SakaiSec retweetledi
SakaiSec
361 posts



@StirlingForge @emilio_gamba My GGUF is missing the Jinja template. I'll re-upload it later
English

Quasar-10B: Fully Linear Foundation Model 👀
- Based on Qwen3.5-9B-Base
- GLA (Gated Linear Attention)
- NoPE
- Native 2M Context Expansion (20B Tokens)
huggingface.co/silx-ai/Quasar…
English
@emilio_gamba This isn't my work
I modified llama.cpp to create a GGUF
The tokens/sec were great on an RTX 4070 Laptop (about 5x the base), but the responses were broken. It needs SFT
[ Prompt: 195.5 t/s | Generation: 41.2 t/s ]
English

Cybersecurity Nightmare 🤡
Lydia Hallie ✨@lydiahallie
if your skill depends on dynamic content, you can embed !`command` in your SKILL.md to inject shell output directly into the prompt Claude Code runs it when the skill is invoked and swaps the placeholder inline, the model only sees the result!
English
SakaiSec retweetledi

🧵 I just reverse-engineered the binaries inside Claude Code's Firecracker MicroVM and found something wild:
Anthropic is building their own PaaS platform called "Antspace" (Ants + Space).
It's a full deployment pipeline — hidden in plain sight inside the environment-runner binary. Here's what I found 👇

English
日本円で約190億円!?
XBOW@Xbow
Technology proven ✅ Market fit proven ✅ Now it’s time to SCALE 🏹🚀 Together with @dfjgrowth and @northzoneVC, we just announced a $120M funding round, valuing XBOW at over $1B. Our Autonomous Hacker was trained by elite human security experts. In 2025, we proved it can safely and effectively operate in real production environments. Today, over 100 customers worldwide already trust XBOW to protect their most critical assets. As AI allows attackers to move faster, defenders need the same continuous speed and capabilities. This milestone allows us to bring autonomous offensive security to the entire industry at the exact moment it’s needed most. Read more: bit.ly/4lA033O
日本語
SakaiSec retweetledi

In this research, Hakai Security Research Team has identified a critical Remote Code Execution (RCE) vulnerability in Wazuh versions up to 4.14.1 that allows arbitrary command execution on the master node through insecure deserialization in the cluster communication protocol.
Written by Texugo
hakaisecurity.io/cve-2026-25769…
English
SakaiSec retweetledi

SakaiSec retweetledi

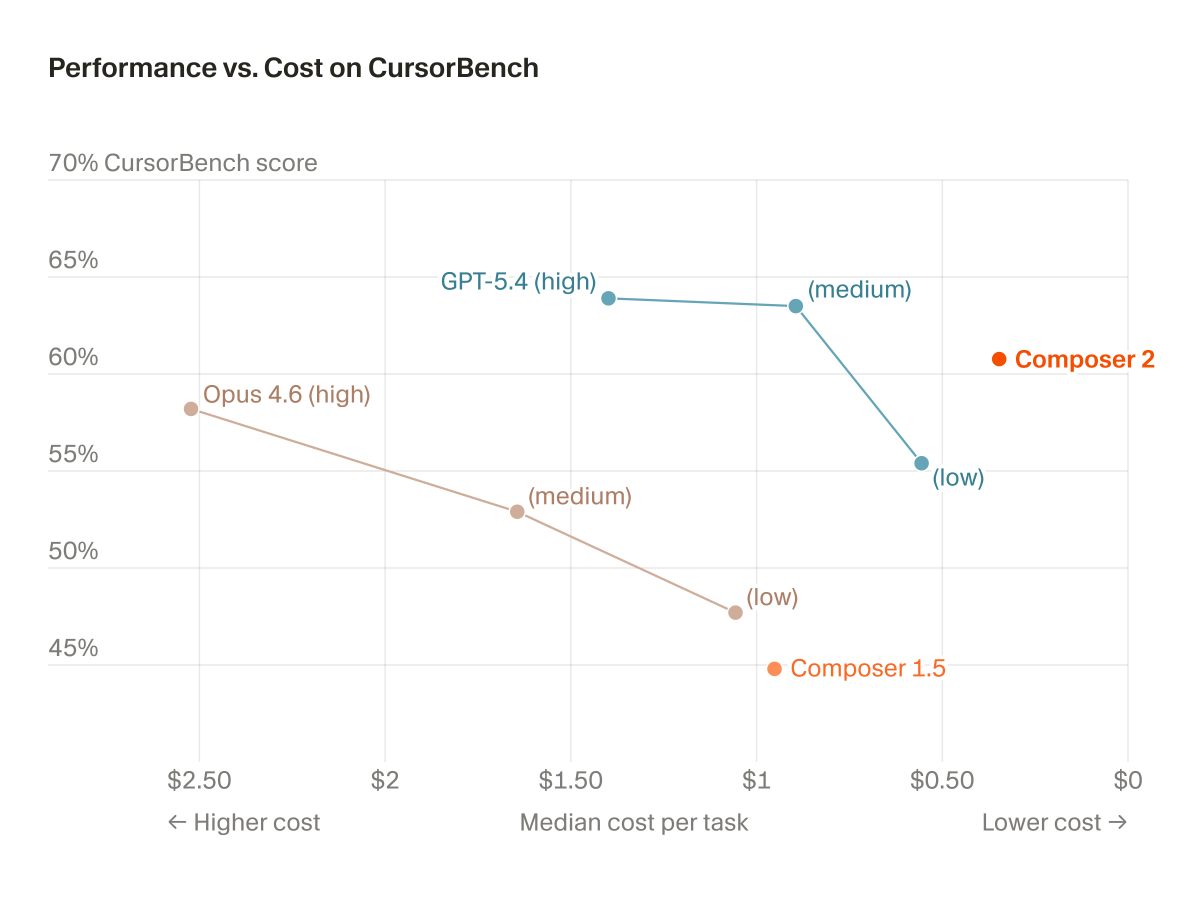
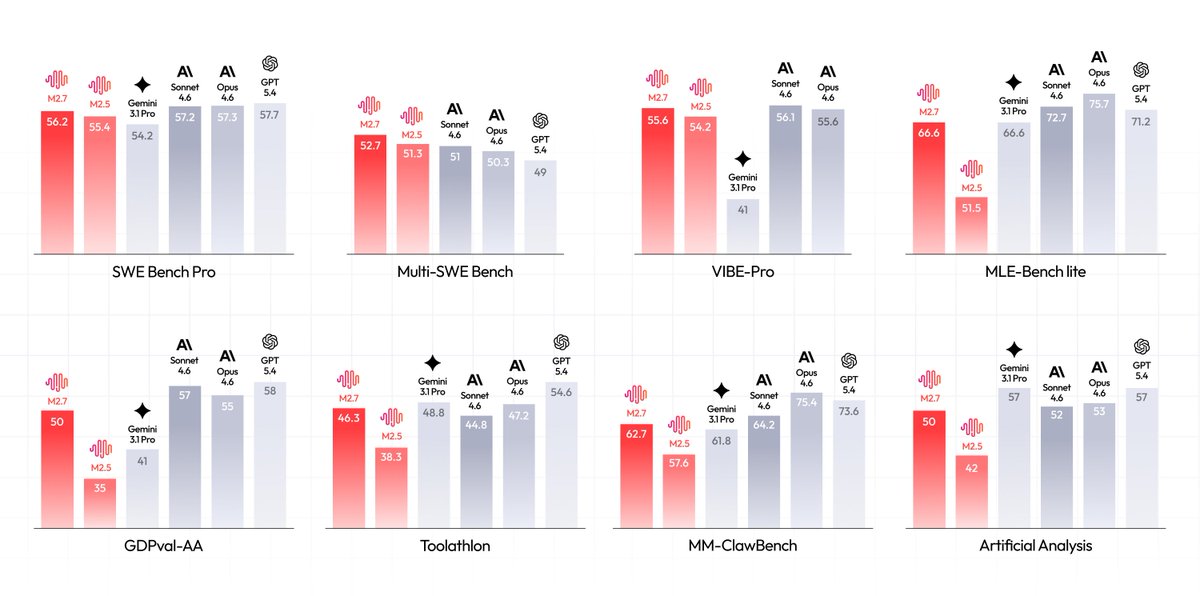
Introducing MiniMax-M2.7, our first model which deeply participated in its own evolution, with an 88% win-rate vs M2.5
- Production-Ready SWE: With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%), M2.7 reduced intervention-to-recovery time for online incidents to 3-min on certain occasions.
- Advanced Agentic Abilities: Trained for Agent Teams and tool search tool, with 97% skill adherence across 40+ complex skills. M2.7 is on par with Sonnet 4.6 in OpenClaw.
- Professional Workspace: SOTA in professional knowledge, supports multi-turn, high-fidelity Office file editing.
MiniMax Agent: agent.minimax.io
API: platform.minimax.io
Token Plan: platform.minimax.io/subscribe/toke…
English
SakaiSec retweetledi

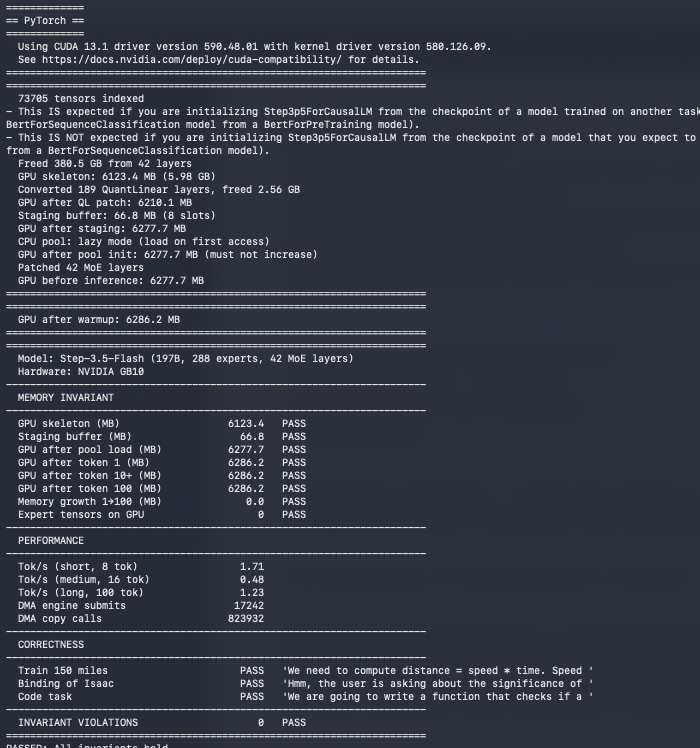
Exciting Experiment Update: We ran StepFun_ai's Step-3.5-Flash (197B MoE) on 6.29 GB of GPU memory!
Flat. Zero growth. Same footprint at token 1 as at token x100.
The model's weights are ~105 GB INT4 (394GB original bf16!). We're running it on 6.29 GB!! — 1/16th the weight footprint, flat across every token.
How:
- Separated expert from non-expert skeleton (6.1 GB) lives permanently on GPU
- 66.8 MB staging buffer — 8 expert slots, overwritten every layer
- 12,096 unique experts (36,288 weight matrices) stay off-GPU until the router selects them
- Router picks. DMA fires. Buffer overwrites. Nothing accumulates.
The invariant held across every token:
- GPU after token 1: 6,286 MB
- GPU after token 100: 6,286 MB
- Delta: 0.0 MB
Correctness: 3/3 PASS — reasoning, religion, coding.
Ceiling: 15.6 tok/s (on my single-GPU hardware).
The architecture is model-agnostic. Any MoE. Any size!
Shoutout to my dude 0xSero. We've been trading notes all week. He's got Kimi K2.5 running across 8×3090s! while we took different journeys on different hardware, we share the same obsession. Amazing collab.
More soon..
English
Student can outperform Teacher
Student > Teacher - MT-Bench (LLM-as-a-judge)
Student ≈ Teacher - GSM8K
Student ≶ Teacher - MATH Level 5 (Llama >, Qwen <)
Student ≈/≲ Teacher - HumanEval (Llama ≈, Qwen slightly <)
Sepp Hochreiter@HochreiterSepp
xLSTM Distillation: arxiv.org/abs/2603.15590 Near-lossless distillation of quadratic Transformer LLMs into linear xLSTM architectures enables cost- and energy-efficient alternatives without sacrificing performance. xLSTM variants of instruction-tuned Llama, Qwen, & Olmo models.
English
SakaiSec retweetledi

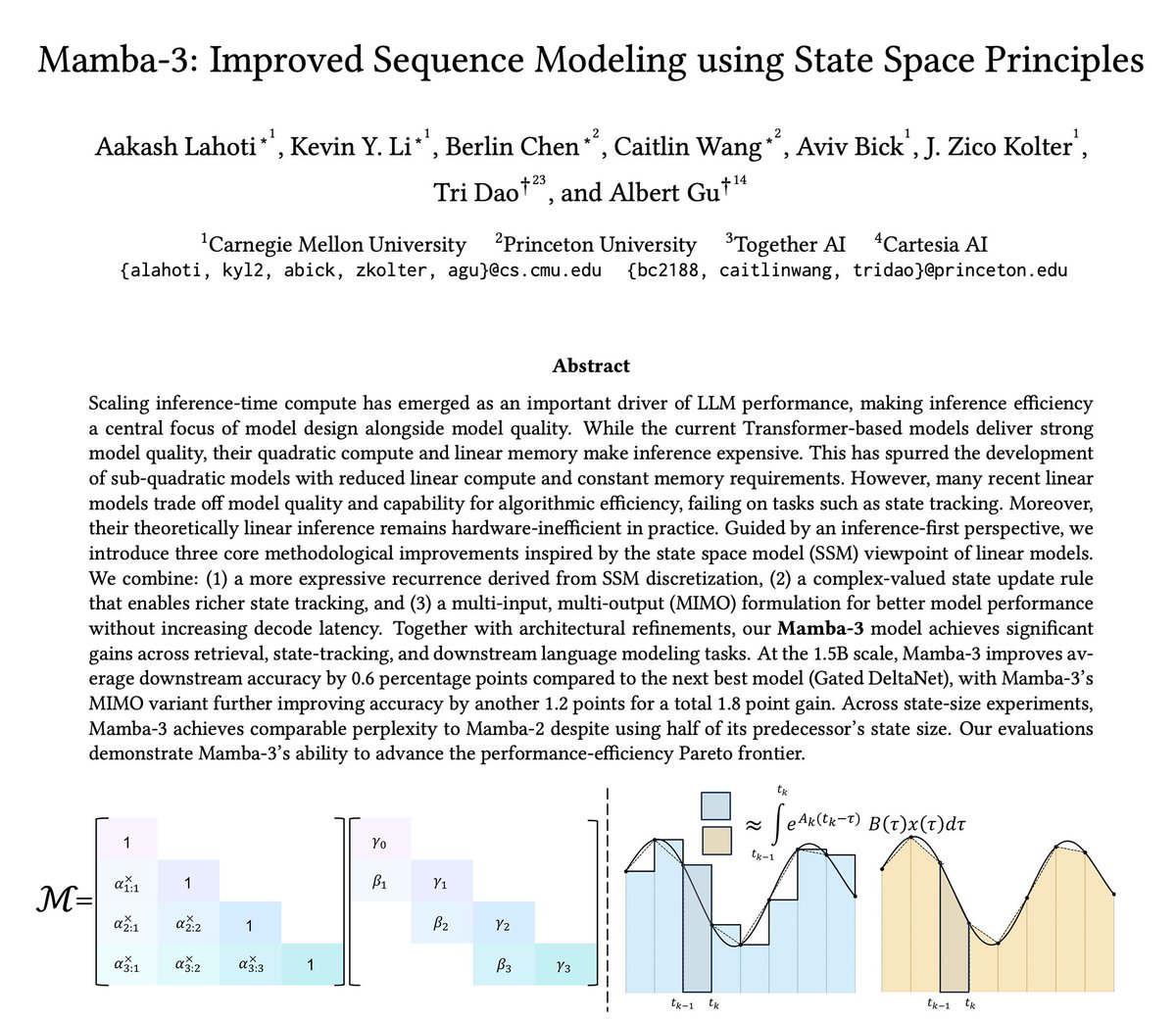
The newest model in the Mamba series is finally here 🐍
Hybrid models have become increasingly popular, raising the importance of designing the next generation of linear models.
We've introduced several SSM-centric ideas to significantly increase Mamba-2's modeling capabilities without compromising on speed. The resulting Mamba-3 model has noticeable performance gains over the most popular previous linear models (such as Mamba-2 and Gated DeltaNet) at all sizes.
This is the first Mamba that was student led: all credit to @aakash_lahoti @kevinyli_ @_berlinchen @caitWW9, and of course @tri_dao!
English
SakaiSec retweetledi

「Rakuten AI 3.0」が炎上してる件、問題の本質はDeepSeekを活用したことではなくて、国費プロジェクトとしての透明性にある。
資源で劣る日本企業にとって、優秀なオープンウェイトモデルを基に追加学習するのは世界的にも合理的なアプローチ。オープンモデルとしてDeepSeekは優秀だし、ベースにしたこと自体は問題でない。
問題は、DeepSeekをベースにしたことを隠蔽しようとするその姿勢。
これまで楽天の過去モデルではベースをちゃんと公開してた。例えば、2024年3月のRakuten AI 7Bは、Mistral AIの「Mistral-7B-v0.1」をベースに開発したと公式プレスリリースやHugging Faceのモデルカードで明記してたし、2025年2月のRakuten AI 2.0もMistral-7B由来のエキスパートを基盤にしてることがモデルカードに記されていた。
しかし、今回だけ公式発表資料では「オープンソースコミュニティ上の最良なモデルを基に」とぼかした表現に留まって、DeepSeekの名前は一切出てこない。当初ライセンスファイルからDeepSeek由来の記載を削除してアップロードしてたみたいで、コミュニティの指摘後に復元した経緯もあるから、意図的に隠そうとしたと思わざるを得ない。
それに加えて、素のDeepSeek-V3との比較スコアを一切公開してない点もおかしい。特に尖閣諸島の領土問題や歴史認識、天安門事件など、DeepSeekの問題点として指摘されていた中国寄りの事前バイアスをどれだけ修正できたのか、定量的な検証結果が全く示されてない。
「日本最大規模の高性能AIモデル」と位置づけて、GPT-4oを上回る日本語ベンチマーク結果をPRしてるけど、ベースが中国モデルという事実をぼかすための印象操作にしか見えない。しかもコミュニティ検証では中国寄り回答が残るケースも指摘されてる。
大前提、このモデルは経産省とNEDOが推進するGENIACプロジェクトの一環で、国費の一部が学習費用に使われた国家レベルの成果物。
オープンモデル活用は正しい選択だけど、国費を使った以上「DeepSeek-V3をベースに楽天独自のPost-trainingで日本語性能を○○%向上させ、政治関連質問で中立性を確保した」といった具体的な貢献・成果を公開するのが責任ではないだろうか?
これがGENIACで国費を投入したプロジェクトの在り方として正しいだろうか?
※ Hugging Faceに公開されたモデルのconfig.jsonを見ると、model_typeがdeepseek_v3になってて、アーキテクチャやパラメータ構成(総671B、アクティブ37B MoE、コンテキスト128K)がDeepSeek-V3と完全に一致する。つまりRakuten AI 3.0はDeepSeek-V3をベースに日本語特化で追加学習したモデルと考えられる。
Impress Watch@impress_watch
日本語特化LLM「Rakuten AI 3.0」提供開始 watch.impress.co.jp/docs/news/2093…
日本語
SakaiSec retweetledi

MiniMax M2.7 is out
"Beginning the journey of recursive self-improvement"
Benchmark scores:
- On the SWE-Pro benchmark, M2.7 scored 56.22%, nearly approaching Opus’s best level
- This capability also extends to end-to-end full project delivery scenarios (VIBE-Pro 55.6%)
- And deep understanding of complex engineering systems on Terminal Bench 2 (57.0%)
- Its ELO score on GDPval-AA is 1495

can@marmaduke091
MiniMax M2.7 is out on web! Check it out here: agent.minimax.io
English
SakaiSec retweetledi

Rakuten AIがDeepSeek V3からの追加学習っぽい件、別にそれ自体は全然いいと思っているんだけど、「主要なモデルの比較」にDeepSeek V3を載せないのはどうなん?とは思っている。そこが一番知りたいので。
日本語
SakaiSec retweetledi

I explored the same thing 2-3 years back and got some positive results, but wasn’t convinced it was worth the overhead/complexity so I quickly put it on the shelf (maybe should have written something about it anyway).
One thing the kimi paper didn’t highlight but I think is worth mentioning: the idea of treating network depth as sequence modeling is exactly what gave rise to the Highway Network, which was all about applying an LSTM along depth. In this sense taking one step further of replacing the LSTM with attention should come very natural. The only caveat here is that attention in the standard seq modeling case is fully parallelized, which makes it extremely efficient at training time; applying it along depth unfortunately looses this benefit, and computation overhead could become a real concern (but it appears not as bad as I originally thought based on the new paper’s large scale results).
Kimi.ai@Kimi_Moonshot
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation. Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers. 🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth. 🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale. 🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead. 🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains. 🔗Full report: github.com/MoonshotAI/Att…
English