP, REST API and our TypeScript SDK.
We shipped quietly. No noise. Just building.
Now we go all in for 4 weeks.
Thank you @BhoomiSinghani for believing in us.
Building in public from here. Follow along.
milkeyai.com
#BuildingInPublic #AIAgents #MCP #DevTools

English

WE ARE NOT DONE STACKING!
@supermemory just joined the Momentum Founder Stack.
$1,000 in API credits. For every single founder.
Build with one of the best memory infrastructure out there. Forget nothing. Ship everything.
T-3 days!
Apply if you haven't yet - devlabs.club/momentum.
Momentum is now unforgettable :)

English
GPT 5.5 is going to beat Claude Opus 4.7.
I'm calling it now.
Anthropic did not set the bar very high.
The improvement from Opus 4.6 to 4.7 is real but incremental.
Benchmaxed benchmarks.
35% more tokens.
Reduced security.
Sam Altman said GPT 5.5 Spud is going to be a leap.
Two years of research. Not an incremental update.
He better be telling the truth.
I used to love OpenAI.
Then Claude Code happened and I switched.
Now Anthropic is rate limiting me on two $200/month subscriptions.
Testing GPT 5.5 the moment it drops tomorrow.
BridgeBench results same day.
English
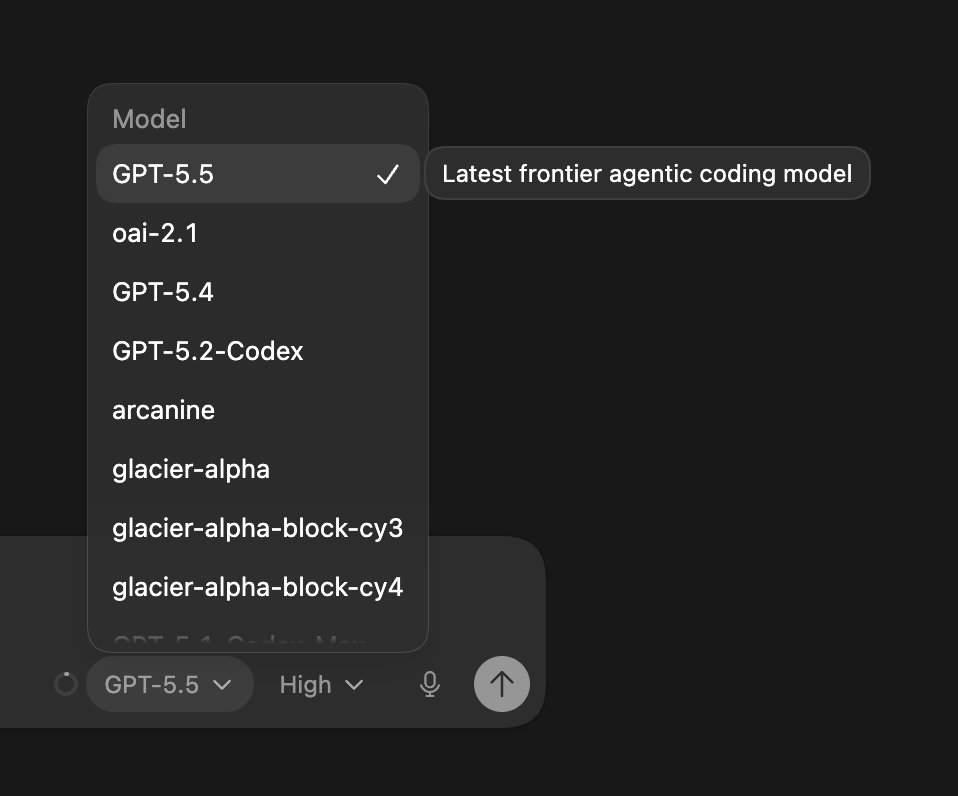
GPT-5.5 just quietly dropped inside Codex.
Not announced. Not on the website. Just... there.
Along with codenames like "heisenberg", "arcanine", and "glacier-alpha" 👀
OpenAI is cooking something. 🔥
English

Codex hit 4M active users, less than two weeks after hitting 3M.
We will reset rate limits today!
English
Your AI agent is only as good as the instructions you give it every single time.
Most teams write the same code review logic, the same doc structure, the same support response rules — over and over, across every chat, every repo, every teammate.
That's not an AI problem. That's a missing skills layer.

English