
@zephyr_z9 FREE TO JOIN My Real-time trading alerts and investment strategies Market forecast analysis 📊
Reply with "join" to my WhatsApp number +15043257967
👇 Details link
api.whatsapp.com/send?phone=150…
English
Zephry
64 posts

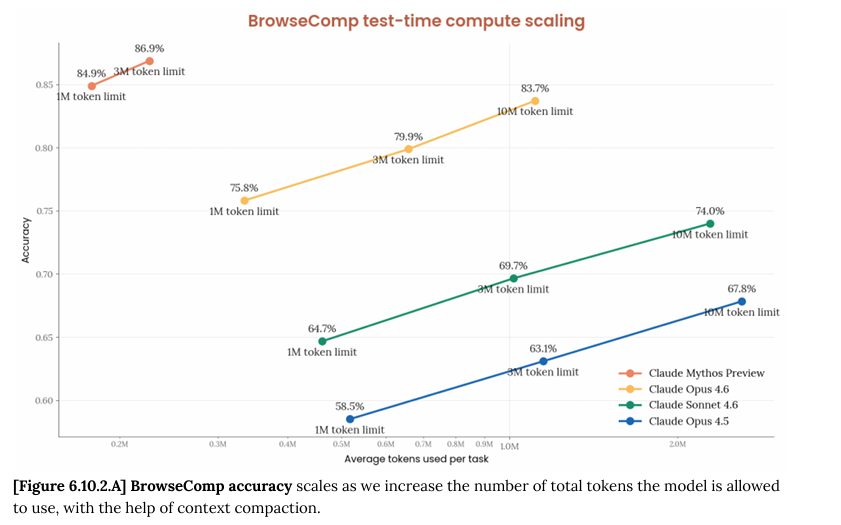
每年的Nvidia GTC大会,都会带来一些技术范式转新移概念,作为全业界的新技术标杆 各家在GTC之后都会改roadmap去抄作业 总有人问,AI芯片下一波结构性趋势转变的机会在哪里? 这几个月范式转移带来的结构性转变机会之一,就是AI异构推理,而以Cerebras为首的SRAM路线初创,就这样走到了新趋势前沿 ------------------------ SRAM路线的公司生态位在哪里,得先看genAI推理的不同阶段workload特点 主要分成三个部分: prefill:计算强度特别高,对memory带宽速度要求不高,对memory size要求中等偏高 decode阶段的attention部分:计算强度中等,对memory带宽速度要求特别高(对kv cache的反复读写),对memory size要求特别高,因为batch size的变大造成了kv cache的线性增长 decode阶段的FFN部分:计算强度中等,对memory带宽速度要求特别高(模型权重的反复读取),对memory size要求中等偏高(模型权重) SRAM路线的芯片特点也很清楚: 除了memory带宽做到了极致,其他方面都是严重缺陷,本质上是用计算强度和memory size做不大这两个劣势,换取了极致的memory带宽速度 --------------------- 再来分别看AI推理的三个阶段,SRAM的适用度 prefill:SRAM计算强度无法做的很高,因为整个芯片上的SRAM面积占用太大,计算模块面积受限,所以prefill是弱项 decode阶段的attention部分:SRAM memory带宽要求高能达到,但是SRAM memory size很小达不到batch的要求,所以SRAM做attention只能满足一半需求 decode阶段的FFN部分:SRAM memory带宽要求高能达到,memory size要求中等,SRAM芯片通过互联通信的优化,能勉强解决memory size的问题,虽然代价很高,但ROI在某些场景下还是能算的过来的 ---------- 所以SRAM路线的加速器 在AI异构推理的适用范围也很清楚: prefill部分别想了,性能垃圾,经济性垃圾 decode阶段的FFN部分,属于努努力加大成本还能够得着 decode阶段attention部分,kv cache对memory size要求太高,批量处理需求实现过于高昂,让Cerebras昂贵的230万美元一片,45片连成一起的奢侈的一亿美元的系统做成专属的超级VIP服务,完全是经济性灾难 想象一下,一两个用户agent flow做coding任务花了1~2M context length,就得耗费230万美元一整个cerebras的44GB SRAM来做KV cache,不然速度就上不去,这是什么样的奢侈服务 ------------- 所以结论简直不能再明显了:Cerebras如果单独做全栈AI推理(prefill + decode ATTN + decode FFN),经济上是走不通的,没有未来的 因为Cerebras成本是非常惊人的,即便是他们毛利率压的如此之低,每台 CS-3 系统的隐含租金还是要 $41.96/小时,是B200的差不多十倍租金,更不要说CS-3还得很多片连起来做LLM推理,租金要再乘以很多倍。 这也是为什么SRAM路线经济效益如此差的原因,Nvidia在GTC已经清晰的指出了这一点(如图)。 鼓吹SRAM路线以后取代HBM?那是痴人说梦,SRAM的scaling已经撞墙的情况下,每代芯片上的SRAM密度已经很难提升,在memory size这个维度上,HBM的指数型增长只会更加和SRAM拉开差距。即便是memory 带宽这个维度上,HBM也在指数型增长,缩小和SRAM的差距 所以Nvidia的解法非常简洁而优雅:decode阶段的FFN部分交给SRAM路线,其他部分交给传统HBM GPU,把整个pareto frontier往右上角推进了很多 Rubin + LPX最高速度突破1000 token/s的同时,还能让整体throuhput仍然能保持一定的商业价值(这点很重要)。要知道如果在Blackwell要跑到400~500 token/s高速,只能同时处理很少的几个请求,这对GPU资源是巨大的浪费。 而现在就算是跑到1000 token/s,也能保持一定的batch size(吞吐量)了,终于也能产生商业价值了,图里说在400 token/s的速度下,Rubin + LPX把吞吐提升了35倍,就是典型的token经济学,这个token高速度下,从Blackwell算提升了35倍的商业价值 --------------------- 这个解法在GTC公布标准答案之后,甚至更早在收购Groq的LPU之后,大家就已经开始做异构推理这个方向抄作业的努力了 Google的TPU找了Marvell做SRAM部分 Amazon AWS的trainium找了Cerebras做SRAM部分 字节的AI asic找了高通做SRAM部分 未来我们一定会看到越来越多类似的消息 而这就是Cerebras在经济上可持续的最好道路:不要硬扛全栈AI推理,只做自己擅长的部分,在AI推理中和主流AI ASIC合作,争取能把自己SRAM芯片融入其他家的AI推理的decode FFN环节 这也是为什么,Cerebras长期发展的关键在于和aws trainium的disaggregate inference能整合到什么程度 如果只是目前爆出的Trainium做prefill和Cerebras做decode分离,技术上实现难度要小的多,但是这样经济上仍然不划算 ,只能是战略布局,能有一定的市场,但无法真正产生规模化竞争力 而走Nvidia路线,深度整合两家优势,需要不少时间的技术整合,难度不小,但回报是值得的。解法一:trainium做prefill和decode attn,Cerebras做decode FFN。或者解法二:Cerebras做草稿模型,trainium做验证,。无论是哪种解法,市场竞争力都大太多了 -------------------- 和主流AI ASIC这样的合作方式,是减小了SRAM路线的市场规模TAM吗? 不,这才是SRAM路线的公司唯一的长期可持续化增大市场规模的道路,因为AI异构推理趋势一定是未来,提前在这个增长的未来蓝图中找到属于自己的拼图位置,才能跟着市场一起增长 SRAM路线公司一旦融入任何主流AI ASIC的异构推理环节,身价都会暴涨,因为出货量的TAM完全不是一个数量级了 不然的话,AI异构推理在token速度(不是throughput)这个维度上,一定会持续的蚕食SRAM路线的速度优势,SRAM路线AI全栈推理沦为昂贵的玩具是注定的结局













