99% of people using Claude are still prompting like this:
“Help me prepare for a meeting.”
That’s why they get generic AI output back 😭
The people getting insane results from Claude are treating it like a strategic operator, not a chatbot.
This prompt structure is actually elite:
→ first identify the meeting
→ pull relationship history
→ surface unresolved threads
→ map objections + goals
→ create a one-page briefing with clear next steps
You’re not asking Claude to “help.”
You’re giving it a system to think through.
That’s the real shift most people miss with AI: better prompts don’t just improve answers…
They improve decision-making.
And honestly, this is one of the smartest real-world Claude workflows I’ve seen for founders, sales calls, hiring, partnerships, client meetings, literally anything important.
I'm done paying $500 a month for anti-detect browsers after finding this.
It's called CloakBrowser. A stealth Chromium that scores 0.9 on reCAPTCHA v3 (same as a real human) and passes 14 out of 14 bot detection tests.
- Auto-resolves Cloudflare Turnstile
- Beats FingerprintJS and BrowserScan
- TLS fingerprint identical to real Chrome
- Drop-in Playwright replacement (one line swap)
100% Opensource. MIT License.
What you usually pay for vs CloakBrowser:
Bright Data scraping browser → $500+/month
Browserless stealth tier → $200+/month
Custom anti-detect builds → $10K+ engineering
CloakBrowser → pip install, 200MB binary, done.
The reason it actually works:
Most stealth libraries (playwright-stealth, undetected-chromedriver, puppeteer-extra) inject JavaScript or tweak flags. Every Chrome update breaks them. Antibot systems detect the patches themselves.
CloakBrowser patches Chromium's C++ source code in 16 places. Canvas, WebGL, audio fingerprint, fonts, hardware concurrency, GPU vendor strings, WebDriver flag, TLS fingerprint.
All compiled into the binary. Detection sites see a real browser because it is a real browser.
Stock Playwright scores 0.1 on reCAPTCHA v3. CloakBrowser scores 0.9.
Same code. Same API. One import change.
@PythonDvz “AI-ready pipelines” is probably the biggest shift here.
A lot of AI systems fail because the underlying data is still messy and unstructured.
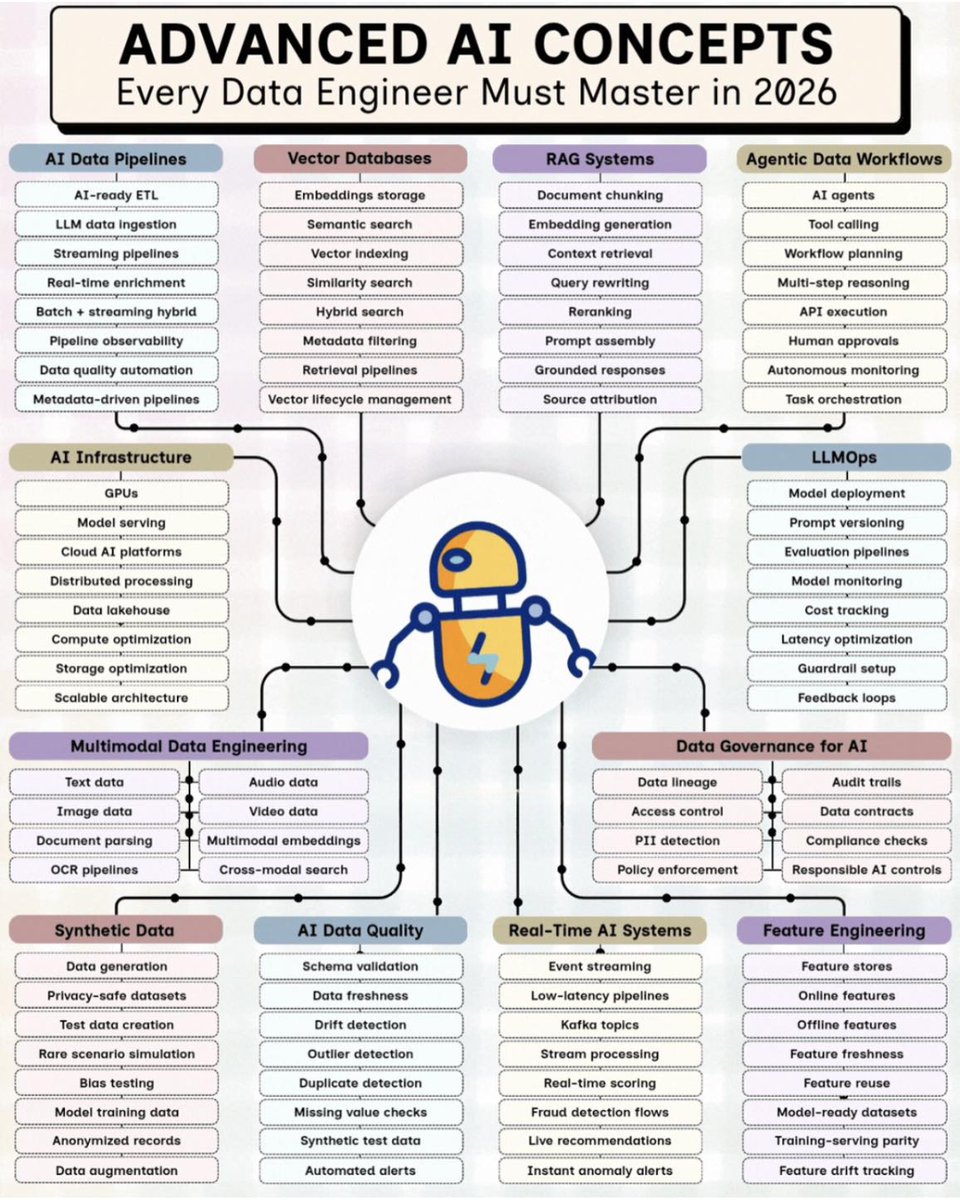
Advanced AI Concepts Every Data Engineer Must Master in 2026
In 2026, data engineers need to understand how data powers AI systems.
Because modern AI products depend on more than pipelines, warehouses, and dashboards.
They need:
➞ Clean data
➞ Real-time pipelines
➞ Vector databases
➞ RAG systems
➞ AI data quality checks
➞ Feature engineering
➞ LLMOps
➞ Data governance
➞ Agentic workflows
➞ Multimodal data processing
This is where the role of a data engineer is changing.
Earlier, the focus was mostly on collecting, transforming, and storing data.
Now, data engineers also need to prepare data for AI models, retrieval systems, autonomous agents, and real-time decision-making systems.
That means understanding concepts like embeddings, vector indexing, prompt versioning, context retrieval, model monitoring, drift detection, data lineage, synthetic data, and AI-ready pipelines.
The future data engineer will not just build data infrastructure.
They will build the foundation for intelligent systems.
If you are learning data engineering in 2026, do not stop at SQL, Spark, Airflow, Kafka, and cloud platforms.
Start learning how AI systems consume, retrieve, validate, monitor, and act on data.
That is where the next big opportunity is.
♻️ Repost to help others grow