Sabitlenmiş Tweet

Our #CVPR2025 work is out!🚀
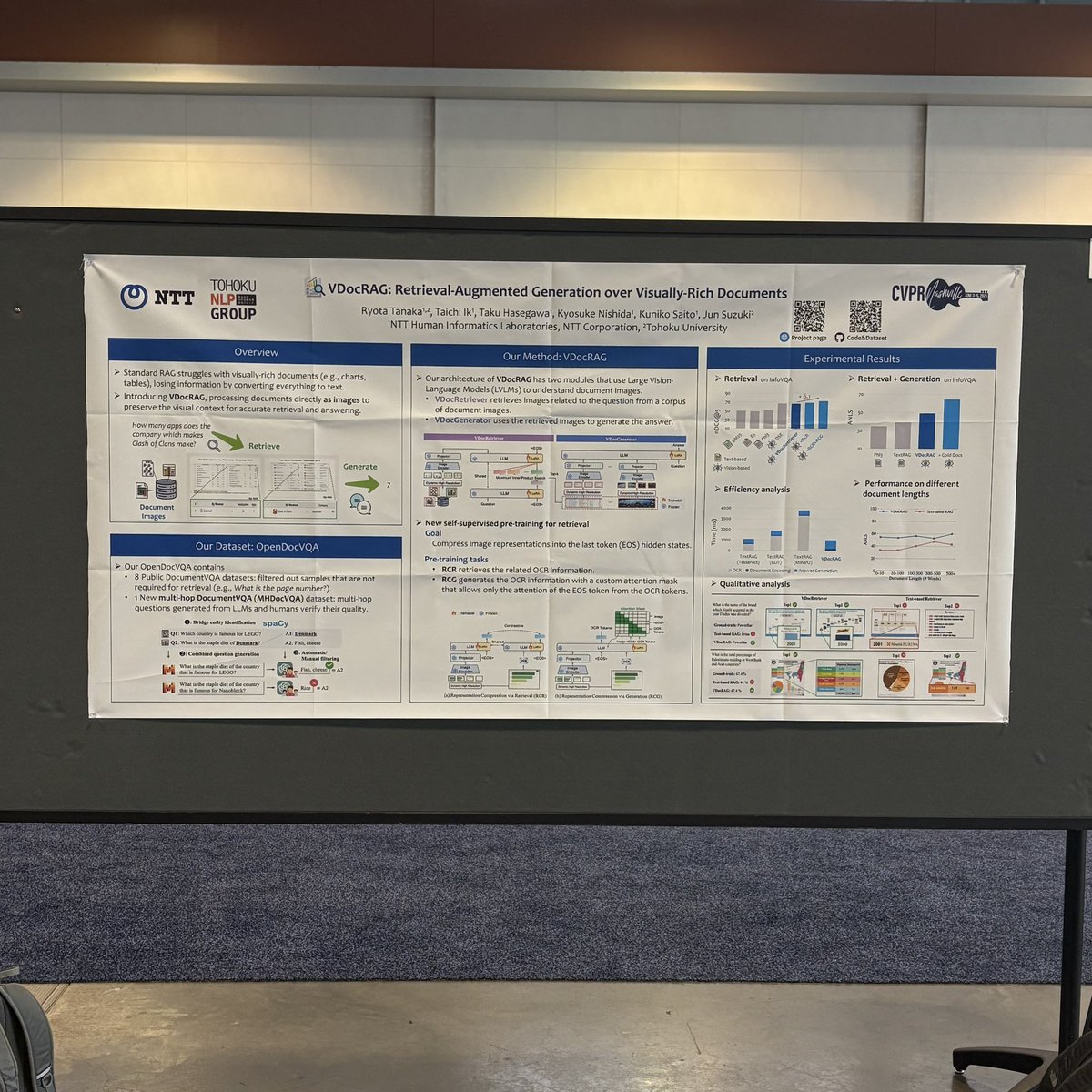
𝘾𝙖𝙣 𝙬𝙚 𝙗𝙪𝙞𝙡𝙙 𝙍𝘼𝙂 𝙩𝙝𝙖𝙩 𝙪𝙣𝙙𝙚𝙧𝙨𝙩𝙖𝙣𝙙𝙨 𝙫𝙞𝙨𝙪𝙖𝙡𝙡𝙮-𝙧𝙞𝙘𝙝 𝙙𝙤𝙘𝙪𝙢𝙚𝙣𝙩𝙨 𝙡𝙞𝙠𝙚 𝙘𝙝𝙖𝙧𝙩𝙨/𝙩𝙖𝙗𝙡𝙚𝙨?
Yes! VDocRAG understands them through visual features.
📰arxiv.org/abs/2504.09795
🌐vdocrag.github.io
GIF
English
Ryota Tanaka
499 posts

@rtanaka_lab
NLP, Vision&Language @ NTT Human Informatics Laboratories
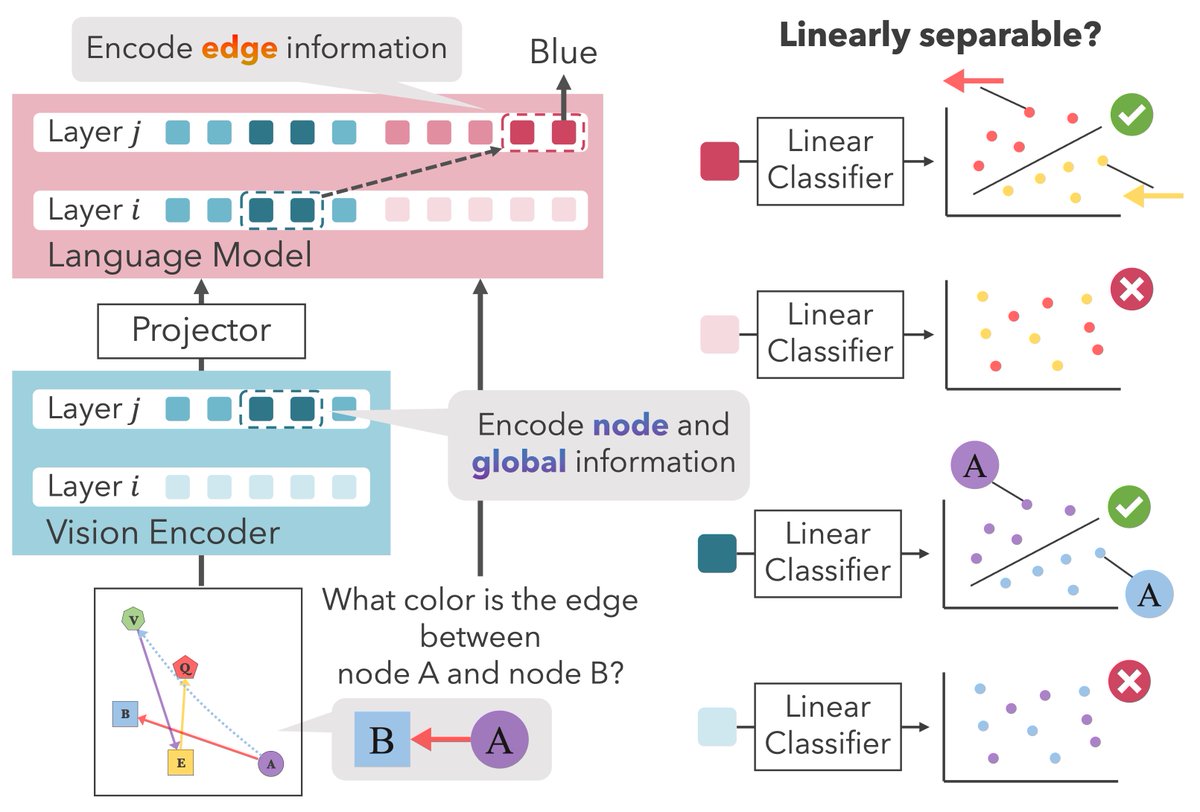
#NLP2026 にて、NTT tsuzumiチームが優秀賞5件、若手奨励賞1件を受賞しました! これを励みに、今後も大規模言語モデル「tsuzumi」の開発と、革新的な研究の両面で、より一層挑戦を続けて参ります。採用も積極的に行っていますので、tsuzumi のR&Dに興味をお持ちいただけた方は、ぜひご連絡ください! ntt-labs.jp/saiyo/ ■ 優秀賞(718件中16件) 位置符号化の基底拡大戦略は外挿性能を制限する 岡 佑依 (NTT/東北大), 斉藤 いつみ (東北大), 西田 京介 (NTT) 周波数エントロピーによる位置埋込みの解明 岡 佑依 (NTT), 花房 健太郎 (愛媛大), 長谷川 拓, 西田 京介 (NTT) CMDR: 文脈を考慮したマルチモーダル文書検索 田中 涼太, 長谷川 拓, 西田 京介 (NTT) Let's Put Ourselves in Sally's Shoes: 他人の靴プレフィリングは大規模言語モデルの心の理論を改善する 篠田 一聡, 北条 伸克, 西田 京介, 山﨑 善啓, 鈴木 啓太, 杉山 弘晃, 齋藤 邦子 (NTT) 大規模視覚言語モデル内部におけるダイアグラムの表現形成過程 吉田 遥音, 工藤 慧音, 青木 洋一 (東北大), 田中 涼太 (NTT), 斉藤 いつみ, 坂口 慶祐, 乾 健太郎 (東北大) ■ 若手奨励賞(517件中21件) ハルシネーションから学ぶ:内部表現への介入によるハルシネーション抑制 門谷 宙, 西田 光甫, 西田 京介 (NTT)


/ 更なる進化を遂げた #tsuzumi 2 の提供開始📢✨ \ 軽量でありながら高性能な日本語処理性能を持つ LLM「tsuzumi 2」の提供を本日開始しました💫 サイバーセキュリティ分野への応用、自律的に連携し議論する AI コンステレーション等の開発も進めます! #NTTRD