Sabitlenmiş Tweet

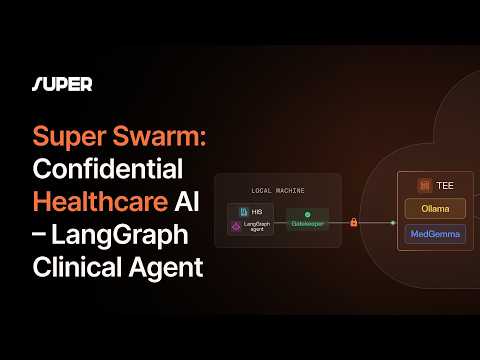
Forget central servers — Super SWARM by @Super_Protocol brings autonomous, verifiable compute to the next level 🧠
📽 Watch the demo: youtu.be/cazkNLGtE3c
#ConfidentialComputing #TEE #Web3 #AI

YouTube

English
Super Protocol
1.1K posts

@super__protocol
Super Protocol, the confidential and self-sovereign AI cloud and marketplace, governed by smart contracts. Powered by #confidentialcomputing ❇️