Sabitlenmiş Tweet

Abstraction and parallelism are accelerators in favor of neg-entropy. How abstract an parallel are your guiding principals?
English
siggibecker
5.7K posts
@siggibecker
siggi wyrd https://t.co/GatgKzeiY2…









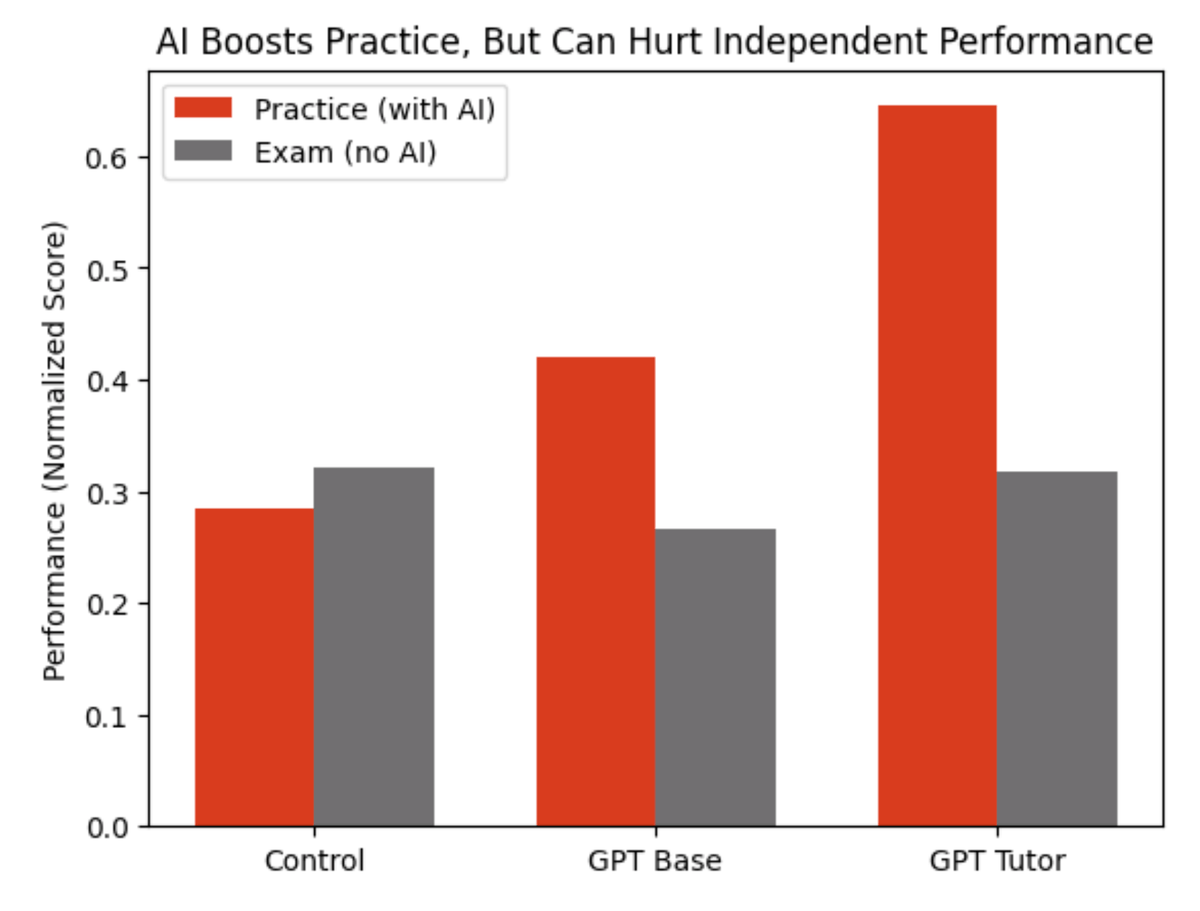



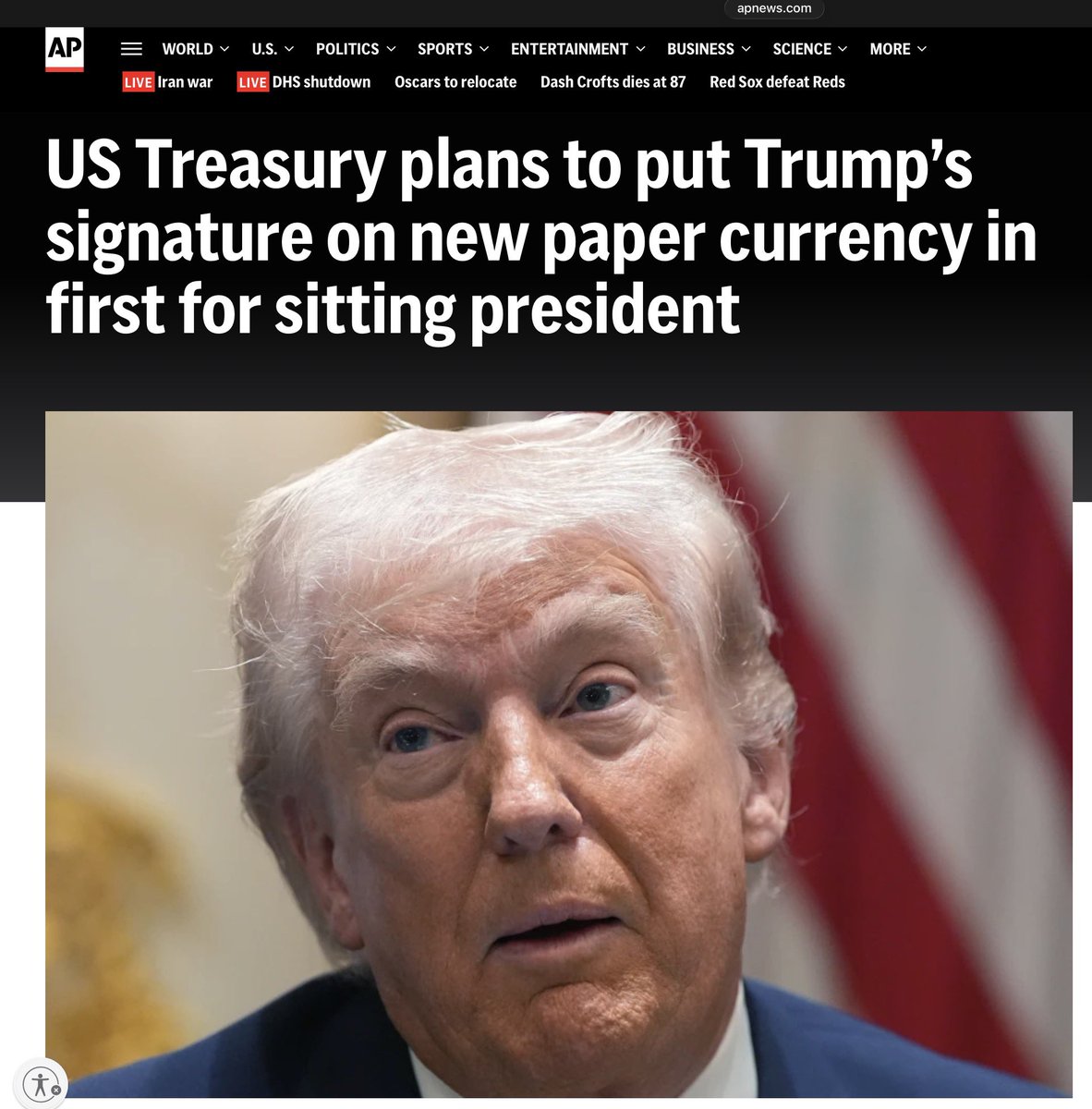

Erich Fromm invented the term malignant narcissism: “It is a madness that tends to grow in the lifetime of the afflicted person. The more he tries to be a god, the more he isolates himself from the human race; this isolation makes him more frightened, everybody becomes his enemy, and in order to stand the resulting fright he has to increase his power, his ruthlessness, and his narcissism.”



