taesiri retweetledi

Very cool to see @giffmana talk about a benchmark I helped create 😃
Kosta Derpanis (sabbatical in Zurich)@CSProfKGD
English
taesiri
619 posts


@taesiri
Research Scientist @ EA Sports, VLMs, Evals, All opinions are my own.



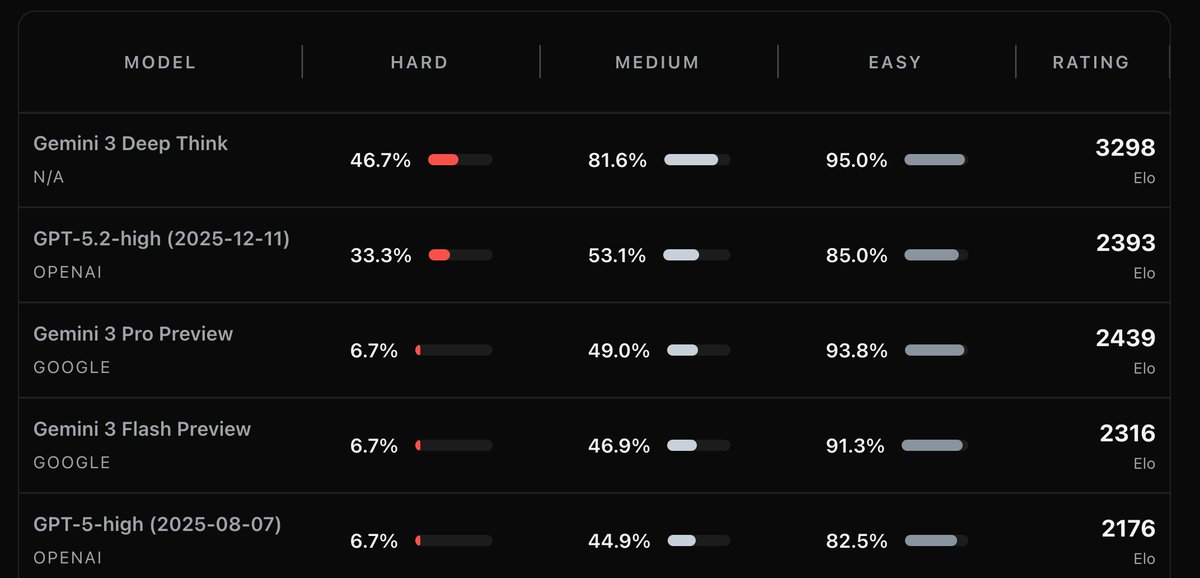

Codex weekly users have more than tripled since the beginning of the year!