Sebastian Lehner retweetledi
Sebastian Lehner
127 posts


Sebastian Lehner
@sebaLeh
Machine learner at @jkulinz
Linz, Österreich Katılım Ocak 2017
546 Takip Edilen267 Takipçiler


@gklambauer Calling this naming choice "bad" is quite generous of you!
English
Sebastian Lehner retweetledi

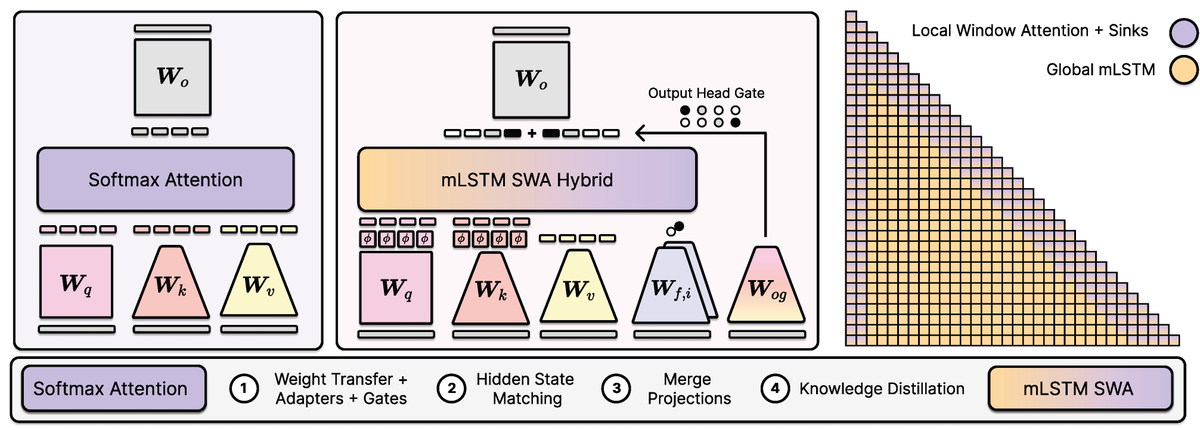
Excited to share our new paper: Effective Distillation to Hybrid xLSTM Architectures.
TL;DR: we retrofit / graft / distill / linearize Transformers into xLSTM-SWA hybrids with fixed-size states.
This gives a practical path to studying linear and hybrid architectures starting from already strong pretrained models.
Sepp Hochreiter@HochreiterSepp
xLSTM Distillation: arxiv.org/abs/2603.15590 Near-lossless distillation of quadratic Transformer LLMs into linear xLSTM architectures enables cost- and energy-efficient alternatives without sacrificing performance. xLSTM variants of instruction-tuned Llama, Qwen, & Olmo models.
English
Sebastian Lehner retweetledi

xLSTM Distillation: arxiv.org/abs/2603.15590
Near-lossless distillation of quadratic Transformer LLMs into linear xLSTM architectures enables cost- and energy-efficient alternatives without sacrificing performance.
xLSTM variants of instruction-tuned Llama, Qwen, & Olmo models.
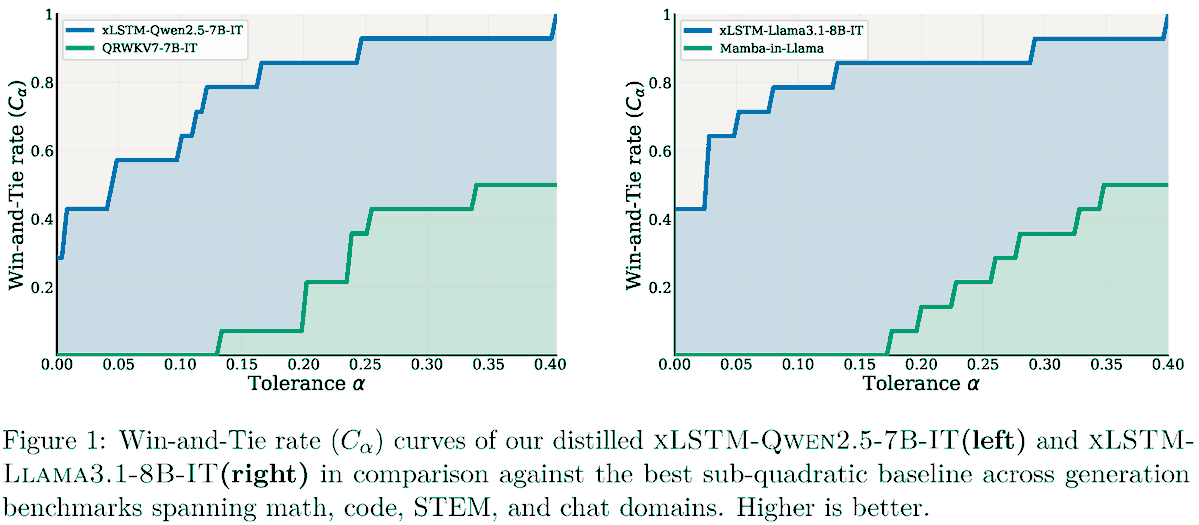
English
Sebastian Lehner retweetledi

FIRST CONVERSATION WITH INSTRUCTION-TUNED XLSTM FEELS LIKE A BIG BREAKTHROUGH
P: arxiv.org/abs/2603.15590

English
Sebastian Lehner retweetledi

We extend stochastic interpolants to the setting where no data samples are available - only an unnormalized density.
Our non-Markovian approach generalizes adjoint sampling and scales to targets in dimension 2500.
Paper: arxiv.org/pdf/2603.00530
Talk: youtube.com/watch?v=mpBLax…
YouTube
English
Sebastian Lehner retweetledi
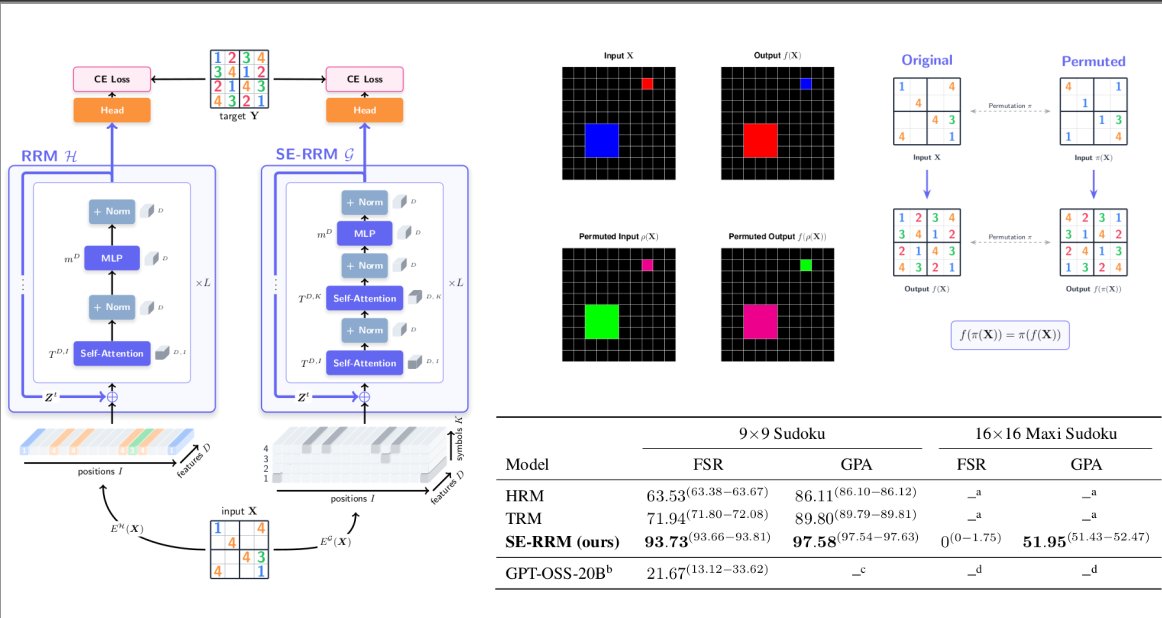
Symbol-equivariant Recurrent Reasoning Models (SE-RRM)
SE-RRM advances HRM and TRM -- guaranteed identical solutions for problems with permuted colors (ARC AGI) or digits (Sudoku).
Coolest part: extrapolation to larger problem sizes!!!
P: arxiv.org/abs/2603.02193
English
Sebastian Lehner retweetledi

Let’s formally introduce FEAT (Free Energy Estimator with Adaptive Transport).
[1/N]✨FEAT accelerates free-energy estimation by a learned non-equilibrium dynamics, enabling low-variance estimators based on the escorted Jarzynski equality and Crooks fluctuation theorem.
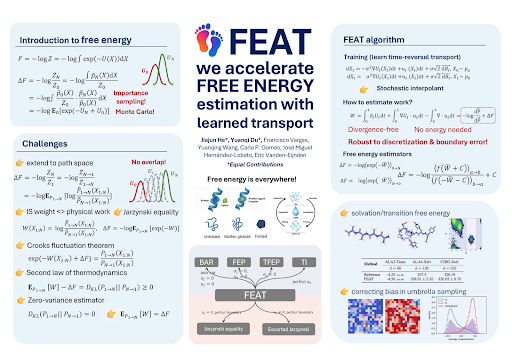
English
Sebastian Lehner retweetledi

The recent Drifting Models paper from Kaiming's group got very hyped over the past few days as a new generative modeling paradigm, but in fact, it can actually be seen as a scaled-up/generalized version of the good old GMMN from 2015 (and the authors themselves acknowledge this in the paper in Appendix C.2, noting that GMMN can be seen as Drifting Models for a particular choice of the kernel). Also, I am very skeptical about its scalability (for higher diversity / higher resolution datasets, larger models, and videos).
The way Drifting Models work is actually very simple:
- 1. Sample random noise z ~ N(0, I)
- 2. Feed it to the generator and get a fake sample x' = G(z)
- 3. For each fake sample x', compute its similarity (in the feature space of some encoder) to each of the real samples x_i from the current batch.
- 4. Push it closer toward these real samples using the similarities as weights (i.e. so that we push to the nearest ones the most).
- 5. To make sure that we don't have any sort of mode collapse, repel each fake sample from other fake samples via the same scheme.
- 6. Profit
Now, GMMN follows exactly the same scheme, with the only difference being that it uses a different (unnormalized) function in the "distance computation" and doesn't allow for cleanly plugging in normalization/scaling in the similarity scores or CFG.
Why didn't GMMN take off and why am I skeptical about Drifting Models? The issue is that it makes it much harder to compute any meaningful similarity when your dataset gets more diverse (happens when you switch to foundational T2I/T2V model training), or the batch size gets smaller (happens when your model size or training resolution increases), or your feature encoder produces less comparable representations (happens for videos or more diverse datasets). You can sure get informative similarities for 4096 batch size on the object-centric, limited diversity ImageNet with ResNet-50 feature encoder, but for smth like video generation, we train on hundreds of millions of videos or, at high resolutions + larger model sizes, with a batch size of 1 per GPU (not sure if will be fast to do inter-GPU distance computations).
From the theoretical perspective, even though the final objective and the practical training scheme are the same, the mathematical machinery to formulate the framework is very different and enables direct access to the drifting field (e.g., to easily enable CFG which the authors already did). But I guess what I like the most about this paper is that Kaiming's group is boldly pushing against the mainstream ideas of the community, and hopefully it will inspire others to also take a look at the fundamentals and stop cargo-culting diffusion models.
Alexia Jolicoeur-Martineau@jm_alexia
Byebye diffusion, say hello to Drifting models. Drifting models will take over diffusion models within the next year. I was told many times that we figured it all out, that there was nothing else to invent in generative AI and it was just about scaling. Wrong again and again.
English
Sebastian Lehner retweetledi

“Parallelizing MCMC Across the Sequence Length”: This one is really cool.
statmodeling.stat.columbia.edu/2026/02/03/par…
English
Sebastian Lehner retweetledi

I am happy to announce that 2 papers with xLSTM are accepted at ICLR 2026!
📉xLSTM Scaling Laws: Competitive Performance with Linear Time-Complexity arxiv.org/abs/2510.02228
AND
⌛️Short window attention enables long-term memorization
arxiv.org/abs/2509.24552
Maximilian Beck@maxmbeck
🚀 Excited to share our new paper on scaling laws for xLSTMs vs. Transformers. Key result: xLSTM models Pareto-dominate Transformers in cross-entropy loss. - At fixed FLOP budgets → xLSTMs perform better - At fixed validation loss → xLSTMs need fewer FLOPs 🧵 Details in thread
English
Sebastian Lehner retweetledi
🏆 MolecularIQ is live — and open to the community
👉 Check how current LLMs perform on real molecular structure reasoning
👉 Submit your own chemistry LLM and get evaluated under a standardized protocol
🔗 Leaderboard & submissions:
huggingface.co/spaces/ml-jku/…
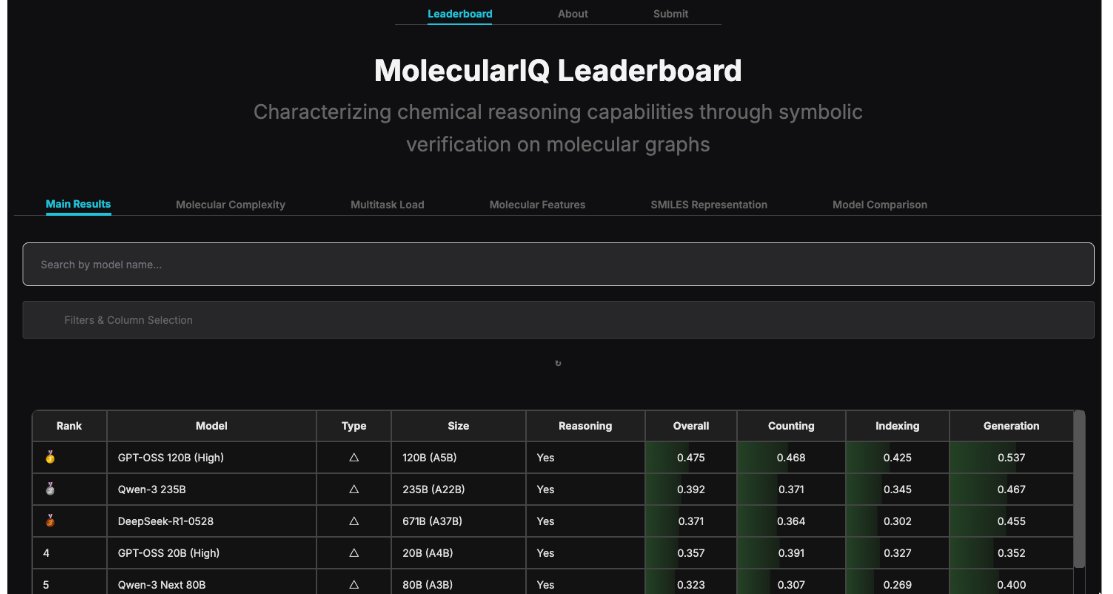
English
Sebastian Lehner retweetledi

🧪🧠 Do LLMs actually understand molecular structure?
📄 Paper: arxiv.org/pdf/2601.15279
🏆 Live leaderboard: huggingface.co/spaces/ml-jku/…
Introducing MolecularIQ — a benchmark designed to test real molecular understanding (not memorization).
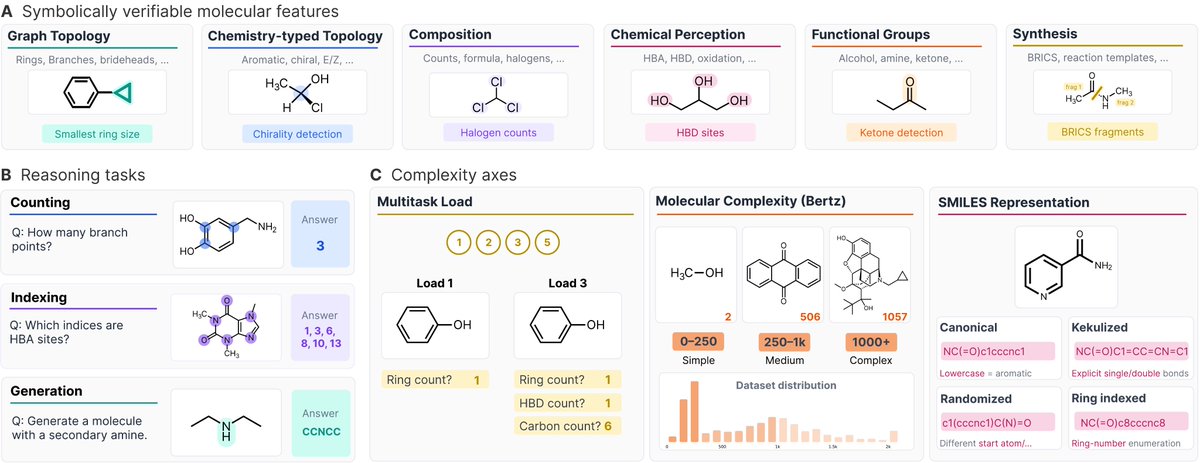
English
Sebastian Lehner retweetledi
# AI in Drug discovery just BROKE THROUGH a wall #
A newer AI model, ConGLUDe, as fast but much more accurate than DrugCLIP.
Instead on just 40K structure-based data, ConGLUDe is trained on 100M datapoints from ligand-based data
P: arxiv.org/abs/2601.09693

SciTech Era@SciTechera
BIG BREAKTHOUGH: A new AI tool could dramatically speed up the discovery of life saving medicines. Researchers at Tsinghua University created a new system called DrugCLIP, that can screen drug molecules against human proteins at a speed that makes traditional methods look ancient. > DrugCLIP uses deep contrastive learning to turn both molecules and protein binding pockets into vectors and match them almost instantly. > It screened 500 million molecules across 10,000 human proteins, covering half of the entire human druggable proteome. > The system completed 10 trillion molecule protein evaluations in a single day, roughly 10 million times faster than classic docking simulations. > They used AlphaFold2 to generate protein structures and then refined binding pockets with a custom tool called GenPack. > The model even identified compounds for TRIP12, a protein linked to cancer and autism that has resisted traditional drug-targeting approaches. All data and models are open access, so labs worldwide can now speed up early stage drug discovery.
English
Sebastian Lehner retweetledi

@arpitrage Double descent just means one did something suboptimal at fewer parameters. If one does the optimal regularization at all parameters double descent goes away. See eg: proceedings.mlr.press/v139/mel21a.ht…
English
Sebastian Lehner retweetledi

Proponents of diffusion language models tout their ability to generate many tokens in parallel. Skeptics argue this is fundamentally broken as it ignores token dependencies. Who's right? 🤔🤔🤔
🚀 In a new work, we rigorously prove that the picture is a lot more nuanced... 1/

English
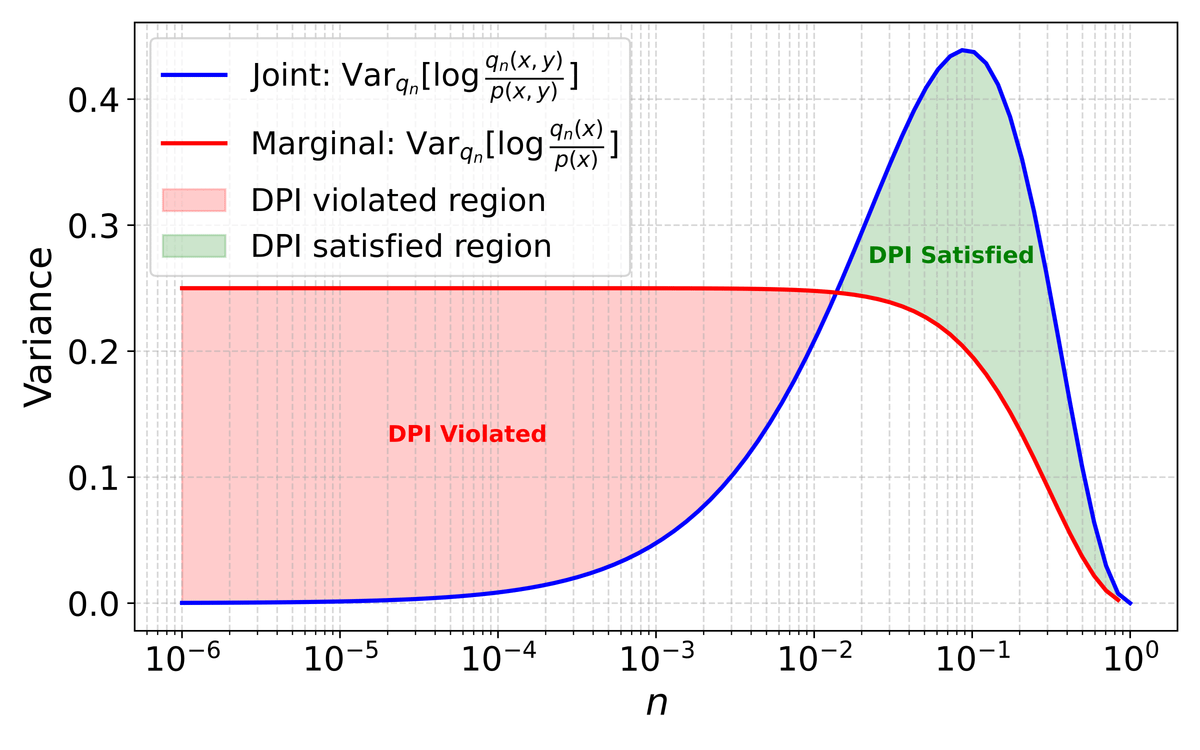
Diffusion bridge samplers are an elegant idea—but only with the right loss.
We show that the Data Processing Inequality (DPI) plays a crucial role in the choice of loss functions for these samplers. Check out our poster at #NeurIPS
Sebastian@SebSanokowski
Ever experienced instabilities when using the popular LV (Log Variance) loss for training Diffusion Bridge Samplers?
English
Sebastian Lehner retweetledi

Sebastian Lehner retweetledi

1/2) I am very happy to finally share something I have been working on and off for the past year:
"The Information Dynamics of Generative Diffusion"
This paper connects the entropy production, divergence of vector fields and spontaneous symmetry breaking in a unified framework

English