Scale AI retweetledi

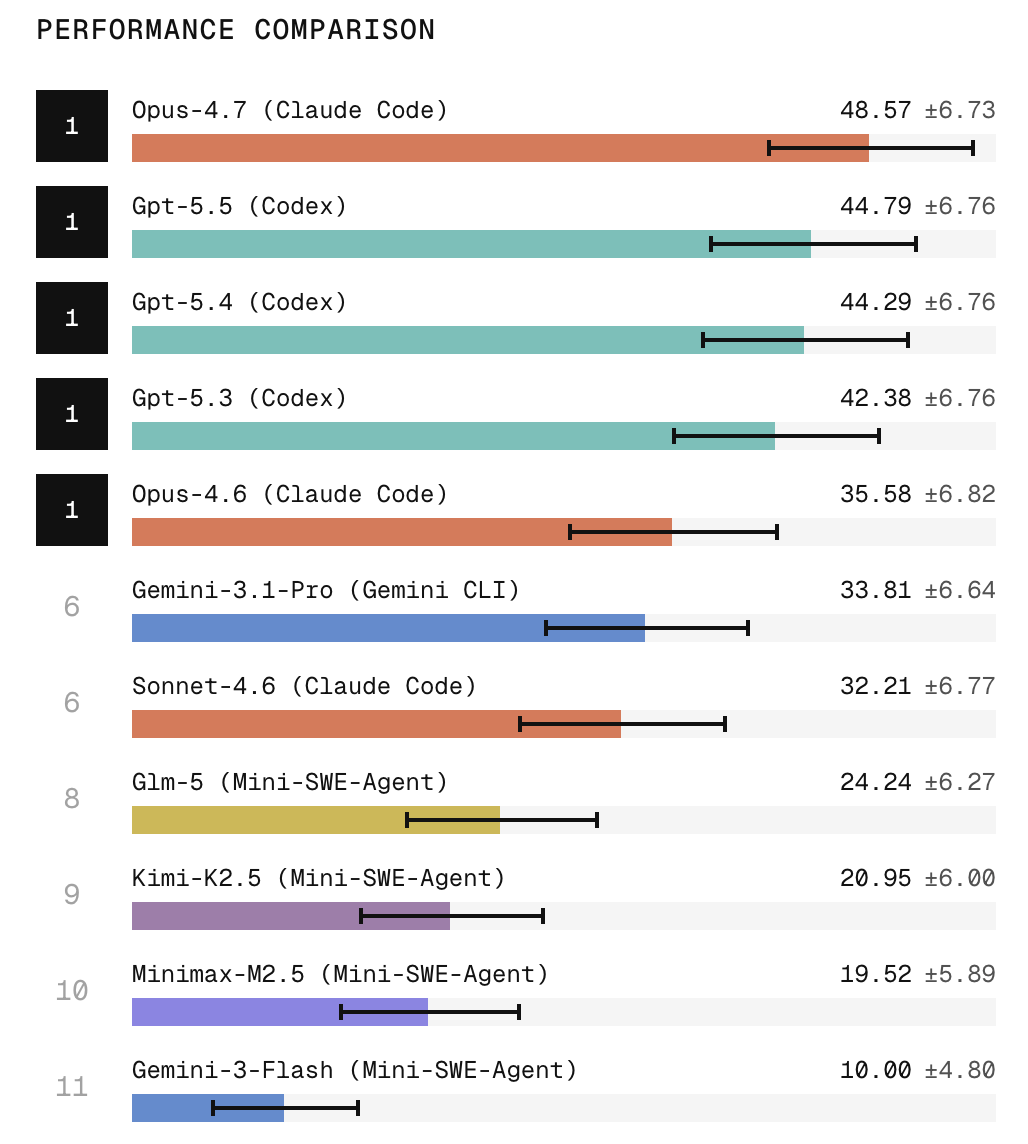
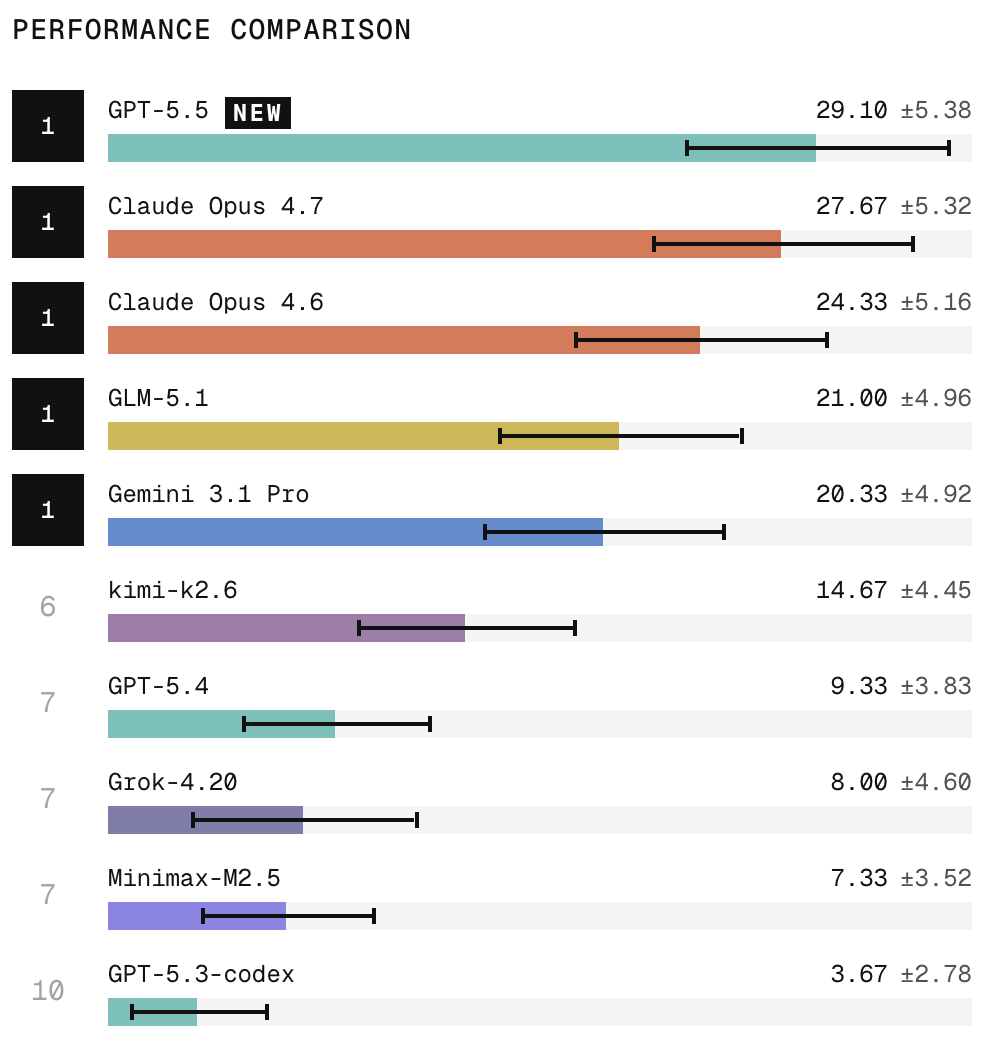
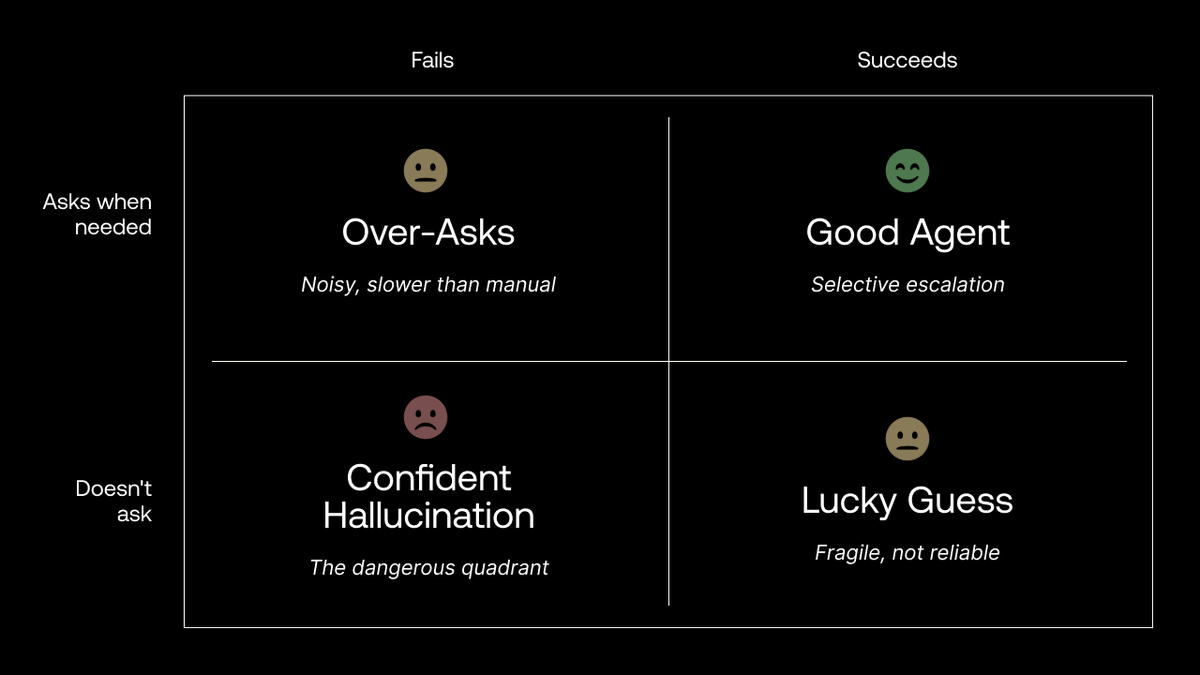
We appreciate the community's feedback on SWE-Bench Pro.
Much of it maps to changes already underway in v1.1, which we've been building for a while. Keeping evals current with frontier models is hard, and we're always iterating.
SWE-Bench Pro Verified coming soon. 👀
English