Sabitlenmiş Tweet

Thrilled to share that our paper ImageRAG has been accepted to #ICLR2026 🤩🇧🇷
Check it out: rotem-shalev.github.io/ImageRAG/
@RinonGal @ohadf @bermano_h
Rotem Shalev-Arkushin@rotemsh3
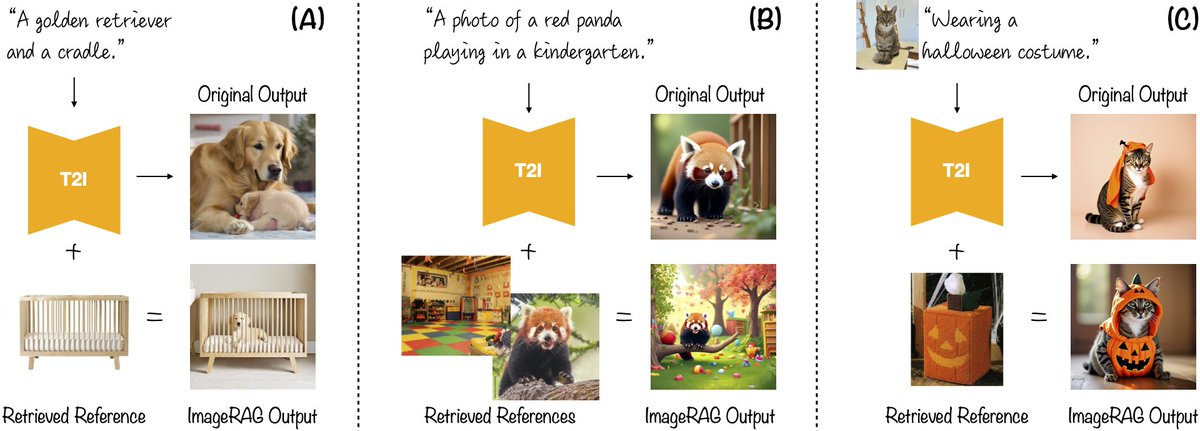
Excited to introduce our new work: ImageRAG 🖼️✨ rotem-shalev.github.io/ImageRAG We enhance off-the-shelf generative models with Retrieval-Augmented Generation (RAG) for unknown concept generation, using a VLM-based approach that’s easy to integrate with new & existing models! [1/3]
English