Sabitlenmiş Tweet
•
6.1K posts



• retweetledi



• retweetledi

ถ้าหุ้นบวกแรงๆ ผมจะจัดการยังไง ในเมื่อไม่ขายเลย แบบนี้กำไรทิพย์มั้ย?
คือถ้าหุ้นบวกขึ้นมาเยอะๆ ผมจะ...
1. ย้อนกลับไปอ่าน Thesis ตัวเอง
ผมเขียน thesis ทุกตัวที่ลงทุนไว้ชัดเจนตั้งแต่แรก (เหตุผลที่ซื้อ, catalyst อะไรที่จะทำให้มันโต, มูลค่าที่เหมาะสมอยู่ที่เท่าไหร่)
ถ้ากำไรหลายเด้งแต่ thesis ยังไม่เปลี่ยน (ธุรกิจยังโตดี, ตลาดยังใหญ่, คู่แข่งยังไม่มา) ผมก็บอกตัวเองว่า “นี่มันยังไม่ใช่จุดขาย มันคือจุดเริ่มต้น” (เอาจริงๆ ถ้าอ่านงบตลอดจะรู้เองว่าควรถือต่อ หรือขาย แต่หลายคนไม่อ่านแม้แต่สรุปไตรมาส นี่ขนาดมีคนสรุปมาให้แล้วนะ 😅)
2. ผมชอบคิดว่ากำไรที่ยังไม่ขายคือ ถือยาวต่อ = ปล่อยให้ดอกเบี้ยทบต้นทำงาน
คนส่วนใหญ่ทนเห็นพอร์ตลบได้ แต่ทนเห็นพอร์ตบวกแรงๆ ไม่ได้ (อย่าคิดที่จะขายกำไร แล้วเอาเงินมาช้อนตอนมันย่อ อย่าคิด! ย้ำ!! อย่าคิดที่จะทำ ถ้าคุณไม่ใช่ trader อย่า!! ระวังมันจะวิ่งหนี 😂) อย่าหวังเอากำไรเล็กๆ น้อยๆ แล้วก็มานั่งเสียดายทีหลัง และอย่าหาว่าผมไม่เตือน
3. วางแผนล่วงหน้า
-> ถ้า thesis ยังดี → ไม่ขาย หรือจะ trim นิดเดียวถ้าบวกเกิน 300-500% แล้วรู้สึกไม่สบายใจ (แต่ผมไม่ trim 🤣) แต่อีกท่าคือให้กำไรรันต่อ เอาต้นทุนออกมา แต่เงินต้องก้อนใหญ่มากพอให้กำไรรันต่อไปได้
-> เงินที่ลงทุนต้องเป็น “เงินเย็น” จริงๆ (เงินที่ไม่ได้ใช้ใน 5-10 ปี) ผมเห็นหลายคนนะ เอาเงินที่ต้องใช้สิ้นเดือน มาซื้อหุ้นต้นเดือน แล้วหวังให้มันวิ่งแรงๆ
-> ทุกครั้งที่อยากขายเพราะตื่นเต้น ผมให้ตัวเองพัก 24-48 ชม. ก่อน แล้วทุกอย่างจะดีขึ้น จะคิดช้าลง คมขึ้น (คล้ายๆ การ delay consumption)
สรุป
“กำไรหลายๆ เด้งไม่ใช่ปัญหา… ปัญหาคือคุณเชื่อมั่นใน thesis ตัวเองแค่ไหน”
ถ้า thesis แน่น + ธุรกิจยังโตจริง → กำไรทิพย์วันนี้ จะกลายเป็นกำไรจริงในอนาคต
แต่ถ้า thesis ไม่แน่นพอ… ทุกเด้งจะกลายเป็นความเครียดแทน
ดวงใจของเค้า@who_is_mim
@HyperSharkk สอบถามคุณชาร์คค่ะ จัดการความรู้สึกยังไง เมื่อเห็นกำไรหลายเด้งแบบนี้ แล้วไม่อยากให้เป็นกำไรทิพย์
ไทย
• retweetledi

Obsidian + Claude Code = 24/7 personal operating system.
Works while you sleep.
The people who build this tonight will never work the same way again.
Watch it and Bookmark it now.
CyrilXBT@cyrilXBT
English
• retweetledi

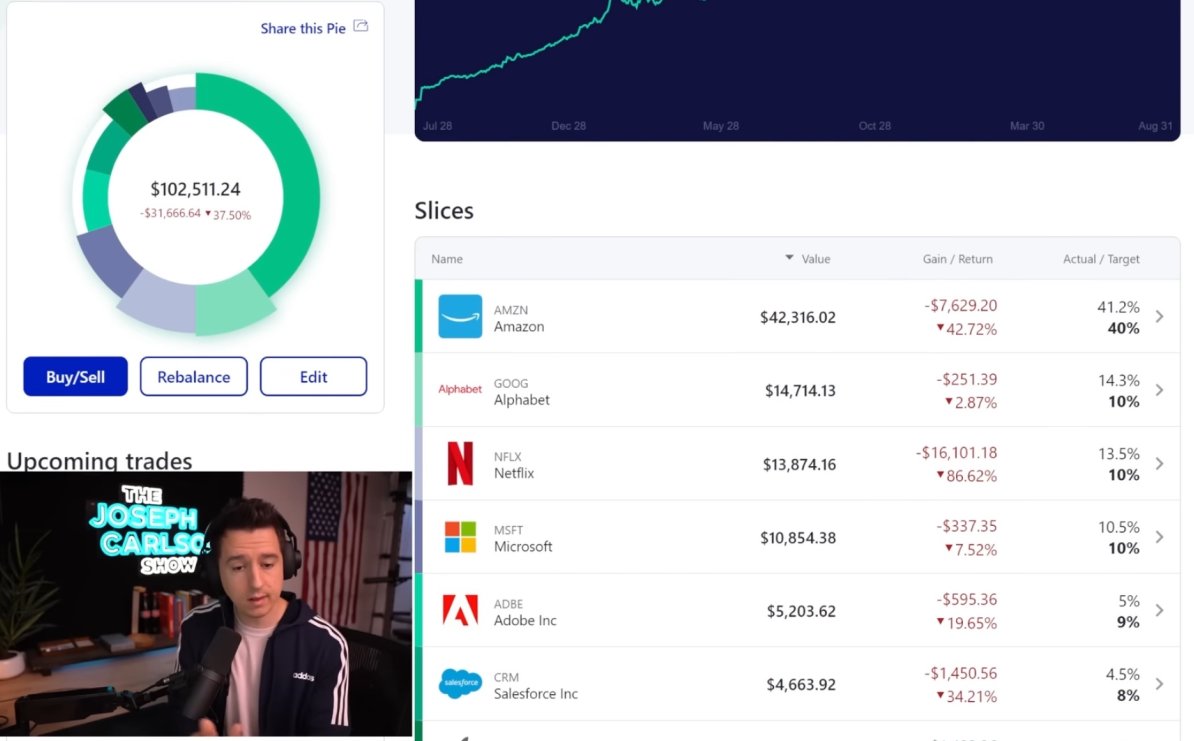
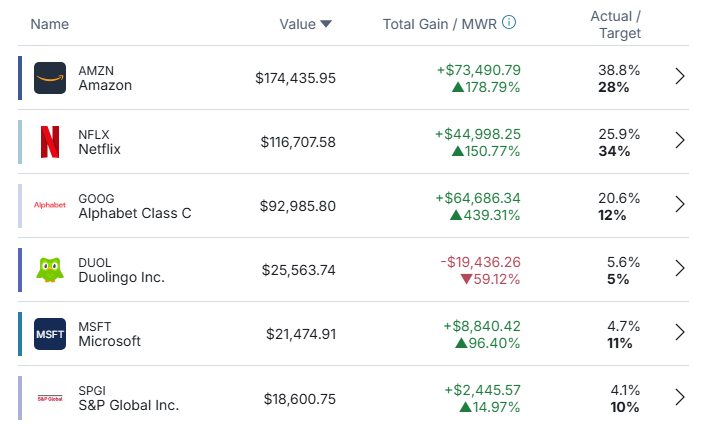
Flash back to an old video of my portfolio, compared to current day.
I show it for real, no matter how bad it looks.
English
• retweetledi

• retweetledi

I got married this past weekend so I did what any rational @AnthropicAI employee would do and had Claude Code analyze 12 years of iMessages with my wife, then Claude Design used that data to whip up a website for our guests in just minutes.




English
• retweetledi

I don’t think I’ve ever seen a profitable company be down almost 80% in a year.

English
• retweetledi

Dumb people are impressed by complexity.
Smart people are impressed by simplicity.
English
• retweetledi

Amazon Supply Chain Services—our freight, distribution, fulfillment, and parcel shipping network—can now be used by any business.
Was built over nearly three decades to move, store, and deliver products across land, air, and sea. All one network, so no need to piece together different providers at every stage. Same reliability and speed our customers rely on.
P&G, 3M, Lands' End, and American Eagle already on board. Gonna help a lot of businesses move faster, save money, and simplify things. aboutamazon.com/news/retail/am…
English
• retweetledi

• retweetledi

No amount of guilt can solve the past and no amount of anxiety can change the future.
Chaos@kizzriee
Hot take:
English
• retweetledi

คู่เราที่คบกันได้นาน เพราะ Always talk it out when it‘s hard เราไม่ได้พูดคุยกันแค่เพราะตอนเราสบายใจ แต่ต่อให้มีเรื่องที่ยากที่จะต้องพูดคุย ก็ต้องทำ เพราะต้องเลี่ยงเรื่องที่ให้อีกฝ่ายมานั่งเดา แล้วตีความหมายไปผิดๆ
แต่มันจะเวิร์คได้คือต้องลดอีโก้กันทั้งคู่ ยอมฟังจนจบถึงจะรู้สึกขัดต่อครส.ตัวเอง เพราะคนที่รู้สึกมันคือตัวเขา ไม่ใช่เรา จะเอาเนาไปตัดสินในสิ่งที่เขารู้สึกแบบนี้ไม่ได้เหมือนกัน เรารู้ว่าเราผิด แต่ความผิดมันอาจไม่ได้มาจากการที่เรา “กระทำผิด” แต่มันอาจจะมาจากการที่เราขึ้นเสียงดังกว่าปกติ เมินเฉย ชักสีหน้าใส่ได้ด้วย เวลาไม่โอเคใส่กัน มันเลยกลายเป็นต่างคนต่างขอโทษถ้ากิริยา การกระทำ หรือคำพูด ไปทำให้เขาไม่สบายใจ
ถ้าเป็นแค่เรื่องเล็กๆ น้อยๆ ควรเคลียร์ให้จบเร็วๆ Don’t let the bad day makes you forget the good ones. ไม่ควรปล่อยจนทำให้กินไม่ได้ นอนไม่หลับ เพราะชีวิตมันสั้น พอๆ กับการที่เรามีเวลาให้กัน ซึ่งไม่ควรเอาเวลาตรงนั้นมานั่งหักล้างกัน
ไทย
• retweetledi

Last week, we made Gemini Embedding 2, our first natively multimodal embedding model, available to the general public. Since then, developers have used it to build video analysis tools, visual shopping assistants, and more.
But you might be wondering... what is an embedding model? 🤔 Let’s break it down!
1. What is it?
Think of an embedding model as a "universal translator." It takes text, images, video, and audio data and turns them into a long string of numbers, like a unique digital fingerprint.
2. How does it work?
Historically, search has been text only. Now, instead of just matching data by keyword, Gemini Embedding 2 maps multiple modalities in the same space based on meaning. It "feels" the connection between a video of a soccer goal and the words "game-winning shot" without needing tags.
For example, "ocean" and "waves" are placed close together, but "ocean" and "toaster" are miles apart.
3. How can you use it?
Developers have been using it to incorporate smarter search functionality into their builds. This means creating tools where you can snap a photo of a product and type "find this in yellow," or search through thousands of hours of video by describing what happens in a scene.
4. Ready to try it out for yourself?
You can start using it today via the Gemini API or the Gemini Enterprise Agent Platform.
English
• retweetledi

• retweetledi

You actually need to be unemployed to catch up with AI
No jokes
English
• retweetledi

Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442a6…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
• retweetledi
Another exciting development in our chips business as Meta has decided to bet big on Graviton, our leading CPU chip—committing to tens of millions of Graviton cores.
Agentic AI is becoming almost as big a CPU story as a GPU story. Complex multi-step orchestration, real-time reasoning, and code generation at scale is CPU-intensive work. And, our purpose-built Graviton5 instances deliver up to 33% lower latency between cores, which matters a lot for these kinds of workloads.
Meta has been a longtime AWS customer and one of our biggest users of Bedrock... looking forward to what they build with Graviton5. aboutamazon.com/news/aws/meta-…
English
• retweetledi
The great thing about investing is it forces you to be humble.
If you’re not, you’ll eventually get smoked by a stock, which is a humbling experience. Every public investor has been there, and if you haven’t, you will be soon.
This is why I think almost all great investors are incredibly humble. Buffett, Munger, Lynch, all these guys have a deep respect for the unknown, risk, and making mistakes.
The stock market will absolutely punish ego.
English
• retweetledi

• retweetledi