
Peter Ince
604 posts

Peter Ince
@satoriweb
Researcher and harness mechanic @cenva_intel, PhD on AI/LLMs for Smart Contract Security.
Melbourne, Victoria Katılım Temmuz 2012
3.4K Takip Edilen440 Takipçiler
@jxnlco Codex: Search "What humans do with computers" then save output as csv. Next /goal Make hyper-real visual demo for everything on human-economy.csv - make no mistakes
English

OpenAI needs some Aussie (located) staff so @thsottiaux et al don't have to get paged in the middle of the night when the servers melt lol.
English
I think the codex servers melted, getting this error every few turns through opencode {"type":"error","sequence_number":4,"error":{"type":"server_error","code":"server_error","message":"An error occurred while processing your request. You can retry your request, or contact us through our help center at help.openai.com ..."}.
English

Come try Kimi K2.6 in Hermes Agent for FREE for 24 hours.
Update Hermes and select Nous Portal in `hermes model` to access now.
Nous Research@NousResearch
Kimi K2.6 is free on Nous Portal for the next 24 hours Made possible by @vercel's AI Gateway & @Kimi_Moonshot Run 'hermes update', then 'hermes model' and select Kimi K2.6 to try out one of the most impressive open model releases ever
English
Everyone from codex is asleep I assume, but getting frequent server overloaded errors for gpt5.4. Anyone else?
English

@thsottiaux will be hitting the reset button every 0.27 seconds
Daniel McAuley@_dmca
wow at this rate we will have 13 trillion users by the end of 2027
English
@BoyuanChen0 So good! The text gen, even on text heavy images is impeccable.
English

This is what I’ve been cooking in the past 4 months . GPT Image 2 is over a massive 240 elo jump over the second place model, marking the biggest jump bigger than the rest of the leaderboard combined
Arena.ai@arena
Exciting news - GPT-Image-2 by @OpenAI has claimed the #1 spot across all Image Arena leaderboards! A clean sweep with a record-breaking +242 point lead in Text-to-Image - the largest gap we’ve seen to date. - #1 Text-to-Image (1512), +242 over #2 (Nano-banana-2 with web-search aka gemini-3.1-flash-image) - #1 Single-Image Edit (1513), +125 over #2 (Nano-banana-pro aka gemini-3-pro-image) - #1 Multi-Image Edit (1464), +90 over #2 (Nano-banana-2) No model has dominated Image Arena with margins this wide. Huge congratulations to @OpenAI on this major breakthrough in image generation! More performance breakdowns by category in the thread below.
English
@Teknium It's super good in practice also, just a bit slow at the moment. It is much more capable of working through issues on its own without coming back to ask questions.
English
Kimi 2.6 looks like it could be the new contender for best open agentic model for Hermes Agent, stacking up strongly against even opus 4.6 in these agentic benchmarks 😲
Kimi.ai@Kimi_Moonshot
Meet Kimi K2.6: Advancing Open-Source Coding 🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2) What's new: 🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization). 🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D. 🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files. 🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops. 🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop. - K2.6 is now live on kimi.com in chat mode and agent mode. For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blog/kimi-k2-6 🔗 Weights & code: huggingface.co/moonshotai/Kim…
English

We’re launching Kimi K2.6 on Fireworks as a Day-0 launch partner!
K2.5 was the base for standout models like @Cursor’s Composer 2 and was the most popular model on our training platform. K2.6 on Fireworks raises the bar again.
→ Optimized across the stack, from custom speculators to heterogeneous hardware support across @Nvidia and @AMD.
→ Day-0 serverless support, and coming soon to Fire Pass (stay tuned).
→ Unlock new use cases with capabilities for 12+ hour autonomous runs and 4,000+ tool calls.
→ $0.95 input / $4.00 output per 1M tok
Get started today → fireworks.ai/models/firewor…

English
Any chance we can get Pro in codex? :) Although ideally not taking away from the normal mode usage, like a separate spark-esque usage bar. @thsottiaux @jxnlco love your work!
English
@Teknium @dadhalfdev @NousResearch Wasn’t about Hermes’ agent, but this interview is great youtu.be/8pUKjOTR9ns?si…

YouTube
English
@dadhalfdev @NousResearch I dont do podcasts or interviews I have all the rest of my peoples go on them I stay anon online x]
English

The Hermes Agent is a truly impressive piece of engineering.
I dissected its memory architecture and it's definitely better than mine 😅
Amazing work @Teknium and @NousResearch team.
When on Lex Fridman podcast? It's about time.
x.com/i/status/20443…
Marco Rodrigues@dadhalfdev
English
@realCoinAPI am having issues with auth to your apibricks.io and flatfile api. but the status page says everything is good, is it just me?
English
The only problem with the pace of change and how amazing it is to build right now, is I should be spend most of my time raising but I am having too much fun building the next thing.
English
@JohnThilen that works as well! As long as the request -> payment -> access is through the LLM interface. It seems like it finds the product, I go talk to their AI interface, it creates a stripe link, I pay, give api details to model. Too many steps!
English

@satoriweb I would prefer if it had to make a business case for why the payment is necessary.
English
Would be great to have a payment system for agents that operates like a child credit card, it gets approval for a spend or sub, you approve, and then sorts out the rest of the details with the provider. Stripe is in a great position for this, they own the payment rails for many.
English
Did codex change the response shape? As it's failing in the @NousResearch Hermes harness at the moment and it looks like the cause different stream expectation. Only happens using codex auth, not using gpt5.4 in open router.
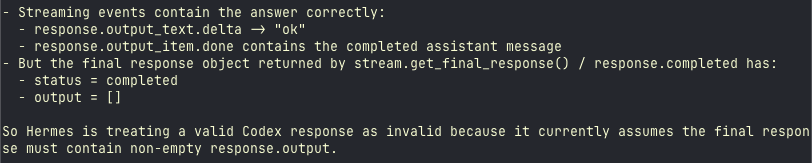
English
It turns out it was causing an issue in auxillary compression as well - here's the summary to fix it quick -
Compression has a separate Codex Responses API bug in agent/auxiliary_client.py. The auxiliary Codex adapter streams the response but previously ignored stream events and only read final.output; Codex can now return response.completed with output=[] even when the real answer arrived in response.output_item.done / response.output_text.delta. This makes compression summaries come back empty (message.content=None). Fix by capturing streamed output items/text in _CodexCompletionsAdapter.create(), backfilling a minimal response when final.output is empty, normalizing dict-shaped streamed items, and avoiding plain-text synthesis if function_call events were streamed.
English
@satoriweb Yea it was super weird how it just changed under our feet like that lol but it should be fixed in main now
English
@Teknium Amazing! Thanks Tek! Yeah, there was no announcement or docs, afaik the latest update to the endpoints for codex was to support openclaw better, so might have been an unintended breaking change.
English