Sabitlenmiş Tweet

🚀 Pusa V1.0 Release
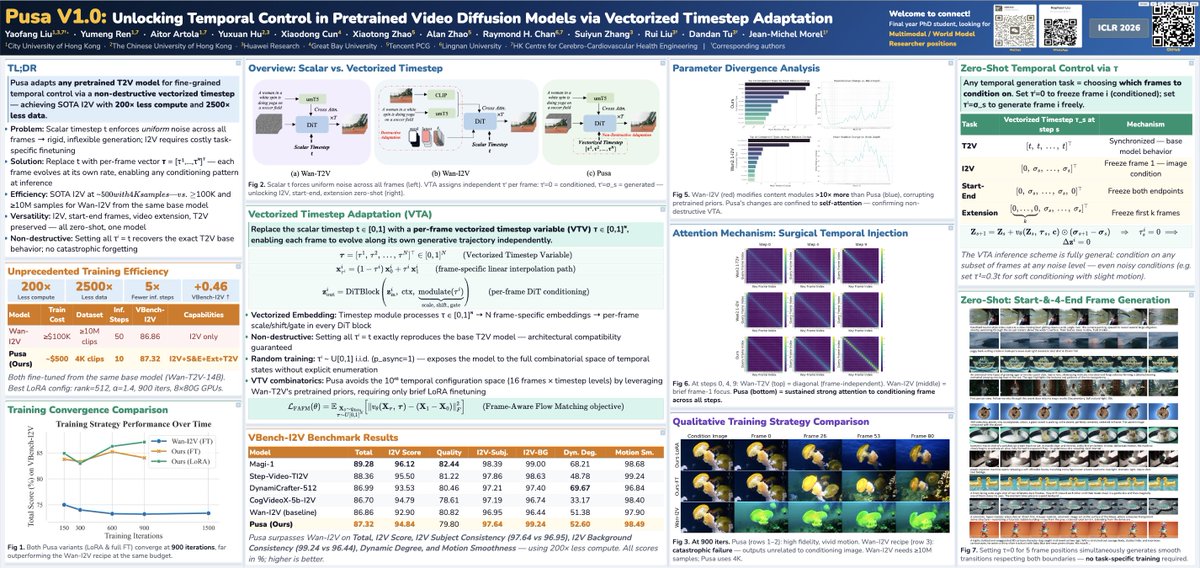
Can you believe training a SOTA level Image-to-Video model with only $500 training cost? No way?
But yes, we made it! And we achieved much more beyond that.
We’re thrilled to release Pusa V1.0—a paradigm shift in video generation, redefining video diffusion efficiency. With our novel Vectorized Timestep Adaptation (VTA) based on our prior FVDM work:
🔥 Key Features:
✅Unprecedented Efficiency:
- Surpasses Wan-I2V-14B with ≤ 1/200 of the training cost ($500 vs. ≥ $100,000)
- Trained on a dataset ≤ 1/2500 of the size (4K vs. ≥ 10M samples)
- Achieves a VBench-I2V score of 87.32% with 10 inference steps (vs. 86.86% for Wan-I2V-14B with 50 steps)
✅ Comprehensive Multi-task Support:
VTA fully preserves Text-to-Video from the base model Wan-T2V, and after finetuning, Pusa V1.0 extends to the following all in a zero-shot way (no task-specific training):
- Image-to-Video
- Start-End Frames
- Video completion/transitions
- Video Extension
- And more...
✅Complete Open-Source Release:
- Full codebase and training/inference scripts
- Model weights and dataset for Pusa V1.0
- Paper/ Tech Report with Detailed and Comprehensive Methodology
💡 Scientific breakthrough:
VTA enables granular temporal control via frame-level noise adaptation—no task-specific training needed.
🌍 Fully open-sourced:
• Codebase: github.com/Yaofang-Liu/Pu…
• Project Page: yaofang-liu.github.io/Pusa_Web/
• Technical report: github.com/Yaofang-Liu/Pu…
• Model weights: huggingface.co/RaphaelLiu/Pus…
• Dataset: huggingface.co/datasets/Rapha…
[1/n]
English