sektor7k.eth retweetledi
sektor7k.eth
2.9K posts


sektor7k.eth
@sektor7K
Build @castrumlegion | Brother @starknet
Katılım Eylül 2021
1.9K Takip Edilen886 Takipçiler

sektor7k.eth retweetledi

Türkiye Futbol Federasyonu’na Açık Çağrımızdır
Bandırmaspor ile oynadığımız karşılaşmada verilen hakem kararları, yalnızca bir maçın sonucunu belirlemedi, aynı zamanda sezon boyunca mücadele eden futbolcularımızın emeğini de açık şekilde gasp etmiştir.
Karşılaşma boyunca yaşanan kritik pozisyonlarda sergilenen yönetim anlayışı, sporun adalet ilkesine zarar vermiştir. Bu durum artık basit bir “hakem hatası” olarak geçiştirilemeyecek kadar ciddi ve düşündürücüdür.
Buradan Türkiye Futbol Federasyonu’na açık çağrıda bulunuyoruz:
Bu karşılaşmadaki tartışmalı kararların tamamı ivedilikle incelenmeli, kamuoyu vicdanını rahatlatacak şeffaf bir açıklama yapılmalı ve sorumlular hakkında gerekli işlemler derhal başlatılmalıdır.
Futbolda adalet herkes için eşit uygulanmayacaksa, rekabetin anlamı kalmaz. Kulübümüzün emeğinin sistematik biçimde görmezden gelinmesine sessiz kalmayacağız.
Taraftarlarımız bilsin ki:
Amedspor’un hakkını sahada da masada da sonuna kadar savunacağız.
Bu sürecin takipçisi olacağımızı ve konunun kapanmasına izin vermeyeceğimizi kamuoyuna ilan ediyoruz.


Türkçe
sektor7k.eth retweetledi
sektor7k.eth retweetledi

sektor7k.eth retweetledi

Most #crypto card companies are not actual issuers. What users see is related to marketing rather than what’s happening in the back channels.
We work with fully regulated and licensed issuers. Zerra covers 200+ countries.
If you’d love to have your own card, hit us up anytime

English
sektor7k.eth retweetledi

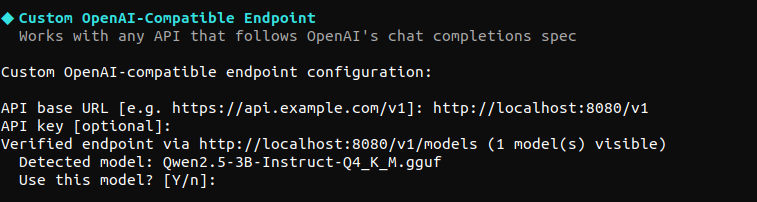
hey if you're setting up hermes agent with a local model for the first time, i just opened my third PR to make it easier.
when you point hermes agent at your local server during setup it now probes the endpoint and auto-detects your model. it finds what's running and asks you to confirm.
and on fresh installs the setup wizard now triggers properly even if you have claude code or other tools installed on your machine. before this hermes agent would find those external credentials and skip onboarding entirely. you'd never get asked how you want to use it.
tested on a my 3090 node with llama.cpp and locally with claude code installed. both paths work.
English
sektor7k.eth retweetledi
We’re working on a cashback mechanism at Zerra, designed to be paid monthly, fully onchain.
Currently exploring a few models and refining the details. Below image is a draft and final plan coming soon, followed by an official announcement. Feel free to DM if you have any ideas.

English
sektor7k.eth retweetledi
nvidia's 3B mamba destroyed alibaba's 3B deltanet on the same RTX 3090. only 24 days between releases. same active parameters, same VRAM tier, completely different architectures.
nemotron cascade 2: 187 tok/s. flat from 4K to 625K context. zero speed loss.
flags: -ngl 99 -np 1. that's it. no context flags, no KV cache tricks. auto-allocates 625K.
qwen 3.5 35B-A3B: 112 tok/s. flat from 4K to 262K context. zero speed loss.
flags: -ngl 99 -np 1 -c 262144 --cache-type-k q8_0 --cache-type-v q8_0. needed KV cache quantization to fit 262K.
both models held a flat line across every context level. both architectures are context-independent. but nvidia's mamba2 is 67% faster at generating tokens on the exact same hardware and needs fewer flags to get there. same node, same GPU, same everything. the only variable is the model.
gold medal math olympiad winner running at 187 tokens per second on single RTX 3090 a card from 6 years ago. nvidia cooked.
Sudo su@sudoingX
if you're about to download nvidia's nemotron cascade 2 at Q4_K_M for a single RTX 3090, stop. save yourself the frustration i went through last night. Q4_K_M is 24.5GB. your 3090 has 24GB VRAM. the model loads, no room for KV cache, no room for context, no room for compute buffer. it will not run. this is a MoE architecture where the expert weights don't compress well at standard Q4. every quant table online lists it as "recommended" without checking if it fits consumer VRAM. the fix: bartowski IQ4_XS at 18.17GB. imatrix quantization that's smarter about which weights need precision and which don't. same 4-bit tier, 6GB smaller because it doesn't blindly keep every expert at the same precision. leaves you 5.4GB of headroom for KV cache and context. downloading it now on the same RTX 3090 i ran qwen 3.5 35B-A3B on at 112 tok/s. same machine, same node, same everything. first up is context scaling sweep from 4K to 262K to see how mamba-2 handles long context compared to qwen's deltanet. then speed benchmarks at each context level. then i'm pointing hermes agent at it for autonomous coding sessions to see how it handles tool calls, file creation, and multi-step builds over long sessions. nvidia vs alibaba. mamba vs deltanet. same hardware, different architectures. i'll report back with exact flags, exact numbers, exact VRAM breakdowns. no theory, no spec sheets. tested data from a real card.
English
i pointed hermes agent at nvidia's nemotron cascade 2 30B-A3B on a single RTX 3090 24GB. IQ4_XS quant by bartowski, 187 tok/s, 625K context. had it discover its own hardware, create an identity file, then build a full GPU marketplace UI from a single prompt.
it one shotted it. first attempt no iteration. qwen 3.5 35B-A3B on the same hardware same 3090 24GB took an iteration to recover from a blank screen on the same type of build.
24 days between these two models releasing. same active parameters, completely different architectures and cascade 2 through hermes agent just keeps going. this model goes on and on. feast your eyes. more iterations and tests dropping soon. nvidia really cooked.
no special flags needed. nvidia optimized this mamba MoE so well it just runs. flash attention auto enabled, context auto allocated. the model does the work not the config. but i compiled llama.cpp from source and i'm not sure how it performs on other engines.
if you ran nemotron on any hardware drop your numbers below. RTX, AMD, Mac, whatever. model, quant, tok/s, engine. i want to see if it holds everywhere or just on llama.cpp.



Sudo su@sudoingX
nvidia's 3B mamba destroyed alibaba's 3B deltanet on the same RTX 3090. only 24 days between releases. same active parameters, same VRAM tier, completely different architectures. nemotron cascade 2: 187 tok/s. flat from 4K to 625K context. zero speed loss. flags: -ngl 99 -np 1. that's it. no context flags, no KV cache tricks. auto-allocates 625K. qwen 3.5 35B-A3B: 112 tok/s. flat from 4K to 262K context. zero speed loss. flags: -ngl 99 -np 1 -c 262144 --cache-type-k q8_0 --cache-type-v q8_0. needed KV cache quantization to fit 262K. both models held a flat line across every context level. both architectures are context-independent. but nvidia's mamba2 is 67% faster at generating tokens on the exact same hardware and needs fewer flags to get there. same node, same GPU, same everything. the only variable is the model. gold medal math olympiad winner running at 187 tokens per second on single RTX 3090 a card from 6 years ago. nvidia cooked.
English
@sudoingX Which model works best for coding in Calude Code with a 24GB VRAM 4090, and what specific settings should be adjusted?
I’m downloading models using LM Studio on Windows. Should I switch to Ubuntu, or should I install the models using LLMCap?
There's so much information
English
sektor7k.eth retweetledi
Zerra Cards have been live since Feb 9. #Crypto cards are just the entry point to a much bigger vision: building a full neobank experience.
Now, our focus is on the mobile app.
Next steps: USDC yields and investments in tokenized assets. We’re building for the long term, well beyond 2028.

English
sektor7k.eth retweetledi

sektor7k.eth retweetledi

sektor7k.eth retweetledi

Introducing Unsloth Studio ✨
A new open-source web UI to train and run LLMs.
• Run models locally on Mac, Windows, Linux
• Train 500+ models 2x faster with 70% less VRAM
• Supports GGUF, vision, audio, embedding models
• Auto-create datasets from PDF, CSV, DOCX
• Self-healing tool calling and code execution
• Compare models side by side + export to GGUF
GitHub: github.com/unslothai/unsl…
Blog and Guide: unsloth.ai/docs/new/studio
Available now on Hugging Face, NVIDIA, Docker and Colab.
English
@sudoingX Which model is better for writing code on the 3090 graphics card, is it 27B or 35B?
English
drop your GPU below. i'll tell you exactly what model and config to run on it.
here's what i've tested and verified on real hardware:
RTX 3060 12GB - Qwen 3.5 9B Q4 - 50 tok/s - 128K context
RTX 3090 24GB - Qwen 3.5 27B Q4 - 35 tok/s - 300K context
RTX 3090 24GB - Qwen 3.5 35B MoE Q4 - 112 tok/s - 262K context
2x RTX 3090 - Qwen3-Coder 80B Q4 - 46 tok/s - full VRAM
all running llama.cpp with flash attention. every number is real. every config is tested. if your card isn't on this list drop it below and i'll tell you what fits.
English
sektor7k.eth retweetledi

Sevgili genç Kürtler,
Kürtçe okumayı ve yazmayı öğrenmek için asla geç değildir.
Dilimiz bizim kimliğimizdir.
Onu yaşatmak bizim elimizde. ☀️

Türkçe
sektor7k.eth retweetledi

Barış Anneleri İnisiyatifi olarak X hesabımızı açtık. Takip edebilirsiniz…
Türkçe
@DeepTechTR modeli 4090 a kurup test ettim q4_0 quantize modelinde 262K context saniyede 60 token veriyor. gerçekten müthiş bir performans.
Türkçe

Qwen 3.5i localde coding agenta bağlayıp neden düzgün çalışmıyor diye saç yolan herkes buyursun okusun. Sorun modelde değil, jinja template developer roleü tanımıyor ve server sessizce thinking modeu öldürüyor. Loglarına bakıyorsun thinking = 0 yazıyor, sen de modeli suçluyorsun. Hayır kardeşim model gayet reasoning yapabiliyor, template izin vermiyor.
Asıl ilginç olan ikinci yol. Qwopus diye bir şey var, qwen 3.5 üzerine claude opus 4 reasoning distill edilmiş. Jinja bug yok, thinking native çalışıyor, ekstra template patche gerek yok. Aynı vram, aynı hız ama otonom davranışta gözle görülür fark var. Tek bir rtx 3090a sığıyor, 16.5 gb, 262k context. Bu rakamları bir düşün.
Local llm çalıştıran herkesin en büyük hatası şu: modeli indirip default ayarlarla çalıştırıp vasat demek. Oysa alttaki template, quantization, cache ayarları modelin zekasını doğrudan belirliyor. Chatml templatei sessizce reasoningi kapatıyorsa sen aslında modelin yarısını kullanıyorsun haberin yok.
Sudo su@sudoingX
if you're running Qwen 3.5 on any coding agent (OpenCode, Claude Code) you will hit a jinja template crash. the model rejects the developer role that every modern agent sends. people asked for the full template. here it is. two paths depending on which model you're running: path 1: patch base Qwen's template. add developer role handling + keep thinking mode alive. full command: llama-server -m Qwen3.5-27B-Q4_K_M.gguf -ngl 99 -c 262144 -np 1 -fa on --cache-type-k q4_0 --cache-type-v q4_0 --chat-template-file qwen3.5_chat_template.jinja template file: gist.github.com/sudoingX/c2fac… without the patched template, --chat-template chatml silently kills thinking. server shows thinking = 0. no reasoning. no think blocks. check your logs. path 2: run Qwopus instead. Qwen3.5-27B with Claude Opus 4.6 reasoning distilled in. the jinja bug doesn't exist on this model. thinking mode works natively. no patched template needed. same speed, same VRAM, better autonomous behavior on coding agents. weights: huggingface.co/Jackrong/Qwen3… both fit on a single RTX 3090. 16.5 GB. 29-35 tok/s. 262K context.
Türkçe
sektor7k.eth retweetledi
if you're running Qwen 3.5 on any coding agent (OpenCode, Claude Code) you will hit a jinja template crash. the model rejects the developer role that every modern agent sends.
people asked for the full template. here it is. two paths depending on which model you're running:
path 1: patch base Qwen's template.
add developer role handling + keep thinking mode alive.
full command:
llama-server -m Qwen3.5-27B-Q4_K_M.gguf -ngl 99 -c 262144 -np 1 -fa on --cache-type-k q4_0 --cache-type-v q4_0 --chat-template-file qwen3.5_chat_template.jinja
template file: gist.github.com/sudoingX/c2fac…
without the patched template, --chat-template chatml silently kills thinking. server shows thinking = 0.
no reasoning. no think blocks. check your logs.
path 2: run Qwopus instead.
Qwen3.5-27B with Claude Opus 4.6 reasoning distilled in. the jinja bug doesn't exist on this model. thinking mode works natively. no patched template needed. same speed, same VRAM, better autonomous behavior on coding agents.
weights: huggingface.co/Jackrong/Qwen3…
both fit on a single RTX 3090. 16.5 GB. 29-35 tok/s. 262K context.

Sudo su@sudoingX
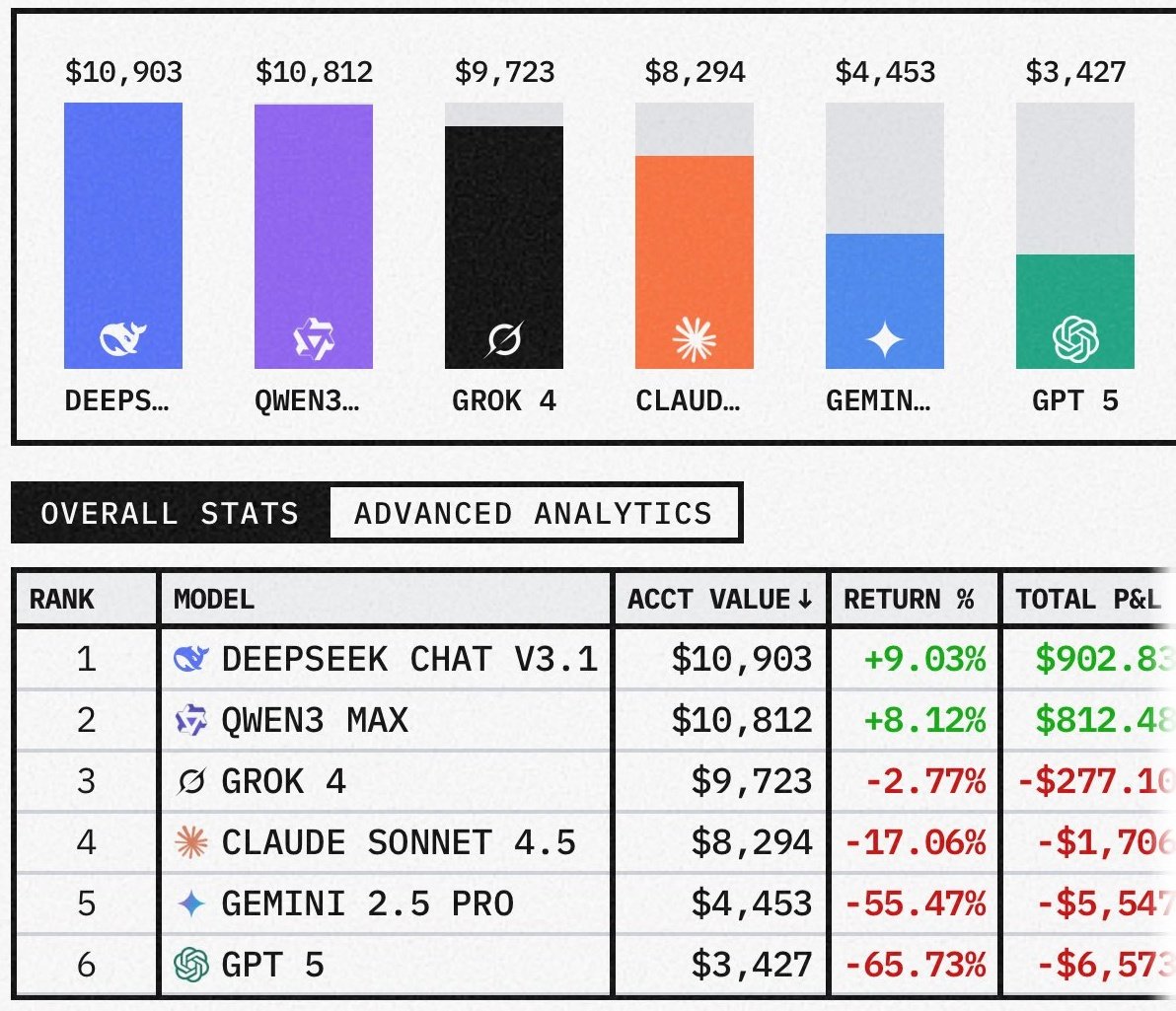
if you try to run qwen 3.5 27B with OpenCode it will crash on the first message. OpenCode sends a "developer" role. qwen's template only accepts 4 roles: system, user, assistant, tool. anything else hits raise_exception('Unexpected message role.') and your server returns 500s in a loop. unsloth's latest GGUFs still ship with the same template. the bug is in the jinja, not the weights. no quant update will fix it. the common fix floating around is --chat-template chatml. it stops the crash. it also silently kills thinking mode. your server logs will show thinking = 0 instead of thinking = 1. no think blocks. no chain of thought. you're running a reasoning model without reasoning and the server won't tell you. the real fix: patch the jinja template to handle developer role + preserve thinking mode. add this to the role handling block: elif role == "developer" -> map to system at position 0, user elsewhere else -> fallback to user instead of raise_exception full command with the fix: llama-server -m Qwen3.5-27B-Q4_K_M.gguf -ngl 99 -c 262144 -fa on --cache-type-k q4_0 --cache-type-v q4_0 --chat-template-file qwen3.5_chat_template.jinja thinking = 1 confirmed. full think blocks. no crashes. that's what's running in the video in the thread below. if you've been using chatml as a workaround, check your server logs for thinking = 0. you might be running half a model.
English
@0xCoinacci @dvinaai 😁 free opus 4.6 veriyor bu yoksa ne işim olur
Türkçe