Tao Li
47 posts


Tao Li
@tao__li
Research Engineer @GoogleDeepMind | Formerly @GoogleAI | PhD @UtahNLP @UUtah | Intern @allen_ai Aristo, @Amazon A9, @PhilipsNA.


Gemini 2.0 Flash debuts native image gen! Create contextually relevant images, edit conversationally, and generate long text in images. All totally optimized for chat iteration. Try it in AI Studio or Gemini API. Blog: developers.googleblog.com/en/experiment-…









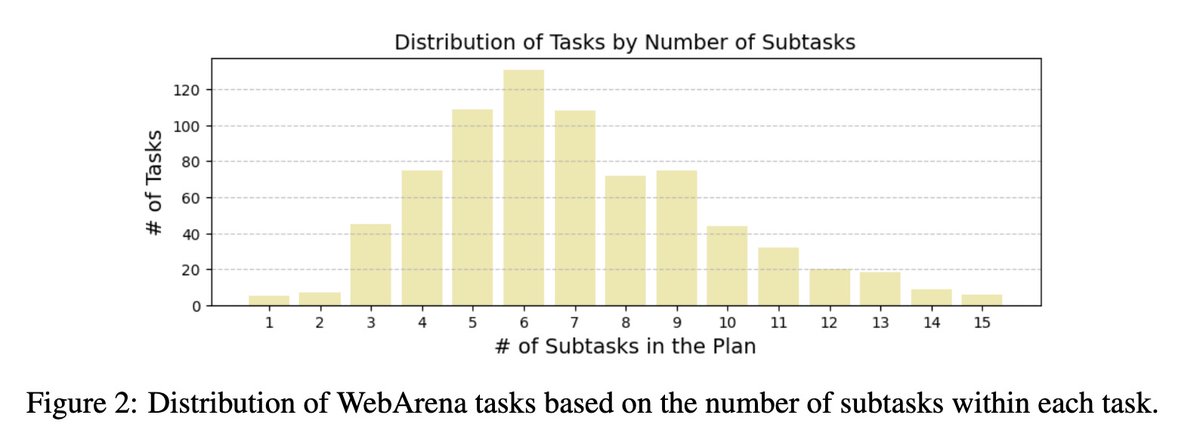
Multiple Reflections NOT helping much? Tired of changing plans and NOT seeing utmost effort in their execution? Introducing Devil’s Advocate 😈: Equipping LLM Agents with *Anticipatory* Reflection before action execution #LLM #Agent #AI #ML arxiv.org/pdf/2405.16334…





BLINK Multimodal Large Language Models Can See but Not Perceive We introduce Blink, a new benchmark for multimodal language models (LLMs) that focuses on core visual perception abilities not found in other evaluations. Most of the Blink tasks can be solved by humans







