
Ryan Teehan
264 posts
Ryan Teehan
@rteehas
PhD Student @nyuniversity | prev. @stabilityai | x-cofounder @carperai | prev. @uchicago @TTIC_Connect
Katılım Mayıs 2022
1.4K Takip Edilen297 Takipçiler

hopefully we're done with ARC-AGI after this, I don't think it aligns with anything useful/interesting
loveofdoing@loveofdoing
316 ARC-AGI tasks solved with zero learning. No neural net, no training, no DSL — just 19th-century projective geometry. Encode grid cell relationships as Plücker lines in P³, find transversals via Schubert calculus, score candidates by geometric incidence. 95% solve rate on the eval set (of non-timeout tasks). Single C file, runs in seconds.
English
@dilanesper I mean, the protests were severely repressed, it's hard to keep momentum for many years, and there officially was a ceasefire. Not really surprising that the protest landscape is different now
English

isn't it pretty obvious that a whole academic and activist omnicause apparatus built around Palestine preexisted and was activated by October 7? You can't easily duplicate that.
Josh Kraushaar@JoshKraushaar
“Some academics think that the students themselves are different: Whether because of concerns about the worsening job market or a cultural shift rightward, they seem less interested in raising hell on campus.” theatlantic.com/ideas/2026/03/…
English

somehow, despite the proposal of “learning to compose abstractions from noisy data” being an incredibly general problem, there’s exactly one (1) industry lab that’s focusing on it outside of vidgen.
English
@leothecurious I've been working on something related to this in my down time, which I really need to write up soon
English

yess, someone gets it!! this is very important for people to internalize and truly grok. supervising from a hierarchy of interdependent representations forces coherence across network layers, and rules out spurious features as those have less predictable components than their simpler robust and generalizable counterparts. i bet this works across modalities and will be a default aspect of generative models in the (hopefully) near future. predicting the raw data alone (be it text or pixels) is not constraining enough for the network to converge onto robust (see FER hypothesis) representations of the data.
James Chen@jchencxh
Only a very high-level target (at the extreme, think class labels) can make shortcut solutions easier. If the loss has to explain a hierarchy instead of just a high-level target, you impose more semantic constraints on the representation, and you get less spuriousness.
English
@tallinzen I don't really let LLMs touch my writing aside from checking for typos or suggesting alternatives to a clunky sentence tbh
English

tried to use a couple of LLMs for feedback on a manuscript and wasn't so impressed with the results, they did catch a lot of typos but the higher-level suggestions were pretty basic (and sometimes just lame). probably "skill issue" in that I couldn't spend a lot of time prompt engineering as I had a paper deadline. what are people using that they actually find helpful?
English
@PetarV_93 Separately, have always found Neil Ghani's category theory work interesting. I periodically try to find a deep learning application for his paper with Michael Abbott, Thorsten Altenkirch, and Conor McBride on differentiating data structures
English

@rteehas we actually used kripke's quus example to motivate one of our recent papers!
arxiv.org/abs/2507.08796
in general many of our recent works concern out-of-distribution behaviours, so i am not surprised by the parallels to wittgenstein... but there is progress that can be made :)
English
Maybe it is just my latent Wittgensteinianism, but the construction for the bitstring example feels like it has the same flavor as the rule-following paradox
Petar Veličković@PetarV_93
new preprint! turns out, if your model is confident on _any_ long enough input, we can find other inputs where the model is wrong, yet its perplexity won't really tell you it's wrong 📉 work with @fedzbar @ccperivol @sindero and Razvan
English
@PetarV_93 I like the idea of connecting a certain kind of extrapolation with equivariance to some transformation. Out of curiosity, have you explored making the transformation to which you are equivariant data-dependent?
English
@PetarV_93 Oh that's very cool, thanks for the pointer. I've always had a soft spot for Wittgenstein and his work inspired some of my research interests when applying to PhD programs. I guess it's not too surprising how many problems feel like a return to Wittgenstein or Hume, though
English
English

@mean_field_zane @typeclonghouse They recognize that it has good free speech, but there aren’t enough ROTC students, courses are too hard, too many alumni trying for academia
Shoulda gone to Auburn
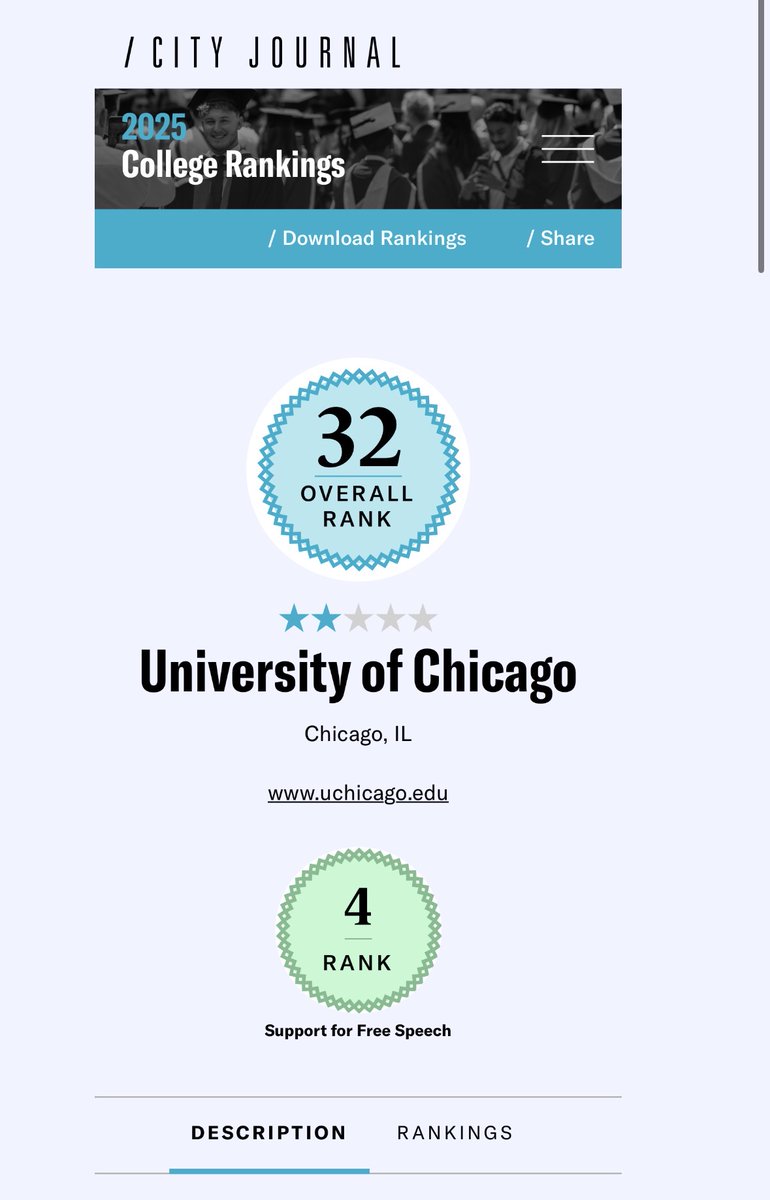
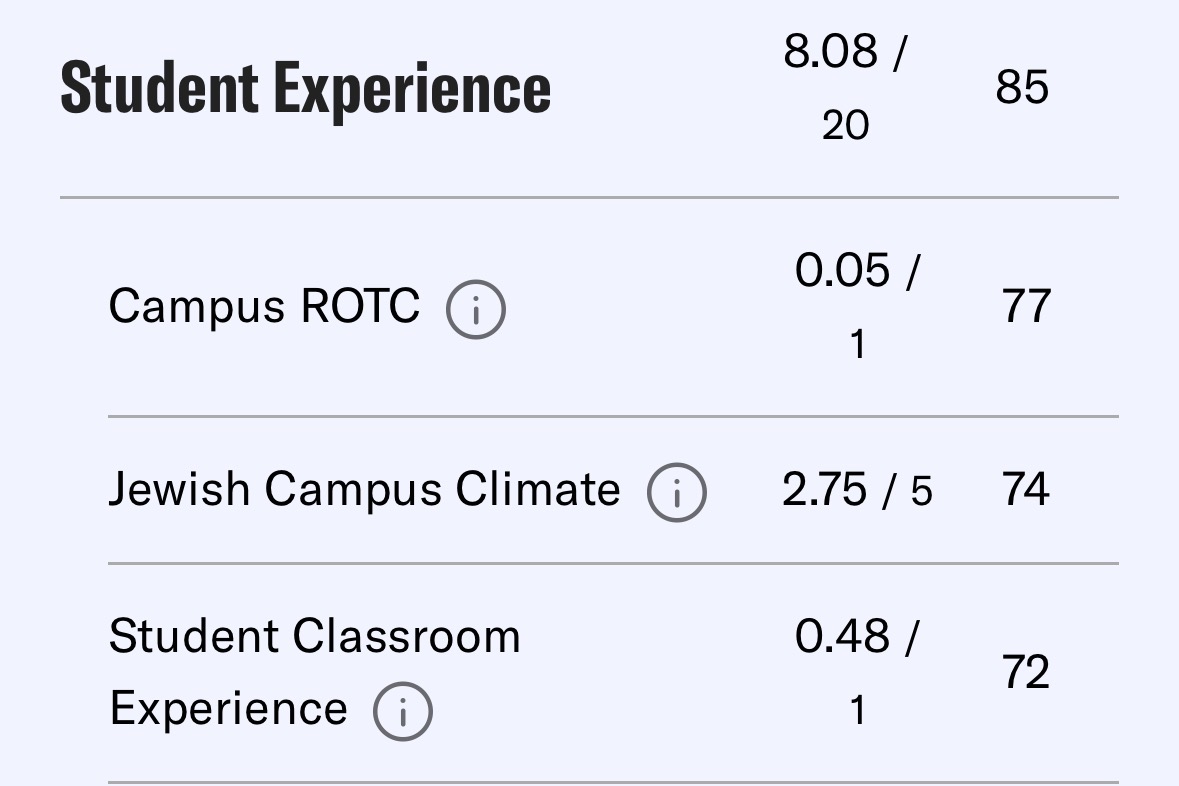

English

The funniest thing is that the Top 10 school specialized for being pro-free speech and anti-DEI isn’t mentioned because it’s not well known amongst retards.
yung macro 宏观年少传奇@apralky
The Manhattan Institute's inaugural 2025 university rankings btw, released as "a necessary corrective to outdated lists." The Bari Weiss slopulists have invented ways of reality-bending undreamt of by the undynamic DEI geriatrics
English
Ryan Teehan retweetledi

Excited to see my work with @rteehas on
"When Does Verification Pay Off? A Closer Look at LLMs as Solution Verifiers" featured here!
arXiv link: arxiv.org/pdf/2512.02304 👀
NYU Center for Data Science@NYUDataScience
Do stronger LLMs make better verifiers? Not necessarily when grading themselves. New work led by Courant PhD student Jack Lu (@Jacklu_me) and CDS Asst Prof Mengye Ren (@mengyer) shows that cross-family verification outperforms self-verification. nyudatascience.medium.com/study-reveals-…
English
@_onionesque I'm good! We should catch up next time you're in the city
English

I have decided to join Google Deepmind. Very curious about the next leg.
English
Ryan Teehan retweetledi

At Agentic Learning AI Lab, the best part of our research is working with the incredible students. They are the ones writing the code, running the experiments, and solving the hard problems in AI today.
As we approach the end of the year, we are fundraising to ensure these students have the resources they need to thrive in 2026.
Unlike big industry labs, we rely on grants and gifts to keep our research independent and open. If you’d like to support the next generation of AI researchers of our lab at NYU, please visit the link below!
English

Lab gathering at #NeurIPS2025. Proud of this year’s work and excited about the ideas we’re building toward next!



English
Was Hermann Weyl a big fan of Rilke? I was surprised to see him mentioned in the foreword of a translation of Sonnets to Orpheus.

English
Take a look at our recent study of test-time verification!
We present some interesting results about, among other things, the benefits of choosing a verifier from a different model family than your solver.
Jack Lu@Jacklu_me
Wondering how to get the most out of LLM test-time verification? New study: “When Does Verification Pay Off? A Closer Look at LLMs as Solution Verifiers". 🔍 37 models, 9 datasets 🔥 Self vs intra-family vs cross-family verification Result: verify across families! 🧵👇
English
Check out our new work on test-time adaptation!
Jack Lu@Jacklu_me
ICL is powerful, but only if LLMs actually understand their contexts. Let’s optimize the KV-cache itself for few-shot adaptation! Introducing Context Tuning: 📎 Initialize prefixes from examples ⚙️ Optimize them via gradient descent 🚀 Unlock strong, efficient adaptation 🧵👇
English