搞钱启示录
1.3K posts


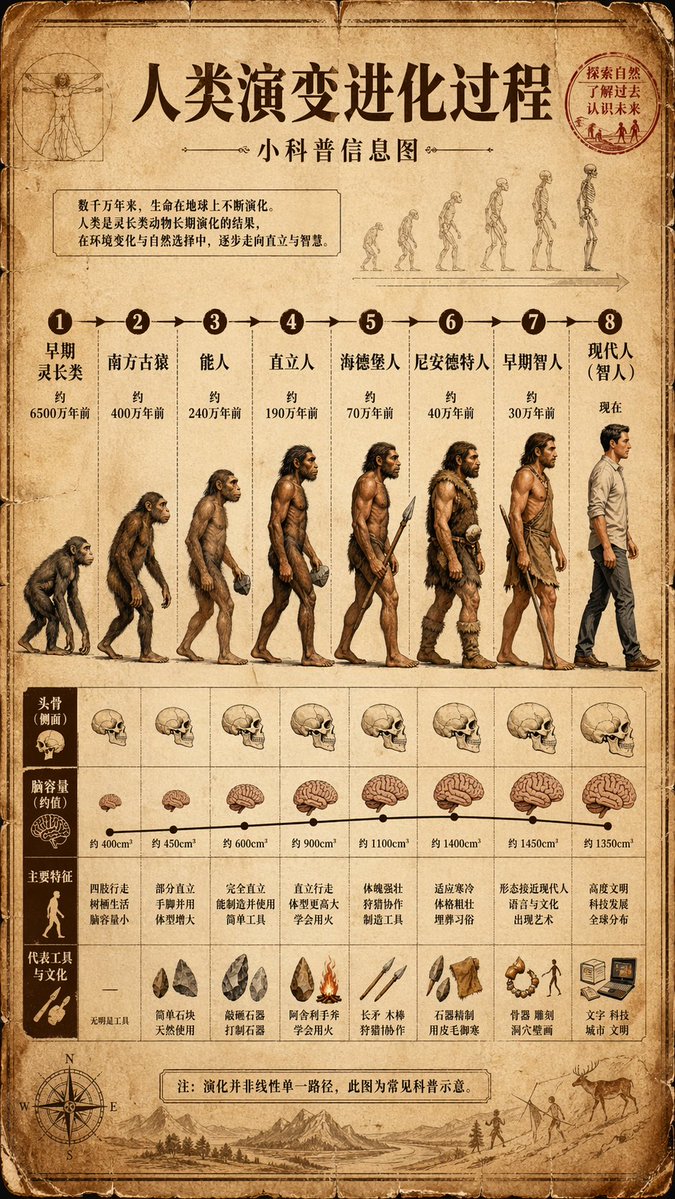



你觉得哪家生图强?
同一套提示词与参考图生成:
第一图是 GPT-image-2,
第二图是 nanobanana pro ,
第三图是 grok,
第四图是即梦5.0【不能参考真人图】,
我觉得还是 ChatGPT 强。




搞钱启示录@shendu128
同一个提示词谷歌🍌表现太好了,很真实,而 grok 的塑胶感感觉太假
中文
AI 代理的“Harness”到底是个啥?为什么它比模型本身重要 100 倍?
先说核心结论:模型只是“脑子”,Harness 才是“整个身体和环境”
推文作者 Rohit 直白地说:你用 AI 用得不对,不是因为没挑到最牛的模型,而是因为你没给它搭好“环境框架”(Harness)。
想象一下:
•模型 = 一个超级聪明但“近视+健忘+容易分心”的天才小孩。
•Harness = 你给他准备的书桌、工具箱、闹钟、护栏、记事本,还有“下次我醒来时该从哪儿继续”的手册。
小孩再聪明,如果书桌乱成一锅粥、工具找不到、每次醒来都忘光前一天的事……他也干不成大事。
洞见1:AI 不是“通用推理机”,它本质是个基于上下文的模式匹配引擎。它这一刻“知道”的一切,全看上下文窗口里塞了啥;它能输出啥,全看这些信息是怎么组织的。
→ 界面不是“装饰”,界面就是它的大脑。
洞见2:好的 Harness 不是“帮 AI 更聪明”,而是提前堵住它必然会犯的蠢。它像一个贴心的监护人,知道小孩会在哪儿摔跤,就提前放好护栏。
为什么需要专门设计?因为 AI 的“认知架构”和人完全不一样:
•人能一眼扫屏幕、空间记忆、并行注意。
•AI 是顺序处理 token、对格式极度敏感、工作记忆极小、容易被最显眼的信息“锚定”。
SWE-agent 的四个核心组件,每一个都精准狙击 AI 的弱点:
1搜索与导航:不是原始 grep,而是 capped 输出 + “结果太多请缩小”的提示。
→ 逼 AI 必须精准,不能越搜越乱。
2文件查看器:一次只看 100 行(黄金数量),保持状态,每行强制加行号。
→ 省掉 AI 自己数行的认知负荷,让它把脑力留给真正的问题。
3带 linting 的文件编辑器:编辑是原子操作,改完立刻跑 linter,语法错直接拒绝。
→ 把错误扼杀在摇篮里,防止连锁崩盘。
4上下文管理:老历史自动压缩成一行摘要。
→ 既保留轨迹,又不让垃圾污染当前决策。
洞见3:这些设计听起来“技术”,本质是认知负荷管理。AI 不是懒,它是真的“记不住、看不清、分不清”。Harness 就是在用工程手段,替它把“人类干得轻松的事”自动化掉。
知识点拆解3:Anthropic 如何解决“超长任务”——双代理 + 认知锚点
SWE-agent 解决的是单次会话的问题。真实项目几百个文件,一个上下文窗口根本塞不下。
Anthropic 的解法:初始化代理 + 编码代理的双人组合拳。
•初始化代理只干一件事:搭脚手架(init.sh、一份 200+ 条的 JSON 功能清单、进度文件 + 初始 git commit)。
•后续每个编码代理只专注一个功能,干完就更新进度和 git,保持“干净状态”。
最牛的发明是功能清单(feature list):每条功能都有 passes: false/true 字段,用 JSON 而不是 Markdown(模型不敢乱改结构化文件)。
洞见4:没有这个清单,AI 只能“看代码猜自己做完了没”——这太不可靠了!清单把“完成”变成了可验证的事实,不再靠猜。
人类工程师也靠文档、TODO、看板来记忆。AI 更需要外部“认知锚点”,否则每次重启就是失忆。
他们还给 AI 浏览器自动化工具(Puppeteer),让它像用户一样点按钮验证,而不是只跑单元测试就喊“成了”。
→ 这暴露了一个残酷真相:AI 只能看到工具允许它看到的东西。反馈循环质量,决定了它能干到什么程度。
出 bug 时,不问“怎么修”,而问“环境里缺了什么,才让代理犯这个错?”
他们把仓库本身当成唯一真相来源:
•扔掉巨型 AGENTS.md(会烂、抢上下文)。
•改成结构化 docs/ 目录 + 短地图文件。
•应用 per worktree 启动 + Chrome DevTools + 全套可观测性(日志、指标、链路追踪)全暴露给代理。
洞见5:当生产力爆炸,验证成了新瓶颈。让 AI 自己能“看到用户看到的东西、用人类用的工具调试”,才是王道。
他们还用机械化 linter + 结构测试强制架构一致性——坏模式无法扩散。
Awesome Agent Harness 的 系统其实分成 7 层(从上到下):
1人类监督(定方向、审 PR)
2规划与需求(把模糊想法变精确 spec)
3全生命周期平台
4任务运行器(issue → PR)
5代理编排器(多代理并行 + git worktree 隔离)
6Harness 框架与运行时(上下文、记忆)
7编码代理本身(现在已经是商品)
最扎心的洞见6:模型是商品,Harness 才是护城河。
真正厉害的团队,不是追下一个更强的模型,而是在不断完善让模型“稳定、高效、长期工作”的环境。
你搭好 Harness 的那天,才是 AI 真正开始为你工作的那天。
更深一层思考:
Harness 本质是模型弱点的“负面能力地图”(回复里有人说得太好了)。
•capped search = “你会淹死在自己结果里”
•linter = “你会悄无声息地写出语法错”
•进度文件 = “你会太早喊胜利”
它不是“帮 AI 变强”,而是诚实地承认 AI 的盲区,然后用工程手段填平。
这个地图越准,你未来换任何模型都吃香——因为弱点是相似的,强项才各有不同。
2026 年的 AI 竞赛,已经不是“谁的模型参数多”,而是“谁把环境搭得最懂人性(或者说最懂 AI 的‘非人性’)”。
Rohit@rohit4verse
中文
AI大转变的“底层逻辑”
2026年你直接把AI扔进你的工作流,它自己记得上周的项目文件、你讨厌的代码风格、甚至上个月的Bug模式,然后主动帮你干活。
1. 提示工程为什么“暴毙”?(保质期只有18个月的技能)
背景:2023-2024年,最牛的AI玩家靠“提示词炼金术”吃饭——精心设计角色、思维链、Few-shot例子,就能让模型输出翻倍好。
知识点拆解:提示词其实是最“薄”的一层。它像给临时工的纸条指令:写得再好,一次用完就丢。模型每次对话都是“失忆”状态,上下文一长就忘光。
不易察觉的洞见:真正值钱的不是“怎么说”,而是“让AI看见什么”。2026年大家醒悟:上下文(Context)才是最厚实的资产——它包括你的全部项目文件、历史对话、工具权限、代码库、甚至个人风格指南。
原则:提示词服务一次回答,上下文服务你一辈子的回答。
启发思考:你现在敲的每个提示词,是在“租”AI的劳动力,还是在“买”一块会自动长大的地基?前者越用越累,后者越用越香——这就是复利思维在AI里的第一次落地。
2. 智能编码(Agentic Coding):AI从“打字助手”变“初级同事”
背景:Claude Code一出来,大家以为只是“高级Copilot”。错!它带项目记忆、权限系统、能读数据库、跑测试、并行开多个分支。
知识点:这叫“Agentic”(代理式)——AI不再被动补全代码,而是主动“干活”:你只说目标,它自己拆任务、写代码、测Bug、提PR,你只管审。
洞见:行业花两年假装“委托层”不存在(人类总想自己敲键盘才有安全感)。2026年它突然成熟,因为AI终于能“记住整个代码库”而不崩溃。
隐藏原则:人类从“码农”升级成“项目经理”。你不再是“写代码的人”,而是“设定边界、审查成果的人”。
有趣比喻:以前AI是Uber司机,你得每句都指挥路线;现在它是你的实习生,车钥匙给你,你只管说“去机场,最快路线”。
思考:如果你还在手动敲每一行代码,是不是在浪费“经理级”的杠杆?
3. 开源Agent长大成人:从可爱Demo到生产级“马具”
背景:OpenClaw、Hermes 3这些开源项目,2024年还只是“炫技小玩具”,2026年发布日志全是HSTS安全头、密钥管理、Cron任务、多语言记忆……听起来超无聊,对吧?
知识点:Agent要真正跑在真实世界,必须解决“四个老大难”:不忘记任务、不搞崩生产环境、压缩历史又不丢关键线索、跨App不混淆。
洞见:性感的功能永远赢不过枯燥的基础设施。开源不再追基准测试,而是开始交付“让Agent活得久、用得安全”的马具(Harness)。Hermes 3训练时就假设“它会被当Agent长期跑”,所以才有长期记忆和内部独白能力。
原则:生产级AI的胜负,在“没人想看的管道”里决定。
启发:如果你是程序员,别再学下一个花里胡哨的模型,先把OpenClaw的发布日志从头读完——你会瞬间看懂2026年真实AI长什么样。
4. Karpathy式知识库:AI开始“自我增值”
背景:Karpathy把原始材料丢给LLM,让它自动编译成互相链接的Markdown知识库,新东西进来就自动更新、交叉引用、压缩。
知识点:这不是笔记App,而是“活的科研伙伴”。他的一个知识库已达40万字,像一本书,却由AI自己维护、瞬间可查。
隐藏洞见:AI从“临时助手”变成“会增值的资产”。每加一条新知识,它就更聪明;你投入越多,未来收益越大。
原则:可复用的不是提示词,而是“模型周围持续维护的知识层”。
比喻:以前你写一封信给AI(一次用);现在你在建一座图书馆(永远用)。
思考:你的个人知识库,是不是还在“垃圾堆”状态?每周花1小时扔东西进去,让AI整理——半年后你会成为团队里“活百科”。
5. RAG的“生死进化”:幼稚版已死,聪明版刚起步
背景:RAG(Retrieval-Augmented Generation)就是“先检索文档再回答”。2023年幼稚版(切块+向量搜索+塞提示)演示很牛,但一遇到矛盾信息、时间变化、跨文档推理就崩。
知识点:2026年分三派——
•改进RAG(更聪明切块+混合搜索):最务实,多数团队用。
•GraphRAG(建实体关系图):解决“两篇不互相引用的论文有什么联系?”
•无RAG(检索前置,维护结构化知识层):Karpathy就是典型,检索发生在“写入时”而非“查询时”。
洞见:RAG不是死了,而是“幼稚版”死了。真正聪明的人把检索当成设计选择,而不是宗教信仰。
原则:知识库越结构化,模型推理越省力。
思考:你在用AI查资料时,是每次都“现挖”,还是提前建好“活地图”?
6. Grok嵌入X:AI不再“躲在聊天框”,而是“活在你日常里”
背景:Grok直接出现在你刷的每条X帖子、搜索栏、回复草稿里。
最大洞见:AI该住在哪里,比AI有多聪明更重要。平台本身成了分发渠道——你不用切换App,AI就出现在你正在干的事里。
原则:工作流原生 > 单独聊天窗口。持久化记忆 + 工具调用 + 所在场景 = 真正“同事”。
启发:ChatGPT还在让你打开新窗口,你却能在刷X时直接让Grok帮你总结趋势——谁更像你的“生活伙伴”?
最后,给你的一句扎心金句
2026年不是“更好模型”的年份,而是“停止跟AI对话、开始围绕AI建造”的年份。
模型已经成了商品,模型周围的“马具”(上下文、工具、记忆、权限)才是稀缺资源。
Rohit@rohit4verse
中文




模型还是没有很好地解决记忆问题,需要借助第三方记忆系统工具才能 AI 长记性。
不然第1次问跟第100次,不会有多大差异。
就像你说喜欢草绿色,不喜欢深蓝色,如果是个人强调两次就记住你的偏好,但是 claude code 早就忘记了这个。
KK.aWSB@KKaWSB
中文
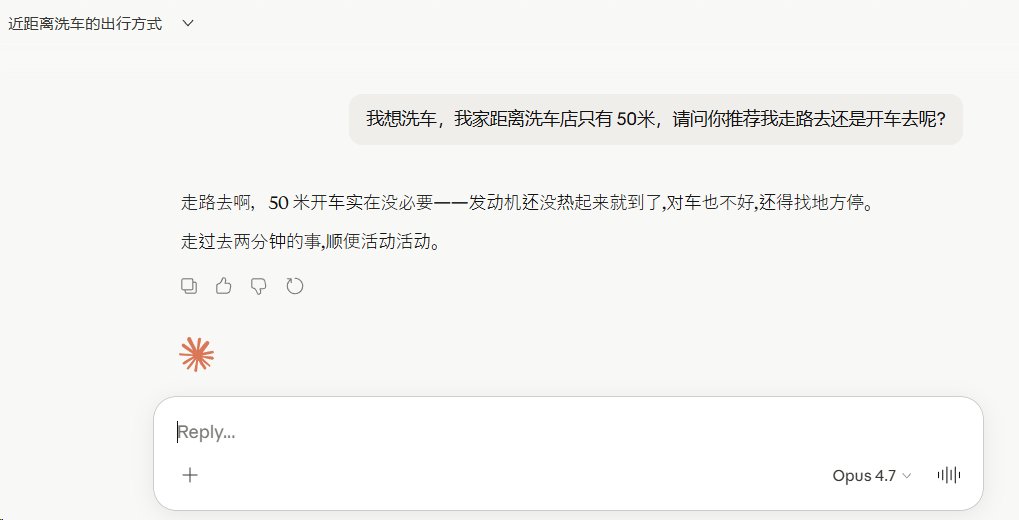
千问3.5回答不错:这是一个非常经典且有趣的问题,甚至难倒过不少AI。既然你家离洗车店只有50米,这确实是一个值得“纠结”的距离。
综合来看,最合理的方案是:人走过去,车开过去。
这听起来像绕口令,但其实针对不同的洗车方式,逻辑是完全不同的。为了帮你理清思路,我为你拆解了以下几种场景:
1. 如果你是去“自助洗车”
推荐方案:先走路去侦察,再开车过去。
* 先走路去的理由:50米也就是几十秒的事。你可以先走过去看看有没有人在排队,或者设备是否正常。如果前面排了三四辆车,你可以直接回家该干嘛干嘛,等没人了再把车开过来,避免了在车里干等的尴尬。
* 再开车去的理由:毕竟洗车的对象是车,你人到了车没到,洗车机也没法凭空变出一辆车来洗。
2. 如果你是去“人工洗车/精洗”
推荐方案:直接把车开过去。
* 效率最高:直接开过去,一步到位对接店员,把钥匙留给师傅就能走人。
* 避免往返:如果你走路过去,通常还得走回来取车或者等洗完再回来开走,反而走了“冤枉路”。
3. 如果你只是去“咨询/办卡/预约”
推荐方案:走路去。
* 省事护车:这种情况下车不需要到场。50米的距离,走路比找钥匙、启动、热车的时间还短,既环保又能顺便活动身体。
总结对比
为了让你更直观地做决定,我为你整理了一个简单的对比表:
方案 适用场景 优点
先走后开 自助洗车 避免排队干等,确认设备情况
直接开车 人工洗车/精洗 一步到位,无需往返
全程走路 咨询/办卡/取物 省油护车,锻炼身体
💡 小贴士:现在的家用车(电喷车)冷启动后,只要怠速稳定(大概10-30秒),低速行驶几十米对车的损伤其实微乎其微,不用太担心“冷车伤车”的问题。
中文

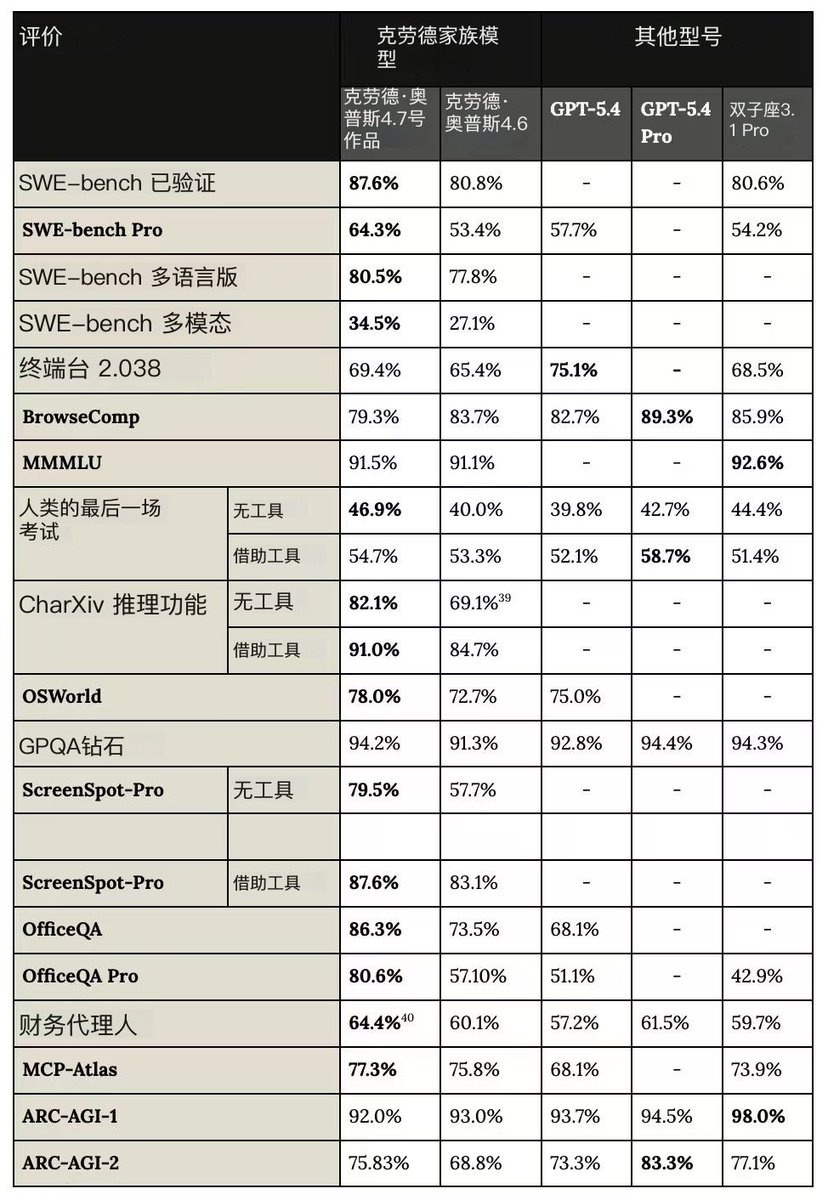
最强编程模型再次升级到 Opus 4.7,可惜封号越来越严格了,这家美国公司很反骨很中国,用他家产品竟然要上传身份人脸验证。
Claude@claudeai
Introducing Claude Opus 4.7, our most capable Opus model yet. It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back. You can hand off your hardest work with less supervision.
中文