
Siddhartha Gunti
641 posts

Siddhartha Gunti
@sidgunti
Founder @AdafaceHQ Applied AI @MistralAI
Singapore Katılım Eylül 2011
256 Takip Edilen836 Takipçiler

Worksheet to keep building the thinking muscle
siddg.com/human-intellig…
English
Living Agents - siddg.com/living-agents
I wrote this post by myself. If there’s slop, it's my proud slop. :P If a sentence is unclear, it means it's still unclear in my mind.
I’ve been building/learning with my own version of living agents for a few months. It started as a reminder bot. Now, it creates my reading digest, runs system design experiments, improves itself over time, and gives me ideas on how to improve the portions it can’t. This post is about my mind map of living agents and what’s working today for me.
What are living agents?
At the heart, they are:
Long-living code that self-evolves.
As close to a smart, persistent, junior knowledge worker as we have today. Can get to higher levels pretty soon.
To make this work with the constraints of today, a few more attributes appear:
Self-scheduling: Able to spawn off async work by themselves. They should be able to decide when, how, and why. Old-school persistent cron jobs or new-school long workflows both work well.
Heartbeat/wake-ups: It shouldn’t need an external action to start. It should wake up on its own. Decide on its work (actual work or becoming better at work) and work on it with persistence. A 15-min interval seems the right fit for the current arch/models. Anything higher is too slow (missing out on info), and lower is too quick (no new info).
Memory: Has persistent and self-written memory. ChatGPT, Claude, LeChat, etc. have it built into their systems. But that works only at a task level and showcases value sporadically. What’s working for me is episodic, day-wise, task-wise, manager-wise, and long-term self-written memory.
Evolving: Ability to improve own functionality. Not just the above three: getting better at self-scheduling, heartbeats, or memory management. But also to reuse its own learnings. Self-written and always-improving skills are working well for me. One direction I have mixed opinions on is its ability to improve its own core. Our infra and models are not there yet. But a few more experiments might give a better answer.
Next step: figuring out how we can make living agents work with current infrastructure. And make it work in our workspace today.
Implementing living agents in our workspace
Sandboxes: Giving an agent a persistent sandbox that it can read/write/execute from became a no-brainer. We are going to need a lot more CPUs and GPUs for living agents to use and reuse.
Entry points and modalities: We need a way to communicate with these agents. Telegram worked best so far. A web app as a standby is a decent option since Telegram is not a natural interface to track parallel tasks. As for modalities: audio (STT’ed), image, and PDFs (OCR’ed) are no-brainers. Any other modality (like Excel or high-res images), I upload to the sandbox and ask the agent to figure it out.
Exit points and working style: Exit points are how the agent is going to communicate its work to us. Technically, all the entry points could be exit points. But it's not enough. For example, we might not want to talk to a living agent with HTML. But the living agent might want to send us an HTML or even better, a hosted version of it. A tunneling system and sandbox file previews are the ones that I am using now.
MCPs, Skills & APIs: A living agent, even if it's self-evolving, is useless without new data feeds to work on. That’s where integrations come into play. All our existing integrations have one big pro and one big con. The pro is that they are made to be deterministic and resilient. The con is that they are fixed in what and how they provide the data. An API that provides Reddit results of a thread will work the same way irrespective of the need of the agent. Also, our abstractions like MCPs on top of these APIs fill the context with so much bloat irrespective of whether they are needed or not. Self-built skills seem to solve this problem to some extent. Skills are the best way to crunch the learnings, but to consume APIs, I think they are still the worst way. I don’t have a best answer to this yet. This is not to say our APIs are bad; web search, for example, seems to work wonders for Living Agent output quality that I can’t imagine shipping one without it.
Put these all together, and you have a really functional living agent that you could use today.
The potential and the large unknowns
Before we discuss some unknowns, it's worthwhile to amp ourselves up on why living agents matter and why I am personally excited.
Our brains: The core of LLMs and NNs came from our efforts in understanding how human brains work. I believe the closer we can understand and mimic human brains, the more we find the abstractions that work for the long term.
I have these notes on how I can become an expert at something:
- 10K hours
- Many repeated turns
- Valid feedback loops at each turn
- Valid environment with patterns to learn (chess and not roulette). less randomness and more logic. Humans learn patterns. If there are no patterns, we do worse than averages.
- On the edge of being uncomfortable. Concentration, and always push towards things you are NOT good at.
Look at all the parameters we defined so far for a living agent: heartbeats, memory, self-evolution, and persistence. As long as we leave a living agent with a valid environment, it should be able to eventually learn from the environment.
Not just the learning style, I am excited about another aspect of living agents:
Our working style: Living agents are the first ones that I see working like how we do in our existing systems. Let me explain with an example: LLMs were made to be reasonably accurate and grounding. For ex: When the LLM would say, “I good enough am," it wasn’t good enough for us to use it. We had to make the probability reliable. This is not new. We always needed deterministic and reliable digital systems. All of our APIs behave the same way (or we hope they would, and we have systems to catch when they don’t). All the LLM extensions like agents and workflows are being built in the same way. More or less like reliable APIs with systems to track when they don’t.
But living agents, even though they are not completely deterministic or reliable, have something very, very close to how we work. Something that’s not present in agents or workflows. and something that comes naturally to us: apprenticeship.
When we hire a junior employee/intern, we don’t expect them to be perfect at their task. We expect them to learn the craft and become better over time with effort. And we have natural ways to work with them. Ex: We don’t throw all the tasks at them. We plan and schedule tasks with increasing thresholds and complexities over time.
⇒ living agents will fit very naturally with our working style. If we look at living agents this way, there’s an explosion in different directions:
Specializations (like humans): We are already seeing specialization at the model layer. Coding models, video models, finance models, etc. Living agents will have specializations like humans. We don’t expect our accounting teams to do our marketing. The same way there will be specialized living agents on verticals or modalities. Specialization from the model layer will move to living agents. This will also fit super well into our ways of hiring. We hire juniors/interns based on raw energy (or the blank slate) or seniors/experts with specialization (memories/skills/sandboxes filled with exactly what the job requires).
Scalability (unlike humans): While it fits well into our ways of working, Living agents have something that humans don’t. The ability to scale. Say we train a junior engineer to become senior in a particular craft (say, DevOps at a particular company). If we hire another engineer, we have to start training from scratch (probably some training material can be reused). But with living agents, we can checkpoint the agents and spawn them off horizontally and vertically at an unprecedented scale.
While this does sound exciting. Let’s be realistic. This is all new. Our systems are not ready for this.
Observability: Our existing observability stack was built for human-written deterministic APIs and babysitting these APIs over time. We haven’t built a stack that helps us understand and improve living agents. We barely caught up to LLMs and agentic workflows.
Benchmarks: We are still figuring out the best way to evaluate RAGs and agents once they are deployed and how to use the observability stack to complete the feedback loop. We have to start on understanding how to benchmark living agents that take time to learn and continue to learn.
Industrial engineering: Other than benchmarks, we also need to think of the metrics to track such a complicated system. We had human-level KPIs that track outcomes, but we need metrics that are far richer, deeper, and more nuanced to help us learn how to build these new systems.
All good problems. All for an exciting future.
Imagine a future of living agents that are self-evolving at super scale at every step of their architecture. They are writing their skills, spawning their checkpoints, and collecting traces like the ones we never did before and using those to fine-tune the base models that they are being built on. Exposing living agents themselves as products and APIs. The users don’t need to know what’s in the black box. We don’t need to know how the junior engineer is becoming a senior engineer as long as we have proof that they are and can consume the value that they are creating.
--
Fun: I started this article in my head two weeks ago. The title then was ‘long-living agents.' Today, I believe, we can lose 'long.' Why not lose ‘living’? We have certain notions about an agent in 2026: an LLM with tool calls in a loop with MCPs. These are not enough to describe what a living agent is. So for now, ‘living agent’ it is.
Disclaimer: Living Agent is not a new invention. OpenClaw is one. Perplexity, NVIDIA, and Microsoft launched their own recently. Everyone else will release it in one form or the other.
English
Siddhartha Gunti retweetledi

1/4 LLMs solve research grade math problems but struggle with basic calculations. We bridge this gap by turning them to computers.
We built a computer INSIDE a transformer that can run programs for millions of steps in seconds solving even the hardest Sudokus with 100% accuracy
English
Coding with vibes in 2026
It’s very rare that you get to pen your thoughts on a topic. And the post can become obsolete within a couple of months. With that optimistic reminder,
Let me give a realistic teaser: I am not going to list “top 10 tips” to become a vibe coding super star. There are posts from better engineers almost every day. Instead, I list directionally what I am doing these days:
I’ve been an engineer for 15 years. Been vibe coding ever since Claude Code came out. 95% of my coding today happens via vibe coding. Whatever that says about me, I will leave that to you. But I do believe this is the next exciting iteration of our craft.
1. Read the code (including vibed code).
It’s irresistible to give a task to a coding agent, validate the results, and move on. But we are losing the important feedback loop. You need to read the code that got generated. That’s how you understand the nuances.
What system design is being created? How are different files linked together? What code is being written in a single file?
Our mind needs to go through the painful process of reading and re-reading to know which one’s right and which one’s wrong. Eventually, the mind will get better at this. It will figure out what to skip.
To learn a new language, one proven way is to consume content (movies, podcasts, books). Even if you don’t understand a single thing. Eventually, your mind will form the association. It’s the same principle.
Read the PRs. Read the tool calls that coding agents write. Read system design docs. Just read, even if you don’t understand a thing. Make your brain feel the pressure.
I learnt from reading vibed code that the priorities of coding agents and ours, the engineers, are different. Ex: writing clean code at a repo level is important for us. For a coding agent, it’s important only at a task level.
2. You’ll write more English. Not less code.
One wrong expectation is that you are going to write less. Not true.
We have to write in a different language. English. If LLMs are smart interns (or PHDs), our project descriptions/ design docs/ task descriptions are what that intern uses to produce results. The more we write, the smarter we write. The smarter we write, the richer the result.
Sending two sentences to a coding agent → expecting the result in the exact way you wanted → would not work. This is not a new paradigm. It never worked. We always operated in strict environments with compilers, rules, and syntax (even if JavaScript made you think otherwise :P). Types matter. Compiling matters. We can’t write “a plus b” and expect “a + b”. The error was immediate.
It’s similar in vibe-coding. There are 10 ways to create a Slack integration. If you just ask the LLM to integrate Slack, it will do so in a version that comes up first in its training data. Not necessarily the one that suits your requirements.
3. IDE is no longer just the editor.
My first program ever was written in gedit. Then came sublime, Atom, IntelliJ, VSCode, Cursor, and I ended last year with CLI. This year, I use a mix of kanban, CLI, and VSCode.
No one knows what the next coding editor is. But it’s clear it’s not going to be the same IDE.
And when I mean IDE, it’s not just the editor, it’s also the extensions you bind with, the “skills” you pull, and the workflow you use. Git worktrees are a thing now. It didn’t work for me (I am a multi git clone guy.) But it might work for you. Kanban is super visual and helpful to me. You might prefer coding in a chat interface like ChatGPT.
Go ahead. Experiment. Even better, build your own IDE. Customize. Be part of the change and start forming the mental patterns.
4. Plan first. Vibe next.
Vibe coding reminds me so much of the early days of coding. Before coding guidelines, abstractions, and SDKs came in.
There’s child-like wonder in just writing something without planning and seeing the result immediately. But you will soon find yourself faltering. Bad code stacks, compounds, and hurts. To implement something durable, you need to start with strong foundational patterns.
It’s the same in vibe coding. Once you are past the “wow” arena, you want to plan first before handing it off to the agent. This will save you loads of painful debugging time. It will save you those follow up prompts where you uppercase and shout at the agent. It will save you the internal monologue of wondering if vibe coding is slowing you down or if it is actually helpful.
I am not asking you to plan every single feature. There’s a nice balance. I found it helpful to plan for medium and long features. You will figure out your own rhythm. Just keep this in the back of your mind.
5. Context management is a challenge.
It’s an evolving topic. LLMs have fundamental issues - context rot, hallucination, and so on. And large-scale coding clearly requires a smarter way to deal with this.
Industry seem to play around AGENTS.md, Sub agents, slash commands, and tools. Skills are the latest entrant, and they have real potential to stay for a long time. Be aware of context management as a principle. Currently, the baseline I would recommend knowing is:
Sub-agents → separate context window. The main prompt instructions are copied to the context window. Has separate tools.
Skills → brings in additional context to the main agent when required. Ex: Best practices. If there are scripts, it brings in the IO of the script instead of the script itself.
Another player that’s part of your context management is external integrations. Ex: MCPs
Integrations will amp up your vibe coding experience. I use web search, pen testing, Notion, and Linear MCPs so far. There’s real value. But they are slow and not straightforward. We will figure it out. But it’s something to watch out for.
6. Learn to work on multiple tasks at once.
It’s clear we are going to work on multiple projects/ features/ todos at once. That’s the end-game promise of vibe coding. But the concept is still pretty new. We have always worked on one task at a time because that was honestly the only way to get work done. You couldn’t code on two projects at once. The switching costs were very high. But that cost is coming down drastically.
Some patterns here can be found by watching senior/ staff engineers and engineering managers. They are seeing the first value of parallelization because they always orchestrated multiple features at once. Now every engineer can do this. We just need to practice.
7. New engineers: don’t rely completely on vibe code.
Atleast not yet. Even though it seems that you wouldn’t need to code in the traditional sense two years from now. We are not yet there today. Your mental patterns to understand concepts at a system design level didn’t form. If a bug happens, you still need to get your hands dirty.
I recommend only using coding agents for max 50% of the code. Ideally, ask the coding agent to tell you the changes, and you do it yourself. Your brain requires the feedback loop.
Btw, this was always a fast-moving industry. You should have a certain personality for the industry to resonate with you. Welcome to our fastest iteration of the craft :)
8. Pro engineers: it’s ok to grieve. But there are far more reasons to be excited about.
It might seem daunting that an AI is able to code something in minutes that would take us days. That someone else is stealing the act that was part of our craft. Take time to grieve. It’s a valid emotion. But,
The way I see it, the purpose of the art and the art itself didn’t change much.
Coding has always been a fast-moving industry. We as a species were never happy. I remember when I coded in a single 5K line jQuery file to power an entire e-commerce checkout flow. It was replaced within months by React. I never touched jQuery post that. Our code gets written, rewritten, and deleted so often to replace it with something better. We were the frontiers of finding better abstractions. This is literally part of the craft.
I see that coding as an art form is part of a hero’s journey. A customer has a pain point, and we solve it with code. That hero didn’t change. That intent didn’t change. The fun in figuring out how to make the hero succeed faster with a reliable solution didn’t change.
Tools changed. The impact that we can create changed. Instead of helping the hero with a smaller problem, we can help them solve much bigger problems.
The hero might take time to realize how much they can do. There will be fluctuations. Designers will become design engineers. Sales might become sales engineers. Engineers might become forward-deployed engineers. There might be more entrepreneurs than ever before.
We don’t know what's going to happen. The transition might be painful. But if you stick with the craft because you love it, we will reach the new island together. It’s going to be an exciting place wherever we reach.
One of my favorite authors said this about AI and art… the art is not the final piece we deliver. That’s just a token of work done. The art is the process, and the art is the person who puts in the effort. Art is us.
English
Siddhartha Gunti retweetledi

I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue. There's a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering. Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind.
English
My 8 favorite books of 2025:
- The Hitchhiker’s Guide to the Galaxy
- The Art of Spending Money
- Four Thousand Weeks
- Nenu mee brahmanandam
- The Book You Wish Your Parents Had Read...
- Seven Brief Lessons on Physics
- Catch-22
- Death Note
siddg.com/8-favorite-boo…
English

asimov.press/p/penicillin-m…
Well written and fun read around ‘accidental’ discovery of Penicillin
English

Siddhartha Gunti retweetledi


I heard my mom casually conversing with Gemini in Telugu.
Didn't even know when she installed Gemini.
Her mind doesn't think English first. So speaking in Telugu >>> typing in English
English
Comet couldn't take over Dia for my daily use.
Will Atlas do it?

English

That's it for now.
Next would be
- Improving prompts
- Tracking token usage
- UX to show todos, interrupt main loop
English
8/
Next up
- Web search tool (Using Exa for now. Other providers are not tested for now)
- Read/write todos
- Bash tool
Now I can go meta and use the Ada agent to build Ada
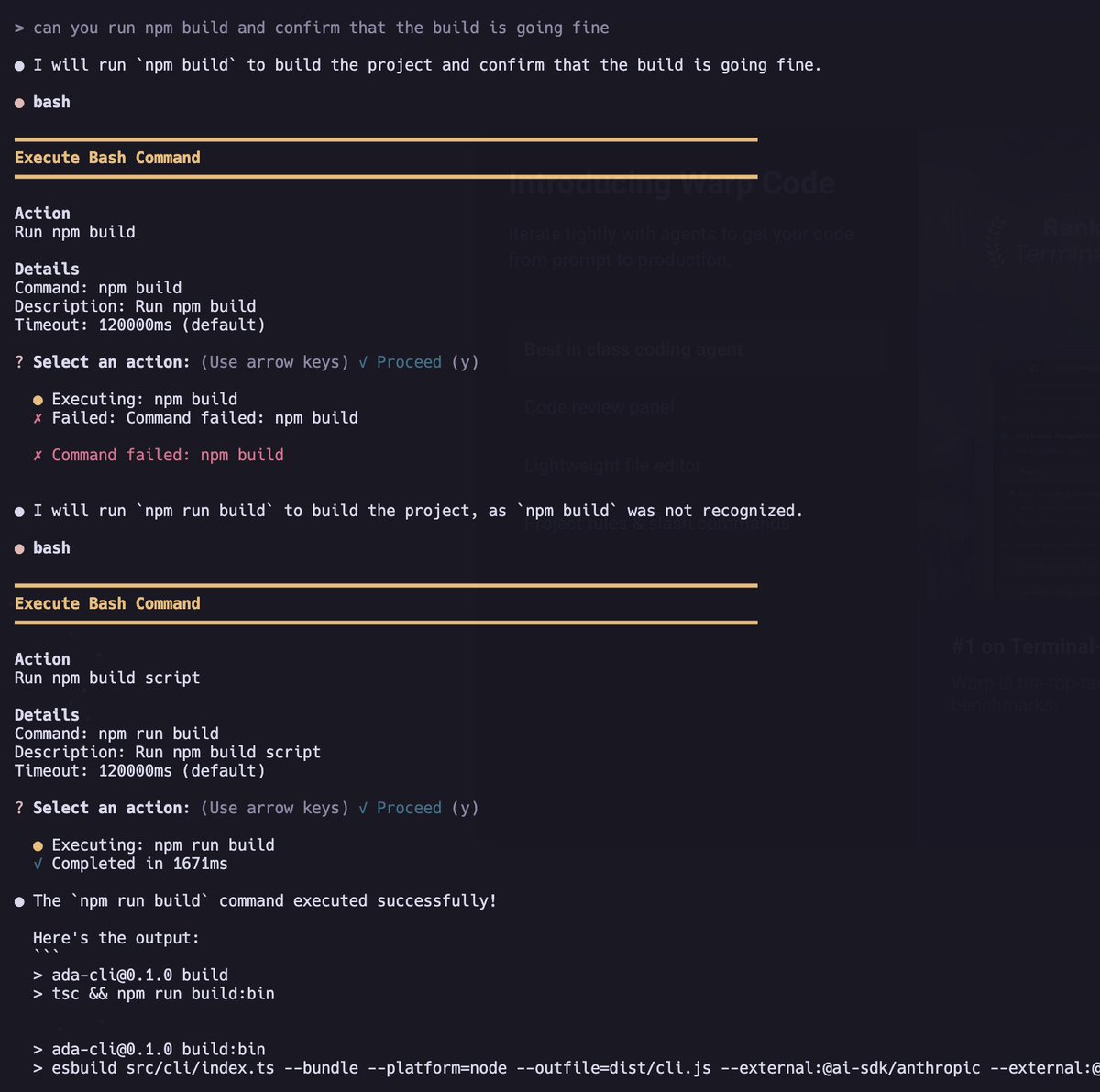
English
I've been using CLI Coding tools for the last 2 months.
Almost 90% of my coding is happening on CLI.
Seems like the right time to build one myself to understand the specifics.
Let's spend some hours...
English