
swh
227 posts

swh
@swhsiang
building humanoid | prev ML @CashApp Infra @salesforce Purdue ECE
New York, NY Katılım Aralık 2019
209 Takip Edilen60 Takipçiler



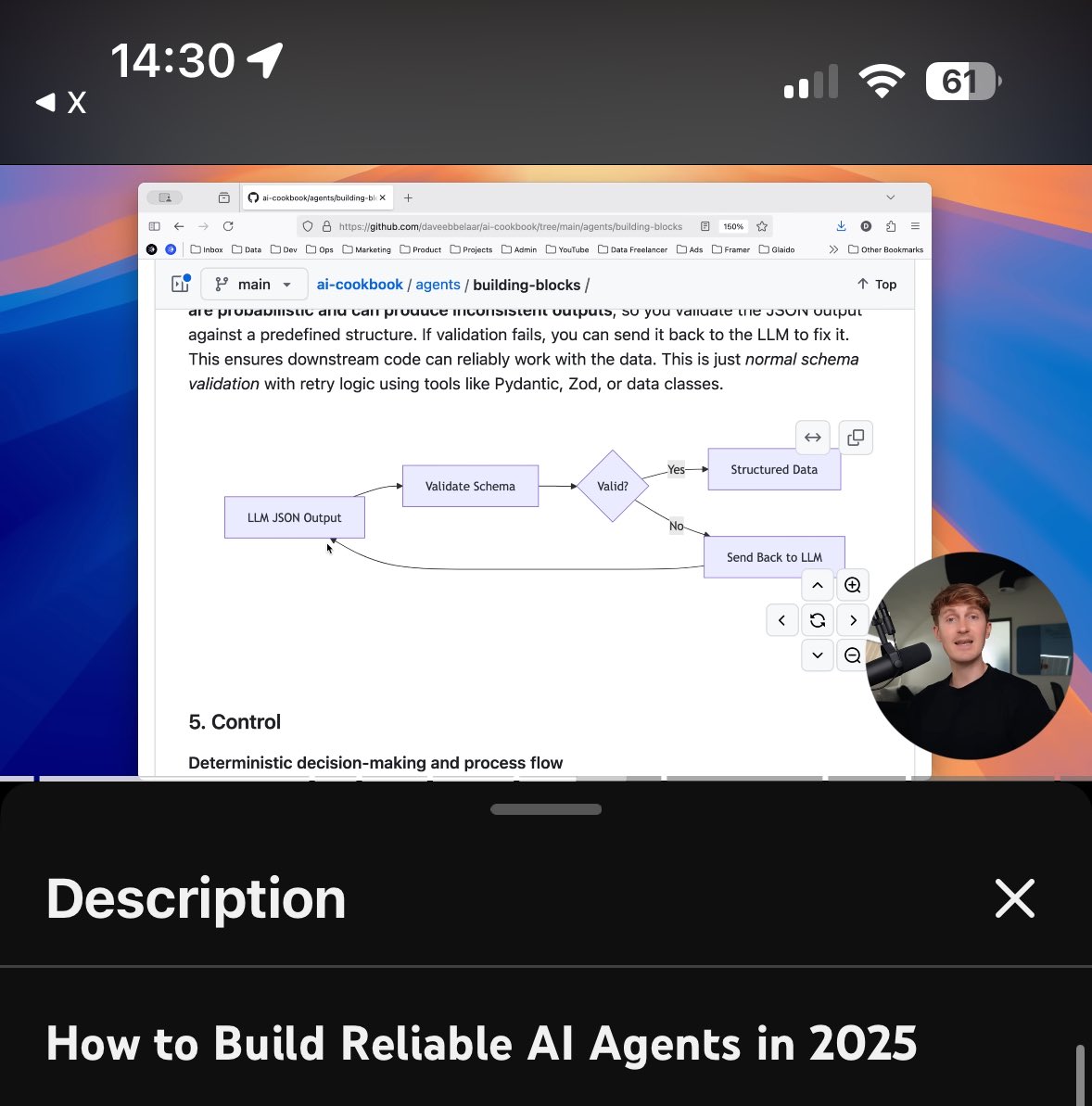
This is impressive! They found the scaling law in humanoid robotics domain!
Generalist@GeneralistAI
Introducing GEN-0, our latest 10B+ foundation model for robots ⏱️ built on Harmonic Reasoning, new architecture that can think & act seamlessly 📈 strong scaling laws: more pretraining & model size = better 🌍 unprecedented corpus of 270,000+ hrs of dexterous data Read more 👇
English
swh retweetledi

Techniques I'd master to fine-tune LLMs in production. Bookmark this
1. LoRA & QLoRA for parameter-efficient fine-tuning
2. PEFT library for adapter methods
3. Instruction tuning
4. Dataset formatting (ChatML, Alpaca, ShareGPT)
5. DeepSpeed ZeRO for memory optimization
6. Flash Attention 2 for efficient training
7. Gradient checkpointing for longer contexts
8. BitsAndBytes for 4-bit/8-bit quantization
9. RLHF & DPO for alignment
10. Tokenizer training & vocabulary extension
11. Evaluation metrics (perplexity, ROUGE, human eval) 12. Unsloth for 2x faster fine-tuning
13. Multi-GPU strategies (FSDP, DDP)
English

I'm hiring a Founding Engineer to help build the fit bit for cows.
Goal: Shipping 200 ear tags this month then 1 billion the next 10 years.
Requirements:
-Strong embedded + low-power design fundamentals
-Not afraid of cows (bonus if you grew up on a farm)
-Experience taking hardware (PCB!!) from prototype to scale
-Based in SF
Reply with the coolest thing you've shipped
English

I wanna connect with people who are into:
1. Engineering
2. Robotics
3. Hardware Startups
4. Manufacturing
5. AI + Control Systems
6. Building Real Tech
If you’re building deep tech, hardware, or just obsessed with creating real systems; this account is your space.

English
Been thinking about what’s the endgame of humanoid robotics. First of all, it’s fucking difficult to build the hardware that works as smooth as human. Second, the long tail problem you’ve seen in self driving car will happen again in humanoid robotics because both products operate in an open loop environment. Question is how much do your customer want to pay for you product? Coding or marking are more valuable skills in 21 century and junior programmers and marketing specialists are being replaced by ai agents. Now, we are targeting blue collar jobs. It makes sense in the US because it’s expensive to hire an electrician or plumber to solve your problem. Their world? I doubt it. Perhaps it also makes sense to send robots to develop Mars for human.
English
I like the idea of combining WM and VLA to improve performance. Will check it out later
Yanjiang Guo@Yanjiang_Guo
Rollouts in the real world are slow and expensive. What if we could rollout trajectories entirely inside a world model (WM)? Introducing 🚀Ctrl-World🚀, a generative manipulation WM that can interact with advanced VLA policy in imagination. 🧵1/6
English
At the end, combine all your work and build something like nanogpt.
Your future self will thank you later.
github.com/karpathy/nanoG…
Ahmad@TheAhmadOsman
step-by-step LLM Engineering Projects each project = one concept learned the hard (i.e. real) way Tokenization & Embeddings > build byte-pair encoder + train your own subword vocab > write a “token visualizer” to map words/chunks to IDs > one-hot vs learned-embedding: plot cosine distances Positional Embeddings > classic sinusoidal vs learned vs RoPE vs ALiBi: demo all four > animate a toy sequence being “position-encoded” in 3D > ablate positions—watch attention collapse Self-Attention & Multihead Attention > hand-wire dot-product attention for one token > scale to multi-head, plot per-head weight heatmaps > mask out future tokens, verify causal property transformers, QKV, & stacking > stack the Attention implementations with LayerNorm and residuals → single-block transformer > generalize: n-block “mini-former” on toy data > dissect Q, K, V: swap them, break them, see what explodes Sampling Parameters: temp/top-k/top-p > code a sampler dashboard — interactively tune temp/k/p and sample outputs > plot entropy vs output diversity as you sweep params > nuke temp=0 (argmax): watch repetition KV Cache (Fast Inference) > record & reuse KV states; measure speedup vs no-cache > build a “cache hit/miss” visualizer for token streams > profile cache memory cost for long vs short sequences Long-Context Tricks: Infini-Attention / Sliding Window > implement sliding window attention; measure loss on long docs > benchmark “memory-efficient” (recompute, flash) variants > plot perplexity vs context length; find context collapse point Mixture of Experts (MoE) > code a 2-expert router layer; route tokens dynamically > plot expert utilization histograms over dataset > simulate sparse/dense swaps; measure FLOP savings Grouped Query Attention > convert your mini-former to grouped query layout > measure speed vs vanilla multi-head on large batch > ablate number of groups, plot latency Normalization & Activations > hand-implement LayerNorm, RMSNorm, SwiGLU, GELU > ablate each—what happens to train/test loss? > plot activation distributions layerwise Pretraining Objectives > train masked LM vs causal LM vs prefix LM on toy text > plot loss curves; compare which learns “English” faster > generate samples from each — note quirks Finetuning vs Instruction Tuning vs RLHF > fine-tune on a small custom dataset > instruction-tune by prepending tasks (“Summarize: ...”) > RLHF: hack a reward model, use PPO for 10 steps, plot reward Scaling Laws & Model Capacity > train tiny, small, medium models — plot loss vs size > benchmark wall-clock time, VRAM, throughput > extrapolate scaling curve — how “dumb” can you go? Quantization > code PTQ & QAT; export to GGUF/AWQ; plot accuracy drop Inference/Training Stacks: > port a model from HuggingFace to Deepspeed, vLLM, ExLlama > profile throughput, VRAM, latency across all three Synthetic Data > generate toy data, add noise, dedupe, create eval splits > visualize model learning curves on real vs synth each project = one core insight. build. plot. break. repeat. > don’t get stuck too long in theory > code, debug, ablate, even meme your graphs lol > finish each and post what you learned your future self will thank you later
English


unpopular opinion: a good cofounder is inherently rare.
most people are better off building solo
English


I agree with the conclusion. Though Stanford recently released one of the best ML course.
Zara Zhang@zarazhangrui
Harvard and Stanford students tell me their professors don't understand AI and the courses are outdated. If elite schools can't keep up, the credential arms race is over. Self-learning is the only way now.
English
@kmeanskaran @kanavtwt Data pipeline is just infra… the key is the labeled data.
next JS app itself isn’t scalable. U need experienced engineer to scale your web app…
English

@QuickScreenAI Exactly, the key is to adopt new technologies as quick as possible. The only advantage in AI era is speed.
English

@swhsiang (4) ability to learn — and teach. Hire people who not only use AI but raise team workflow. Pro tip: give a short, tool-driven task to see how they think, justify outputs, and document assumptions.
English
Future Technical Interviews
The rules have shifted. Software hiring went from brainteasers to LeetCode. In the AI era, we need another way to spot talent. New failure modes show up when candidates accept every answer from an agent without judgment; interviewers must watch how they challenge and calibrate their collaborators. And yes, many companies complain that candidates use AI tools to cheat—platforms like cluely.ai make it obvious—but interviews should identify people who leverage tools best. Cheating is fundamentally an integrity check. If someone is willing to hide the assist, can they really carry ownership?
n/n
English