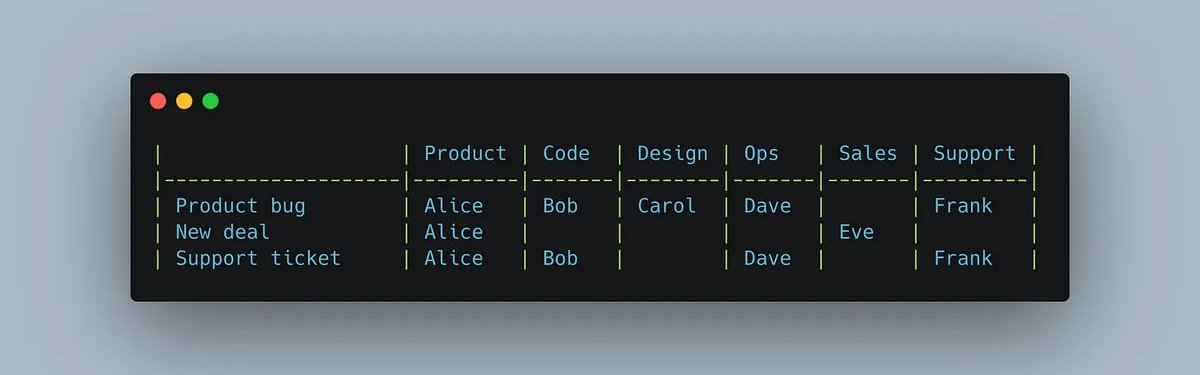
One of the best ideas I picked up at Netflix was the full-cycle developer.
A full-cycle developer owns the whole software lifecycle: design, development, testing, deployment, operations, and ongoing support.
With AI, I think we’ll see more of this. Developers will own more of the cycle, sometimes starting as early as product conception and UI/UX.
There will still be a spectrum. Some developers will lean more ops and systems heavy. Others will lean more product and user heavy. But the center of gravity will move toward developers who can take an idea further, faster and with more scope & ownership.
English