
Samuel Chen
9 posts

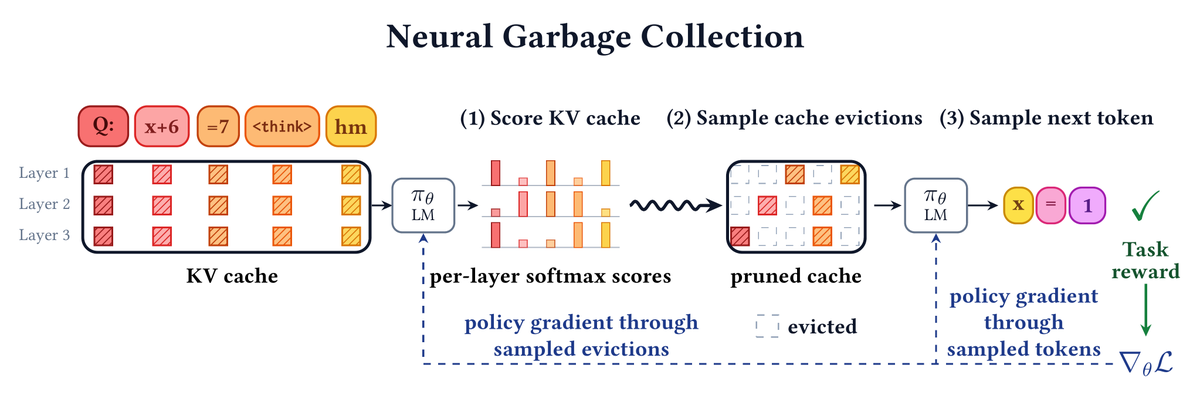
Can a language model learn, end-to-end, what to keep in its own KV cache and what to throw away? Can it learn to forget while it learns to reason?
Deep learning's central lesson: capability emerges from end-to-end optimization, not heuristics/strong inductive biases. But for efficiency, we rely heavily on hand-designed approaches.
🗑️ Introducing Neural Garbage Collection (NGC): we train a language model to jointly reason and manage its own KV cache, using reinforcement learning with outcome-based task reward alone. No SFT, no proxy objectives, no summarization in natural language.
New paper with @jubayer_hamid, Emily Fox, and @noahdgoodman!
English
@Andercot yes Islands of Stability, but we should probably also secure the Twin Peaks of unstable isotopes that hospitals need

English

We should consider immediately negotiating for the purchase of the Islands of Stability to safeguard the West's future need of stable isotopes.
Thank you for your attention to this matter
English

Introducing NousCoder-14b, a competitive olympiad programming model.
Our latest blog details the full findings from extensive experiments and logs with the full stack released - the RL environment, benchmark, and harness built in Atropos, all fully reproducible with our open training stack.
NousCoder-14b was post-trained on Qwen3-14B by researcher in residence @JoeLi5050 using 48 B200s over the course of 4 days, our Atropos framework, and @modal's autoscaler. It achieves a Pass@1 accuracy of 67.87%,+7.08% over Qwen's baseline accuracy using verifiable execution rewards.

English




@samchenn_ sam i saw this tweet and thought it came from a very credible x user
good work
English
Same batch as Chad IDE btw. Glad there’s still smart people focused on innovation instead of launch videos

English
