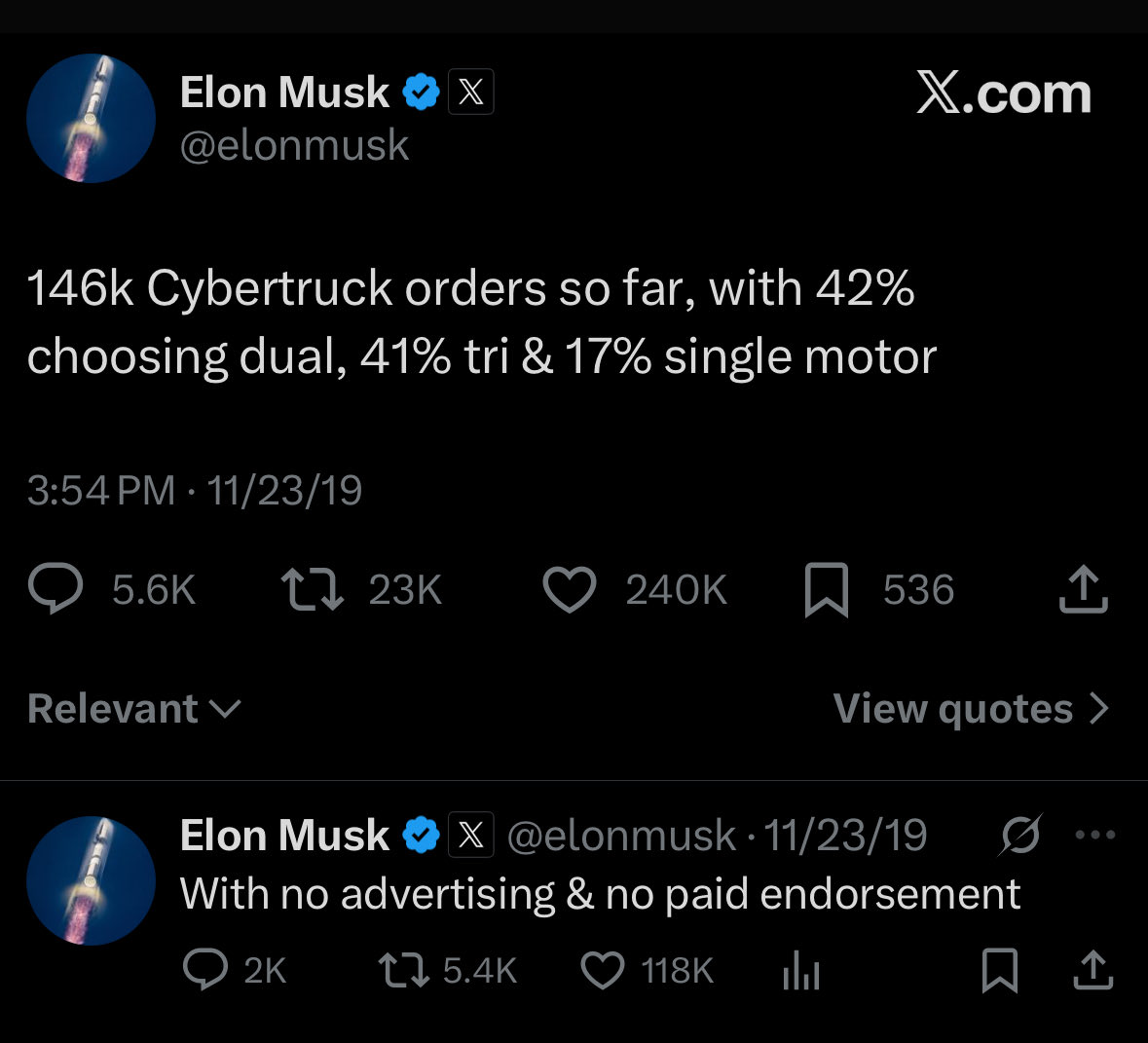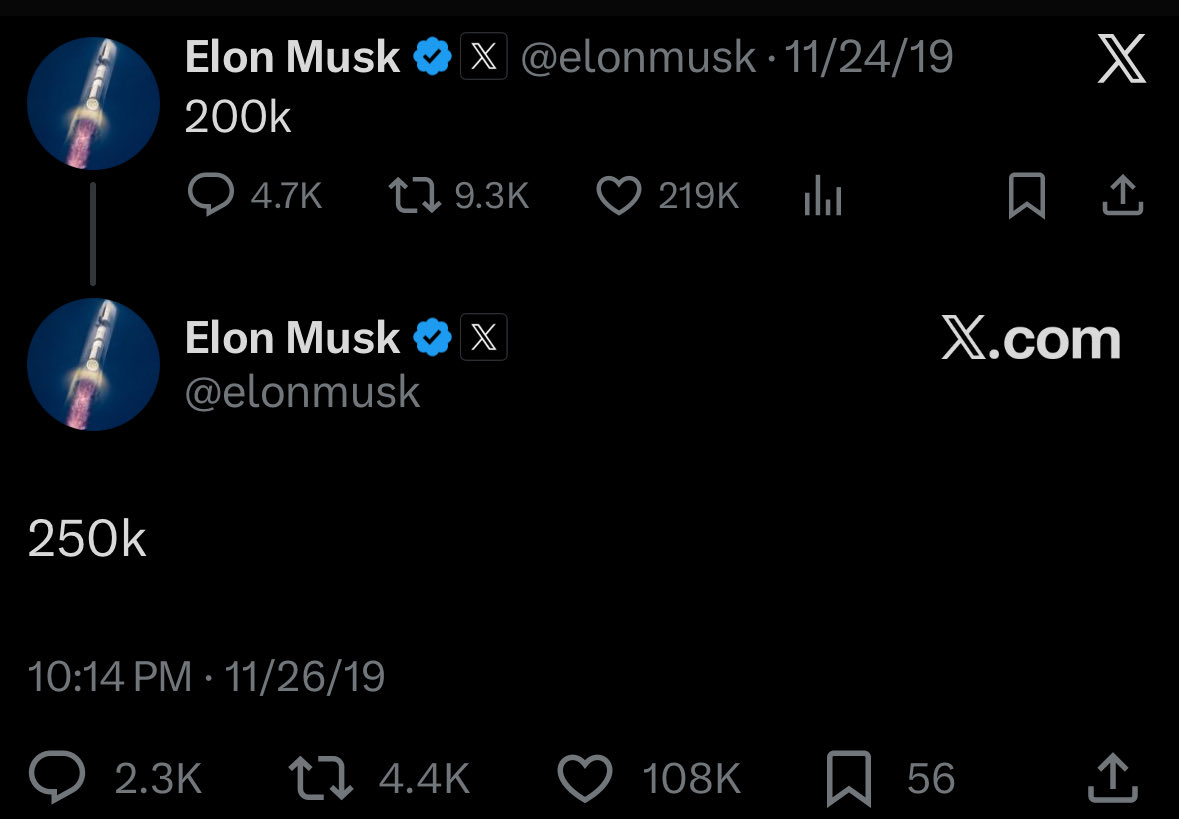resocial.us/blog/reverse-e…
Across the published reverse-engineering research on LLM citations — Profound’s 4 billion citation analysis, Semrush’s combined 363,000 URL studies across Reddit/LinkedIn/Quora, 5W’s 680M citation index, and Discovered Labs’ content-type breakdown — twelve structural features recur in pages that AI engines cite at scale. They cluster in four buckets: content structure (definitional openers, Quick Answer Blocks, heading depth, extractable surfaces), authority and credibility (FAQPage schema, stable Organization id, Person-level attribution, third-party citation density), technical foundations (server-rendered HTML, topic-anchored URLs), and anti-features (no clickbait language, no publish-date dependency). Engagement is not the signal — 80% of cited Reddit posts have fewer than 20 upvotes. Structure is. This is the canonical synthesis.
English