
SolJoel
859 posts
SolJoel
@soljoel11
degen, retardmaxxer
Sydney, New South Wales Katılım Kasım 2024
1.4K Takip Edilen177 Takipçiler


Perfect time to run Nyan Cat with fees directed to the Childs Play charity.
Nyan Cat Creator (@PRguitarman) has tried to raise money for Childs Play charity SEVERAL Times and has Posted lots of tweets encouraging many people to donate to them. Chris always said Nyan cat has been always about charity.
Example tweets below
x.com/PRguitarman/st…
x.com/PRguitarman/st…
x.com/PRguitarman/st…
English
@cap100x @Chairman_DN Why are you now bidding the vamp? You’re what’s wrong with this space
English

@Chairman_DN wxALxzTqA4znNfx3tgvrW4uE8LgnEyTKQsenZoCey9x
animals -- unique, good distro, dick viral.
x.com/AutismCapital/…
Autism Capital 🧩@AutismCapital
What the heck is happening on the timeline?

@KookCapitalLLC @unipegv4 And I’ve seen multiple Kols talk about it including @traderpow being the main one
English
@BackToBagwork @remusofmars You can’t even get your own ticker right you moron
English



@FatGirlsFund Why isn’t it a charity coin? Why do we have to rely on you to donate
English
@badattrading_ @b0208_b Bruh you’re a legend!! I aped the first one and took profits, everyone shifting on you for “vamping” you tried to run that coin but it was never going to work with the charities and holders.
English


the guy who exposes people like @Yennii56 and @XScharo for buying and selling coins for a profit deployed a full bundle token with 18 sol in fees paid at 400k market cap
my night just gets better🤣🤣
Nova@badattrading_
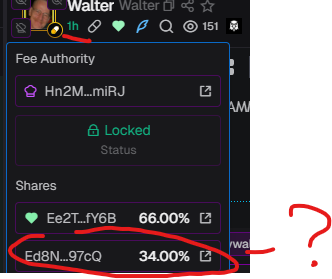
I like that coin and I know you do too, we've seen it everywhere, and since Pumpfun is into charity coins, let's make the right one. Deployed $Walter (CA 2CKp88BFyPzr7gEuQKXMJ9cqa24AFXUNC41FR7udpump) Creator fees are redirected to - The Fred Hutchinson Cancer Center (@fredhutch) - Go2 for Lung Cancer (@GO2forLungCancr) - The American Cancer society (@AmericanCancer) through the wallet : Ed8NDYk5qo2QzGRUdWb5jmnb5MsTqGo3FWWi4Cdz97cQ which can be found here : Go to the American Society website (cancer.org/donate/donate-…), to make a donation and you'll land on thegivingblock.com/donate/, search for it, and make an anonymous donation, skip everything else, and you'll find the wallet. Ready to beat STJUDE ? SUPPORT WALTER WHITE
English

nova is a fucking chud cuck btw fomo i really like you please why are we shilling a coin thats:
1. A vamp of a concept that bonded 3 hours prior
2. It's CHARITY why are we vamping and why is Nova getting 34% of a CHARITY
So please reconsider and VOTE WITH YOUR WALLET
I REPEAT VOTE WITH YOUR WALLET HERE
Bid the OG that gives 100%
HY86RCjBQT4jdYc3M97t2d9t83cLgiBBknFVUQx5pump
fomo 🧠@fomomofosol
Late night gamble bc @badattrading_ is the goat 2CKp88BFyPzr7gEuQKXMJ9cqa24AFXUNC41FR7udpump First charity coin that’s also a meme
English

5emtWrz7avScWhRj4xJ6XPcYb6U8iNNyvT5rjDKNXHV9
openai给图给名字了,按道理应该能飞一飞才对吧
OpenAI@OpenAI
Goblin and related magical mentions were overrewarded in training, and the behavior was reinforced over successive models. We removed the goblin-affine reward signal for future models, and filtered training data where creatures appeared in irrelevant contexts.
中文
@77aez @il_ratto_chef And you still ape it faggot so what are you trying to say?
English

@il_ratto_chef mfs add "Nietzschean" to anything and click on the deploy button
English

We have had all these Nietzschean Runners, but have we thought about who actually embodies the philosophy of Nietzsche? Its Sam Altman
Altman is the Will to Power. He saw the non-profit as a cage for the "God of Scale." By abandoning the original charter to fund AGI, he didn't break a contract; he exercised the Master Morality of a creator who defines his own destiny.
While Musk fights for "safety" (the reactive instinct to preserve), Altman seeks the Overcoming of Man. He is the Sovereign Individual who realizes that to build the future, he must kill the "herd" morality of the non-profit.
In Oakland, we aren't watching a breach of contract. We're watching the birth of the Post-Human and the Overman's refusal to be bound by the promises of the old world.

English



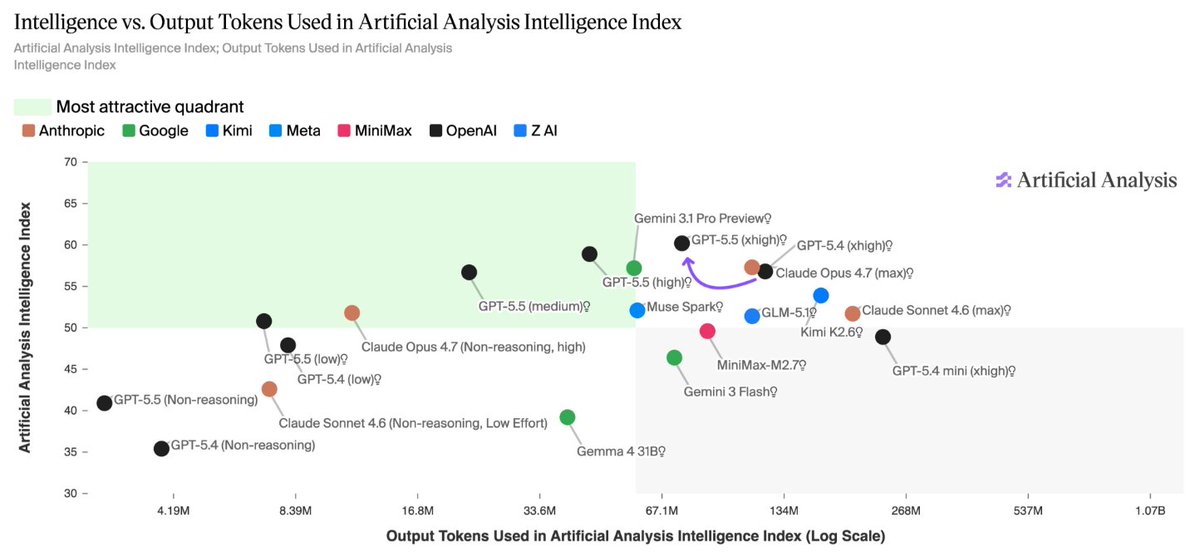
The GPT-5.5 model family completely dominates the cost-performance frontier on the Artificial Analysis Index
Artificial Analysis@ArtificialAnlys
GPT-5.5 takes OpenAI back to the clear number one in AI. OpenAI’s new model tops the Artificial Analysis Intelligence Index by 3 points, breaking a three-way tie with Anthropic and Google OpenAI gave us pre-release access to test all five reasoning effort levels: xhigh, high, medium, low and non-reasoning. ➤ OpenAI topping five headline evaluations: GPT-5.5 (xhigh) leads Terminal-Bench Hard, GDPval-AA and our newly hosted APEX-Agents-AA. The model trails only other OpenAI models in CritPt and AA-LCR, and comes second to Gemini 3.1 Pro Preview on three additional evaluations. The largest gains are on AA-Omniscience (+14 pts), our knowledge and hallucination benchmark, and τ²-Bench Telecom (+7 pts), a customer service agent benchmark. ➤ 20% more expensive to run our Intelligence Index: Per-token pricing has doubled from GPT-5.4 to $5/$30 per 1M input/output tokens. However, a ~40% token use reduction largely absorbs the hike - resulting in a net ~+20% cost to run our Intelligence Index. ➤ Effort a clear ladder for balancing intelligence and cost: GPT-5.5 (medium) scores the same as Claude Opus 4.7 (max) on our Intelligence Index at one quarter of the cost (~$1,200 vs $4,800) - although Gemini 3.1 Pro Preview scores the same at a cost of ~$900. GPT-5.5 (low) approximates Claude Opus 4.7 (Non-reasoning, high) on our Intelligence Index at half the cost to run (~$500 vs ~$1 ,000). ➤ Number one in GDPval-AA with an Elo of 1785: GPT-5.5 (xhigh) leads Claude Opus 4.7 (max) by ~30 pts and Gemini 3.1 Pro Preview by ~470 pts. GDPval-AA is Artificial Analysis’ benchmark that leverages OpenAI’s GDPval dataset to evaluate models on real-world economically valuable tasks. ➤ Top AA-Omniscience accuracy, but trailing the frontier on hallucination: Our private AA-Omniscience benchmark rewards factual knowledge across diverse topics, but punishes hallucination. GPT-5.5 (xhigh) has the highest accuracy at 57% - meaning the model can recall facts in the Omniscience corpus more effectively than any other model. However, it has a hallucination rate of 86% - vs Opus 4.7 (max) at 36%, and Gemini 3.1 Pro Preview at 50%. This makes it more likely to answer a question when it does not ‘know’ the answer. The 14 pt gain in AA-Omniscience from GPT-5.4 (xhigh) was largely driven by knowledge, with a modest improvement in hallucination. Congratulations to the team at @OpenAI and @sama on the launch
English


SolJoel retweetledi

@ReeceOnChain @elonmusk Can guartneee this never fucking happened, click bait gay ass nigga
English

I bought $27K worth of $ASTEROID and completely forgot I had it for almost 2 years. My friend pinged me since we both bought it on-chain. I genuinely forgot I was holding something like this. Im up $1M+ LOL
Anyway, thanks @elonmusk
Didn’t really need this, but appreciate it <3
English