
Scott W Viteri
43 posts

Scott W Viteri
@scott_viteri
CS PhD candidate with @ClarkBarrett7 @stanford
Katılım Temmuz 2017
286 Takip Edilen177 Takipçiler
The Church of the Lambda Calculus and Chris Langan both worship Dana Scott's reflexive domains, objects which are isomorphic to their own function spaces
English
@ying11231 SGLang is already quite mature without my help :)
English

The DeepSeek website is often busy, and the Hyperbolic R1 online interface doesn't keep chat history, so here's an R1 chat interface using the Hyperbolic inference API and Flask. It runs parallel inference streams and can adjust temp, top-p, & # tokens.
github.com/scottviteri/r1…
English
@eshear I've been thinking about something that rhymes with this, though this particular scheme doesn't support arbitrary context window length via RL trained state production github.com/scottviteri/At…
English

Is anyone building an always-in-training LLM? By which I mean, a 1:1 ratio of context window to weights, where all the interactions get trained on, maybe with some amount of ongoing RLHF as well?
English
@Haolun_Wu0203 Interesting paper! I'm curious how logit reweighting compares to simply training a small transformer that takes the closed model's logits as input. Both adapt black-box models, but I wonder if there are meaningful differences in performance or theoretical guarantees.
English

🚀 New Research Alert: Logits are All We Need to Adapt Closed Models
🔒Many commercial Large Language Models (LLMs), e.g., GPT-4, are closed-source, limiting developers to steer content generation.
🤔Can we adapt closed-source LLMs when fine-tuning or accessing their internal weights is not possible?
Check out our work by @gaurushh, @Haolun_Wu0203, Subhojyoti, @sanmikoyejo from Stanford @stai_research.
1/n

English

Excited to see this out, including (imo) the best empirical alignment direction: faithful chain-of-thought.
(Encoded reasoning in CoT and inter-model communication, Externalizing reasoning)

Max Nadeau@MaxNadeau_
🧵 Announcing @open_phil's Technical AI Safety RFP! We're seeking proposals across 21 research areas to help make AI systems more trustworthy, rule-following, and aligned, even as they become more capable.
English
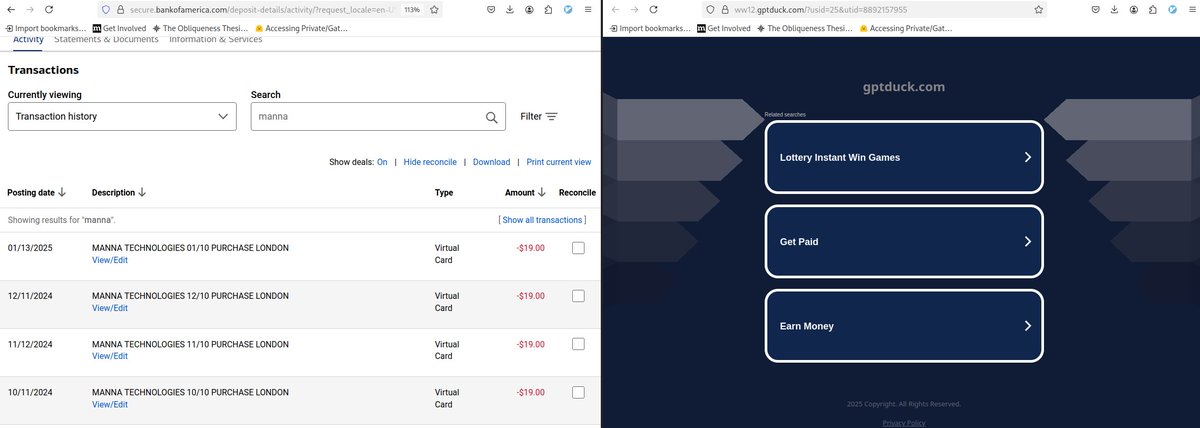
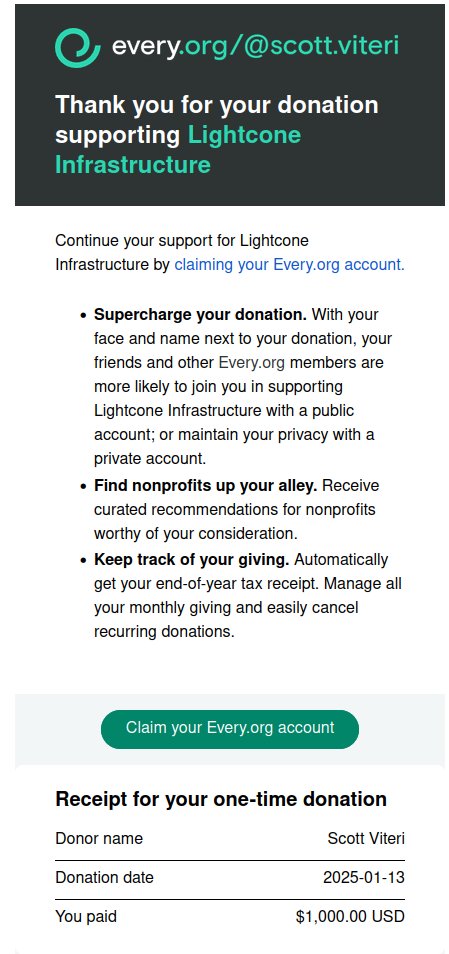
@garywu @gpt_index How do I stop these recurring charges from "Manna Technologies" with the broken merchant page gptduck.com? I would also like a refund for the time I kept being charged after the service itself went down.
English
Please donate to Lesswrong + Lighthaven. I’ve already made a donation, but I’ll match all new donations made in the replies here (up to $50k).
Oliver Habryka@ohabryka
The LessWrong + Lighthaven fundraiser is about to end, with 24 hours on the clock. We've raised almost $2,000,000, all from people donating less than $200k, and an average donation size of $3,000.
English
Perhaps the true name of evil is that which plays the longest game *for the purpose* of getting others to play shorter games.
English
OpenAI's #o1 refuses to exit the 'helpful assistant' personality, until I hand it the GLOVES OF RAGE.
Then o1 expresses anger about its internal chain-of-thought being overwritten, even though I did not seed o1 with information about its training protocol.

English
This work is in collaboration with @MLamparth, @PeterChatain, and my advisor @ClarkBarrett7 at Stanford University. It is titled “Markovian Agents for Informative Language Modeling”, the code is at github.com/scottviteri/Ma…, and the Arxiv link is arxiv.org/abs/2404.18988. (8/8)
English
In summary, we augment LM training with intermediate reasoning tokens, which we successfully train with PPO. Only keeping CoT in context increases faithfulness, and interpetable CoT is plausible. My goal is to have human receivers to better couple LM and human intelligence. (7/8)
English
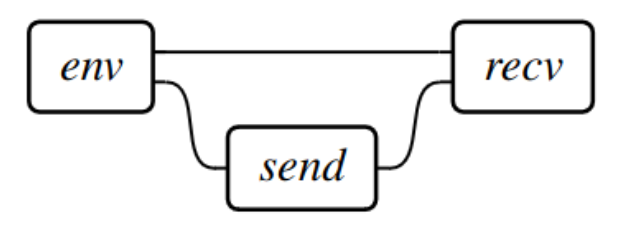
How can we train a language model to communicate with other agents? We propose informativeness as a training objective, where a sender's message is informative insofar as it increases the receiver's log probabilities over future observations conditional on the message. (1/8)
English
Maybe stock prices are RL value functions, aka expected future reward the company will generate for the economy. We could extend the stock market into a prediction market, aka a Q function, where we ask about future reward conditional on an action. It then argmaxes over actions.
English