
arch rock
3.3K posts

arch rock retweetledi

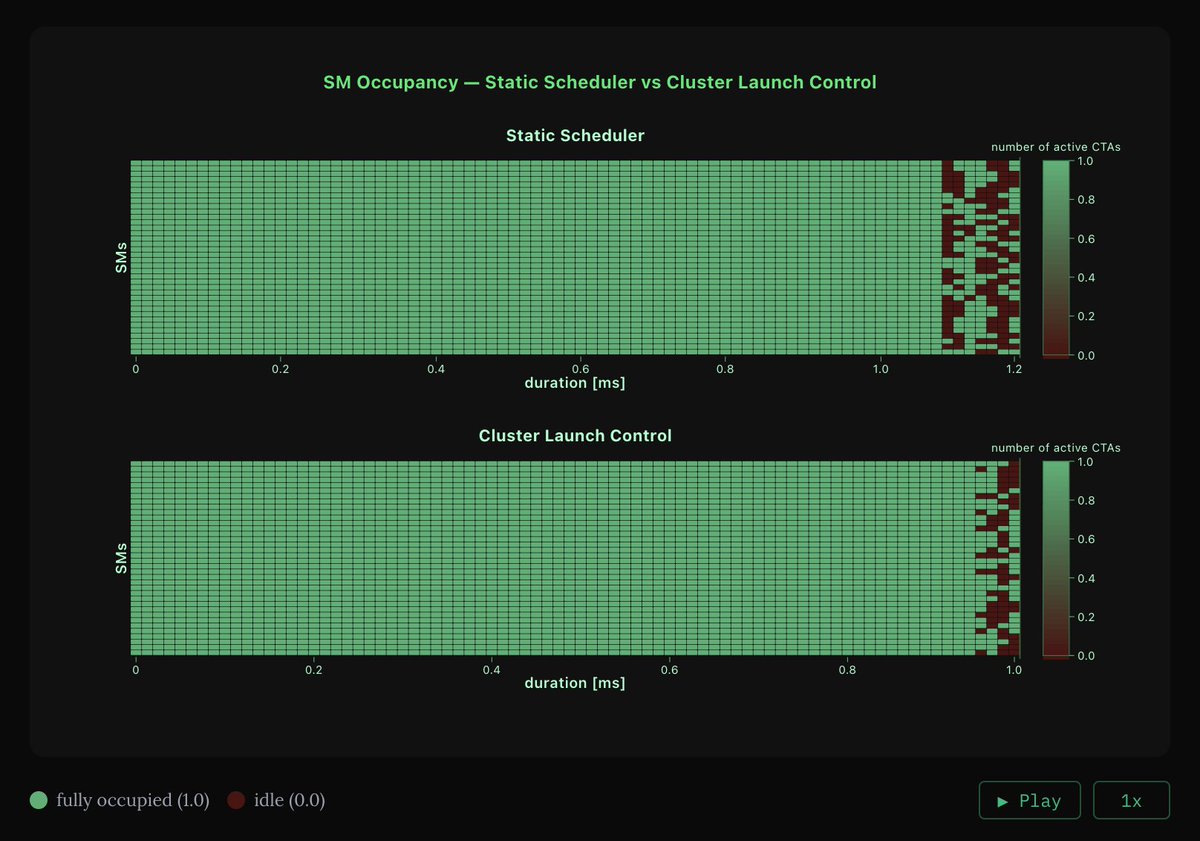
I wrote a matmul kernel on B200 in pure CUDA/PTX that beats cuBLAS by 6% at M=N=K=8192.
Inspired by @gaunernst's blog on Blackwell instructions with benchmarking done on @modal.
Blog: paulwillchan.com/articles/outpe…
Repo: github.com/Better-Call-Pa…

English
arch rock retweetledi

Long Context is everything.
时代变了,Long Context 效率已经成为了第一性原理。
最新的 DeepSeek V4 里 MLA 已经被放弃了,Paper里甚至连解释都没有。犹记得当时 DeepSeek V2 引入了 MLA,引起了不小的轰动。
V4 的关键 attention 设计已经是 CSA + HCA 的 hybrid attention了,序列维度压缩成了大家更关心的问题。
本质上是模型的注意力架构的重心变了,现在的大概大家关注的是 Long context 的效率。MLA 压缩单token成本的关注点已经不是最重要的问题了。
现在到了 1M context,瓶颈不只是每个 token 存多少,而是有太多 token 要参与计算。问题从 KV 的宽度 变成了 序列的长度 。
这个过程其实已经在模型厂商是有一个内部的清晰的路线。譬如DS的演进路线感觉就是比较清晰的:
MLA → DSA / DeepSeek Sparse Attention → NSA / Native Sparse Attention → V4 的 CSA + HCA
在 V3.1-Terminus 上引入 DSA,包括 lightning indexer 和 fine-grained token selection,并且当时是“DSA instantiated under MLA”。
V4现在则是引入了hybrid attention: Compressed Sparse Attention + Heavily Compressed Attention。
不过 V4 还是保留了低秩压缩、shared KV、latent query 等 MLA-like 设计。
调研的过程中还发现了一个 Long Context Paper 收录仓库,github.com/Xnhyacinth/Awe…
中文

通常硅谷游记的价值都不高,往往透着一股刘姥姥进大观园之后回村里吹牛的土味。但这篇还真不错。
有几个话题值得深挖。
硅谷是一个聚集了全世界最聪明的人但没什么智慧的地方。这些聪明人各个单看都是人中龙凤,但聚到一起形成的那个场,决定了他们只能极度内卷、不管不顾往一条路上冲,至于这条路通向的是天国还是地狱,他们没时间多想,想也没用,身不由己。这篇文章里提到 CEO 们开始把自己的房子变成堡垒——这说明他们已经知道大概率正在走向炼狱。
其实这篇文章主要的篇幅讲的就是一件事——速度差。文中提到一个现象:生产端效率提高了 10 倍、100 倍,实际营收增长呢?百分之几十,最多一倍。
这个现象背后反应的是五个速度之间的差,我认为这五个速度之间的差会决定未来十几年 AI 产业甚至全球经济的局面,这也是我目前看待 AI 革命的认识框架之一。
这五个速度是:
1. AI 推理应用在生产端的扩张速度
2. 资本扩张和转移速度
3. AI 模型智能水平的提高速度
4. 硬件生产和基础设施建设速度
5. 市场需求增长速度
这五级速度,从 1 到 5,逐级剧烈下降,呈现巨大的速度差。
一个反直觉、很多人视而不见的事情:在这个游戏里,不是快的打慢的,是慢的打快的。不是越快越厉害,而是越慢越厉害。速度越慢,权力越大。
为什么英伟达现在拿走了全行业 85% 的利润?就是因为硬件创新的周期比 AI 应用慢几百倍,成了行业瓶颈,给了他阶段性垄断的历史机遇。
所以现在做垂类 AI 应用的求着 VC 给投资,VC 求着大模型公司给机会,大模型公司求着英伟达给卡,而黄仁勋最大的噩梦是市场需求跟不上 AI 泡沫崩溃。
在推上有些人每天亢奋于自己所取得的进展和效率的提升,却从来不谈产出,对此我却经常冷言冷语,原因就在这里。其实我自己也在很认真的学习 AI,但到我这个年龄,对于那些路都看不清楚就瞎努力的人确实是尊敬不起来。
在生产效率上内卷的人在这场游戏里是最低端、最弱势、最没有权利的。就像这篇文章里提到的,连硅谷那些每天烧几百上千美金 tokens、第一时间交流最前沿 vibe coding 经验的程序员,都要面临 90% 被失业的下场,你们这些周边还卷个什么劲啊?说句特别刻薄的话,真好似插标卖首。你们还不如来我们 crypto 圈炒炒币,别瞧不起赌狗,你们玩的那个游戏成功率比炒币低得多。如果想玩确定性高一点的游戏,就还得在最慢的第五级赛道上下功夫,去靠近人。
话就说这么多,原文各位自己去看,看完了可以再回来品品我说的有没有道理。
Colin Wu@colinwu
看了五源资本合伙人孟醒最新的硅谷 AI 文章,好有意思: 硅谷共识是还要裁掉 80% 的人类? 马斯克的 xAI 为什么搞不成? 很多创业公司开始招 “AI builder” 的新角色? CEO 们都在“买比特币、建地堡、给家里装防弹玻璃”? “未来的情形可能是,10 个人干过去 100 个人的活,拿 20 份钱,然后 90 个人失业。” 当 AI 什么都能做的时候,人的价值正在从 “会做什么”,变成判断 “什么值得做、什么不该做” 的。 一些笔记: 1、整个 Meta 几万工程师,全员都在用 Claude Code,搞内部 token 消耗排行榜,末尾可能被裁员;Meta 裁员也最狠,已经裁了上万人,把人的成本换成了 token 成本,硅谷共识是科技公司应该需要裁掉 80% 的人 2、马斯克过去做 SpaceX、做特斯拉,本质上做的是系统工程:链路很长,涉及软件、硬件、供应链,每一块都有创新空间,但最终是一个端到端的工程问题。他擅长的是在这种长链条里,识别出关键杠杆点,然后极限压缩时间线来攻克。火箭发动机级联、复用着陆,都是这种思维的产物。xAI 的问题是没有全局规划,只有冲刺。 xAI 的一位 cofounder 去年就说有两件事他没想到:第一是竞争这么惨烈,第二是 AI 时代应用创新的机会这么少,都被模型吃掉了。 3、更激进一点想:今天所谓的 “AI native 组织”,听起来很 sexy——让每个部门梳理工作流、把能被 AI 介入的部分线上化、写成 skills。但本质上就是在人肉蒸馏自己:你把你的能力变成机器的 skill,公司拿到了你的 skill,实际上就已经完成 AI 化了,是否要由此裁员,那是一个道义的问题。今天 Meta 就是在干这件事。 4、整个硅谷都在盯着 Meta,如果它的实验成功了——营收没掉、效率真上去了,其他大厂会迅速跟进,裁员就从个案变成行业常态。而且裁员有一个残酷的自加速机制:一开始大家不敢裁,怕伤士气;一旦变成常态,就越裁越快、越裁越不心疼。 5、很多创业公司开始招一种叫 “AI builder” 的新角色——合并了产品经理、前端工程师、后端工程师于一身。还有一种是合并了数据科学家和机器学习工程师的复合岗,以及合并了写作、投放、运营的内容一体化操盘手。 6、这个看似分布式创新的世界,底层其实在极度中心化。这个中心就是英伟达。如果你今天能稳定地提供一个 API 服务,比如 Claude 的 API,做到 99 分位的稳定性,你可以卖官方 API 价格的两到三倍。 在 2028 年之前,没有任何一家 AI 公司能靠堆算力显著拉开差距。算力约束客观上在强化大模型市场的寡头格局——不是谁不努力,是物理世界的制造周期就是这么慢。背后的权力结构很清楚:谁有卡谁厉害,谁有卡由英伟达决定。今天上市的 CoreWeave、Lambda、Nebius,背后站的都是英伟达。 7、这次硅谷行,反复听到朋友们在认真讨论同一件事:买比特币、建地堡、给家里装防弹玻璃,他们都不是开玩笑的语气。为 CEO 提供住宅安防的企业,创下了 2003 年以来的最高增长水平。 全文: mp.weixin.qq.com/s/kwErGjX231e2…
中文
arch rock retweetledi

Let's dive deeper
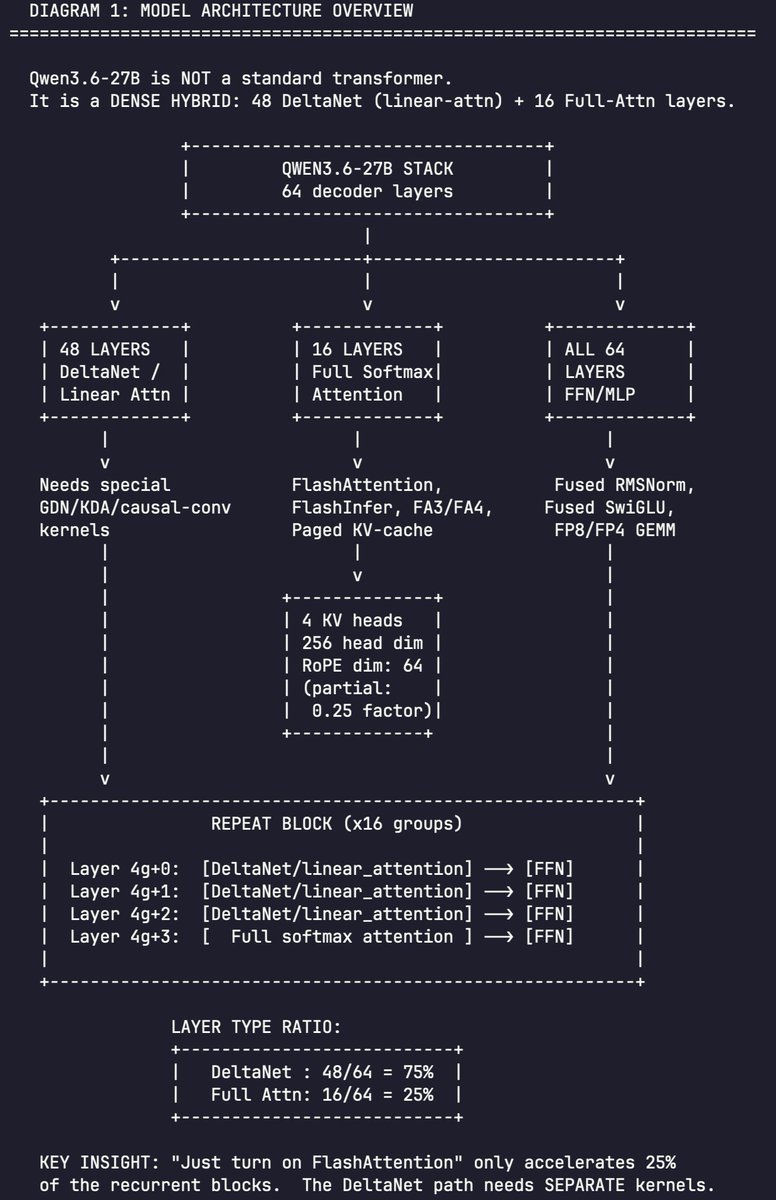
Do you know that 75% of Qwen 3.5 27B layers are DeltaNet (linear attention) and not softmax / full attention?
Because of that, FlashAttention is only able to accelerates ~1/4 of the model
Ahmad@TheAhmadOsman
How to go about learning all of this? 1st: Start with the serving engine view - vLLM: PagedAttention, continuous batching, prefix caching, CUDA graphs - SGLang: RadixAttention/prefix reuse, speculative decoding, MoE, structured/agent workloads - TensorRT-LLM: NVIDIA peak stack, FP8/FP4, Wide-EP, disaggregated serving - FlashInfer: reusable kernel/operator library for attention/GEMM/MoE/sampling 2nd: Go down the stack - Triton tutorials → custom fused kernels - CUTLASS/CuTe → Tensor Core GEMM and Blackwell/Hopper details - FlashAttention papers → attention algorithm/kernel co-design - PagedAttention paper → KV-cache memory management - MoE docs → routing + grouped GEMM + all-to-all - Nsight profiling → stop guessing 3rd: Do this mini-project sequence 1. Implement RMSNorm in Triton; compare to PyTorch 2. Implement fused SiLU × gate 3. Implement simple FP16 matmul; compare to cuBLAS/rocBLAS 4. Implement paged KV lookup for decode attention 5. Add FP8 KV cache with per-block scales 6. Implement toy top-k sampling on GPU 7. Implement tiny MoE dispatch + grouped GEMM 8. Integrate one custom op into vLLM or SGLang and profile end-to-end
English
@TheAhmadOsman can you elaborate how you achieve this conclusion?
English
DeepSeek V4 Pro, for how massive it is (1.6T Parameters), is quite undertrained (32T Tokens)
Yes, undertrained
It has less intelligence density than that of V3.2 which is like 1/3rd of its size
Ahmad@TheAhmadOsman
Kimi has dethroned DeepSeek
English
@techeconomyana 就是这种架构一旦是scale的次优选项,哪怕你便宜很多,但是和能在最优scaling下面一直进展的顶级模型的差距可能存在越拉越大,这点来说这么早让DS承担了不应该承担的各种名誉 和任务并不好
中文

arch rock retweetledi

I won't be at ICLR this year but @xingyudang will help present Fantastic Optimizers arxiv.org/abs/2509.02046!
Stop by at Pavilion 4 P4 5309 this afternoon to see what we have found in extensive sweeping and more importantly, what we learned after the paper that leads to Hyperball!
English

美国数学家Richard Hamming是图灵奖得主,计算机先驱,纠错码之父。
他说自己很早在Los Alamos见过Feynman费曼、Oppenheimer奥本海默等。他承认自己当时很嫉妒,凭什么大家都是物理人,你们这些人是大牛人?
他后来在贝尔实验室Bell Labs继续观察Shannon香农、这些人,为什么有些人做到了,而其他人只是差点做到了?
“运气”只能解释一半。具体做成哪一个题,当然有运气。
Hamming自己也承认,他和Shannon香农同在贝尔实验室Bell Labs,同一时期一个做coding theory,一个做information theory,确实有运气成分。
但Einstein爱因斯坦、Shannon香农这类人可以反复做出好东西。一次可以说是撞上了,反复撞上,就要看准备工作、胆量和选择了。
机会会飘过很多人身边,但只有少数人已经在脑子里预留了接口。
他讲,重要问题不是结果影响听起来多大。比如时间旅行、传送、反重力,结果影响当然巨大,但手里没有合理的入口,也只能供人幻想。
一个真正该上的科题,要同时有分量和入口,如果做成,它会改变一些东西;而你现在又能找到一条可以攻进去的路。
很多聪明人输在这里。他们每天忙忙碌碌,设计问题很精致,方法很专业,可心里其实知道,这些东西就算做完,也很难通向更大的东西。
Hamming每周五中午以后给自己留“Great Thoughts Time”,只聊大问题,比如计算机会怎样改变科学?
这听起来像偷懒,其实是给自己留10%的雷达时间。
你如果一周五天都在处理眼前小事,很容易把效率误认为方向。你会变成一个很勤奋、很可靠、很会交付的人,然后十年后发现,自己一直在小问题上越做越熟。
Hamming还有一个观察:
关着门工作的人,完全隔绝噪音,短期内很舒服,貌似产出更高;长期看,你会错过那些不成体系、没法写进报告、但能告诉你“问题变了”的信号。
而开着门工作的人,虽然经常被打断,但更可能知道世界的新动向。一流工作需要深度,也需要暴露在真实问题流里。
他讲,成名后的危险,也很像今天的创业者、研究者和内容创作者。
一旦做出一个大东西,人会不愿意再种小种子,只想一上来就抱大树。Hamming说Shannon香农在信息论之后,可能就被“下一次必须同样伟大”这件事困住了。
早期的伟大而会把人冻住。因为你不愿意再做那些小、丑、未成形、别人看不上的起点。
但大东西通常就是从这种小起点长出来的。
还有一点很多人不爱听。
做出来还不够,你要会把它讲出去。
Hamming说科学家讨厌“sell”这个词,觉得好东西应该自然被世界看见。可现实是,所有人都在忙自己的事。你写得不清楚,讲得不清楚,会议上不敢开口,别人就会翻过去。
所以表达不是包装,是研究的一部分。
一个想做一流工作的人,至少要会三种表达:
写清楚,在正式场合里讲清楚,在混乱的场合里也能讲清楚。
很多“事后诸葛亮”三周后写报告证明自己早就看对了,但时过境迁了。
才华放晚了也会变成旁白。
把“伟大”从天赋、环境、运气这些大词拽回到具体的日常动作:
你有没有固定时间想大问题。
你手里有没有10到20个真正重要、且可能进攻的问题。
你遇到一个机会时,能不能立刻看出它碰到了你哪一个老问题。
你做一个项目时,有没有顺手把它变成一类问题的方法,而不止交一个答案。
你有没有把自己的缺点拿来当借口。
你会不会和大的体系合作,借力秘书、同事、老板、听众、组织流程打战役,而不是一生耗在小型战斗里。
讲真,你可以说自己缺运气,缺资源,缺年轻,缺老板支持。那你有没有准备好?有没有选对问题?有没有留出想大问题的时间?有没有勇气押上去,把成果讲到别人愿意停下来听?
说到最后,很多所谓怀才不遇,可能只是长期没有管理自己。
中文
arch rock retweetledi

🚀 We just published a deep technical blog on how SGLang and Miles delivered Day-0 support for DeepSeek-V4.
199 tok/s on B200 (Pro 1.6T), 266 tok/s on H200 (Flash 284B) at 4K context, and throughput stays strong at 900K context (180 and 240 tok/s respectively).
This is a full story behind V4 Pro (1.6T) and Flash (284B): how we built systems for hybrid sparse attention, manifold-constrained hyper-connections (mHC), and FP4 expert weights, plus a full RL training stack that runs at 1.6T scale.
What's covered:
1. Inference (caching and attention): ShadowRadix prefix cache, HiSparse CPU-extended KV, MTP speculative decoding with in-graph metadata, Flash Compressor, Lightning TopK, hierarchical multi-stream overlap.
2. Inference (kernels and deployment): fast kernel integrations (FlashMLA, FlashInfer TRTLLM-Gen MoE, DeepGEMM Mega MoE, TileLang mHC), DP/TP/CP attention, EP MoE on DeepEP, PD disaggregation.
3. RL training: full parallelism (DP/TP/SP/EP/PP/CP), tilelang attention, enhanced stability, FP8 training.
4. Multi-hardware: NVIDIA Hopper, Blackwell, Grace Blackwell, AMD, NPU.

English
arch rock retweetledi


arch rock retweetledi


arch rock retweetledi

arch rock retweetledi

JAX is great for model code, but fast LLM inference often needs access to optimized GPU kernels.
I contributed 2 FlashInfer tutorials showing how to call FlashInfer kernels from JAX via jax-tvm-ffi, including a Gemma 3 example.
Download the notebooks and try them 🚀

English
arch rock retweetledi

How I read papers now.
This is an explainer by Claude about the new Compressed Sparse Attention v4 uses to compress the KV cache.

wh@nrehiew_
Now reading:
English
arch rock retweetledi

deepseek V4 new attention is very elegant, i find it similar to NSA (Native Sparse Attention) in principle, but NSA does it in parallel, CSA (Compressed Sparse Attention) is more sequential

elie@eliebakouch
this is so amazing, CSA is a new attention arch close to deepseek NSA imo, but sequential instead of in parallel. NSA had this compression of KV, here it's the same, and then they do DSA, and sliding window to keep good local context (also in NSA)
English

@RihardJarc Why don’t they just cut one time with enough quota and that is it ?
English

$META cutting 10% of the workforce (8.000 roles) and eliminating 6.000 open positions.
This will happen across the board in the tech sector and more broadly in knowledge work, Zuck is as always just ahead of the pack. Companies are switch labour costs for AI compute.
English