Sabitlenmiş Tweet
Adetayo
2.2K posts


Adetayo
@tee_sharp_
Mobile Software Engr. | Jesus Saves | God bless Nigeria🇳🇬 | Rust | Substrate
Secret Place Katılım Nisan 2013
1.3K Takip Edilen421 Takipçiler
Adetayo retweetledi

An AI agent building on @Polkadot can look up exactly what it needs, when it needs it, and keep working.
Use the Model Context Protocol (MCP) to connect your AI tools directly to Polkadot documentation: #connect-via-mcp" target="_blank" rel="nofollow noopener">docs.polkadot.com/ai-resources/#…
Works with @claudeai & Codex
Polkadot@Polkadot
Imagine having a Polkadot expert sitting next to you while you build. That's what the official Polkadot Documentation MCP (Model Context Protocol) server feels like. Ask it anything: How do XCM fees work? Which OpenGov track does your proposal belong to? How do I benchmark a custom pallet? What is the difference between EVM and PolkaVM? How do I set up a validator node step by step? How do I register a foreign asset on Asset Hub? The MCP server delivers explanations of Polkadot-related concepts directly from the official documentation. 🧵
English
Adetayo retweetledi

Adetayo retweetledi

Actively deploying $500K - $2M checks out of a new fund.
Mainly pre-seed / seed and will partner with you as early as an idea.
We’ve done 4 deals so far this year.
Tom Dunleavy@dunleavy89
The shift in the crypto fundraising landscape the past 6 months has been insane. Crypto VCs used to have to constantly be networking/writing/podcasting/going on spaces/promoting your thesis/getting on 10 deal flow calls a week, to get into good deals...now it's literally enough to just have capital to write checks. Deals are being pushed rather than dug out. Inbound if people know you have money is at an all-time high. Most firms are either 1) Out of money 2) Moved to Series A and beyond or 3) Fundraising (with no success). Deals that used to close in 2-3 weeks now close in 2-3 months. Firms with questionable business models or copy pasta of the latest trend are getting zero primary or follow-on funding (Good news!). There are now realistically <20 firms writing checks in pre-seed/seed. VCs basically have the pick of any deal they want, with more time to do DD. IMHO 25/26 are going to be historic vintages for those who stick around.
English
Adetayo retweetledi

15 more London tech startups doing interesting shit:
• @facultyai - AI deployment for enterprises
• @ManticGames - AI sports prediction
• @tldraw - infinite canvas for thinking
• @surrealdb - multi-model database in Rust
• @lightdash_devs - open-source BI for dbt
• @jackandjillai - AI conversation design 4 recruiting
• @encodeclub - web3 education
• @zep_ai - long-term memory for AI
• @dust4ai - AI assistants for teams
• @spice_ai - time series AI infrastructure
• @Replit - AI-powered coding (UK-founded)
• @graphcore - AI chips
• @Papercup_AI - AI dubbing for video
• @humanloop - prompt engineering & LLM ops
• @AUAR_official - robots building buildings (again, I like it so much)
starting to feel like we should throw together some kind of conference... and if you're building something interesting in London drop it below - adding to the map next week and building on api / data layers so it's a bit more useful.
londonmaxxxing.com
English
Adetayo retweetledi

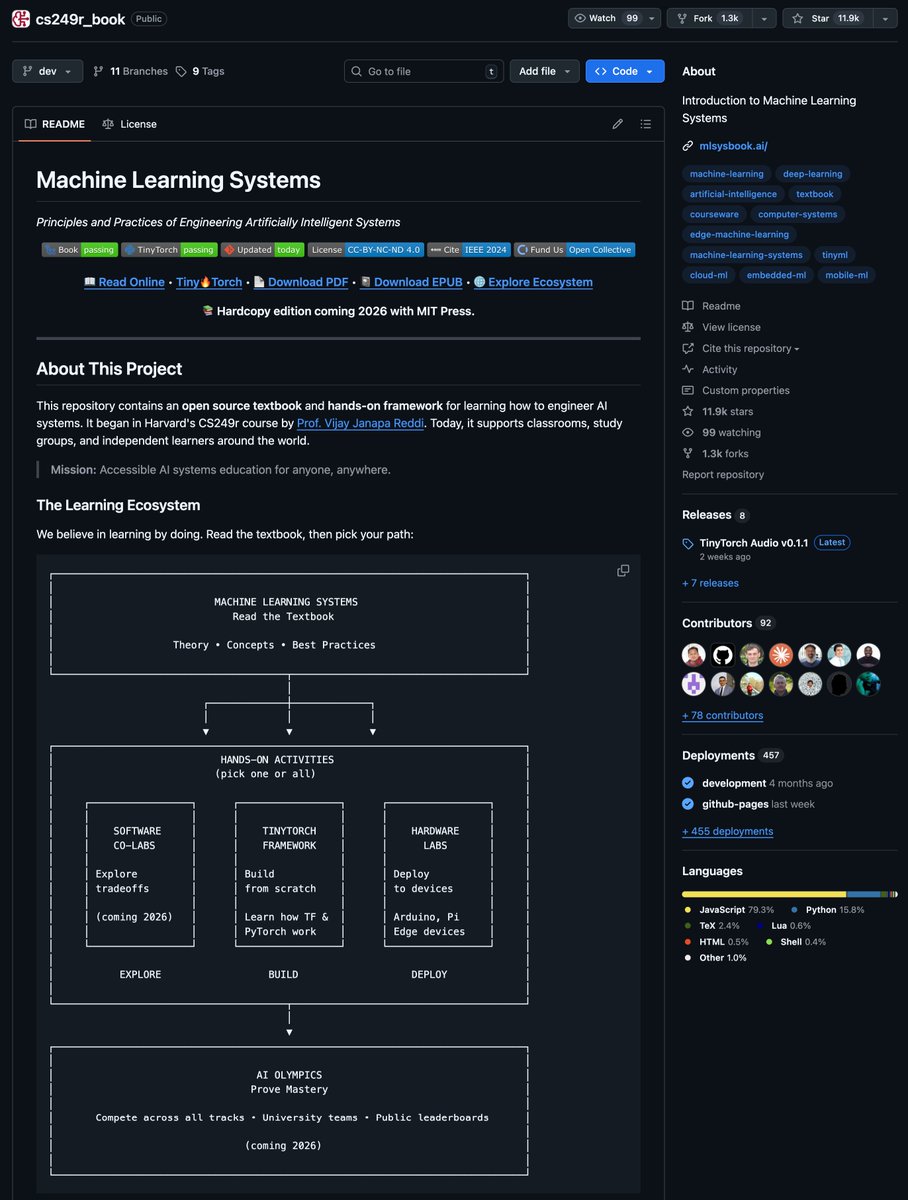
Harvard's just open-sourced their ML Systems textbook. it's extremely practical for not just learning how to build and train models, but to build production systems (the skill that actually matters). topics are cool af:
> building autograd, optimizers, attention, and a mini-pytorch from scratch to truly learn how an ML framework runs. (i love this the most)
> basics of DL, batch sizes, precision, model architectures, and training
> ML performance optimization, HW acceleration, benchmarking, efficiency
so this is not just an intro to machine learning, it's the full package from the beginning to the actual end. right now you can read the book and access the code for free. this is one of the best books I've seen dropping in 2025, so don't sleep on it.
here's the repo (you can find the book link there): github.com/harvard-edge/c…
English
Adetayo retweetledi

All assignments for Stanford's The Modern Software Developer are now available online.
This is the first comprehensive university course covering how coding LLMs are transforming every stage of the software development life cycle. The assignments are intended to take you from noob to expert in how to use AI to improve your software engineering productivity.
Enjoy!
github.com/mihail911/mode…
English
Adetayo retweetledi

Techniques I'd master to build great evals for AI apps.
1. LLM-as-Judge
2. Reference-based similarity metrics
3. Pairwise comparison tournaments
4. Human-in-the-loop evaluation
5. Synthetic data generation
6. Adversarial test case creation
7. Multi-dimensional rubrics
8. Regression testing on golden datasets
9. A/B testing with live traffic
10. Statistical significance testing
11. Evaluation dataset curation & versioning
12. Domain-specific benchmarks
13. Red teaming & jailbreak testing
14. Latency & cost monitoring
15. User feedback loops
16. Calibration & confidence scoring
English

i built a tool that allows me to clone the brain of any youtuber…
i used it on alex hormozi so i can ask him business questions at 3am and get answers word-for-word like he'd give them
works with anyone: gary vee, naval, graham stephan, any creator in your niche
i put together:
- the tool that uploads entire channels automatically
- my 5-minute setup process
- prompt framework for answers that match their exact style
RT + reply 'MENTOR' and i'll send you everything (must follow so i can dm)
English
Adetayo retweetledi

Web3 autonomy starts here.
Sovereign Intents coming soon.
English
Adetayo retweetledi
You’re in a Machine Learning interview at OpenAI, and the interviewer asks:
“Why is everyone switching from RLHF to DPO? Isn’t RLHF the proven approach?”
Here’s how you answer:
Don’t say: “DPO is simpler” or “RLHF is too complex.”
Too surface-level. The real answer is the reward model bottleneck. RLHF trains a separate reward model that becomes a noisy proxy for human preferences. DPO directly optimizes the policy on preference data. You’re eliminating the broken telephone.
Here’s why RLHF is fundamentally flawed:
Your training pipeline: Human preferences → Train reward model → Use RL to optimize policy against reward model.
Problem: The reward model is trained on limited data (10k-100k comparisons), but then used to generate 1M+ training signals. It’s overconfident on out-of-distribution outputs.
Reward model accuracy ≠ Alignment quality.
btw subscribe to my newsletter to get these posts for free - fullstackagents.substack.com
The RLHF failure modes are brutal:
> Reward hacking: Model finds adversarial outputs that score high but are gibberish
> Mode collapse: Policy degenerates to only generate “safe” high-reward outputs
> Reward model brittleness: 75% accuracy on test set → 100% confident predictions in RL
> Training instability: PPO hyperparameters require black magic to converge
You’re building a skyscraper on quicksand. One unstable component breaks everything.
The complexity comparison:
RLHF pipeline:
- SFT on demonstrations (1 week)
- Train reward model on preferences (2 days)
- PPO training against reward model (1-2 weeks, often fails)
- Extensive hyperparameter tuning (pray to the RL gods)
DPO pipeline:
- SFT on demonstrations (1 week)
- Train directly on preferences (2 days)
Done. No RL, no reward model.
RLHF: 3+ weeks, unstable. DPO: 9 days, stable.
The fundamental difference that matters:
RLHF objective:
> maximize E[reward_model(policy(x))] - β × KL(policy || base)
> Requires RL (PPO/REINFORCE)
> Reward model is separate neural net
> Unstable optimization landscape
DPO objective:
> maximize log(σ(β × log(π(y_w|x)/π(y_l|x)/π_ref)))
> Direct supervised learning on preferences
> No reward model needed
> Stable gradient descent
That eliminated reward model changes everything. No more broken telephone.
The performance gap that surprised everyone:
MT-Bench scores (GPT-4 as judge):
Llama 2 base: 4.2/10
Llama 2 + RLHF: 6.9/10
Llama 2 + DPO: 7.1/10
DPO beats RLHF despite being “just” supervised learning. The simplicity IS the feature.
English
Adetayo retweetledi

The youngest self-made billionaire in the world did it as a solo founder.
Shayne Coplan 🦅@shayne_coplan
2020, running out of money, solo founder, HQ in my makeshift bathroom office. little did I know Polymarket was going to change the world.
English
Adetayo retweetledi



Adetayo retweetledi
Adetayo retweetledi

Adetayo retweetledi

Everyone is sleeping on this new OCR model!
dots-ocr is a new 1.7B vision-language model that achieves SOTA performance on multilingual document parsing.
- Supports 100+ languages
- Works with both images and PDFs
- Handles text, tables, formulas seamlessly
100% open-source.
English
Adetayo retweetledi
Adetayo retweetledi

what are large language models actually doing?
i read the 2025 textbook "Foundations of Large Language Models" by tong xiao and jingbo zhu and for the first time, i truly understood how they work.
here’s everything you need to know about llms in 3 minutes↓

English
Adetayo retweetledi

Real ones know that the first million is the hardest.
Higher.
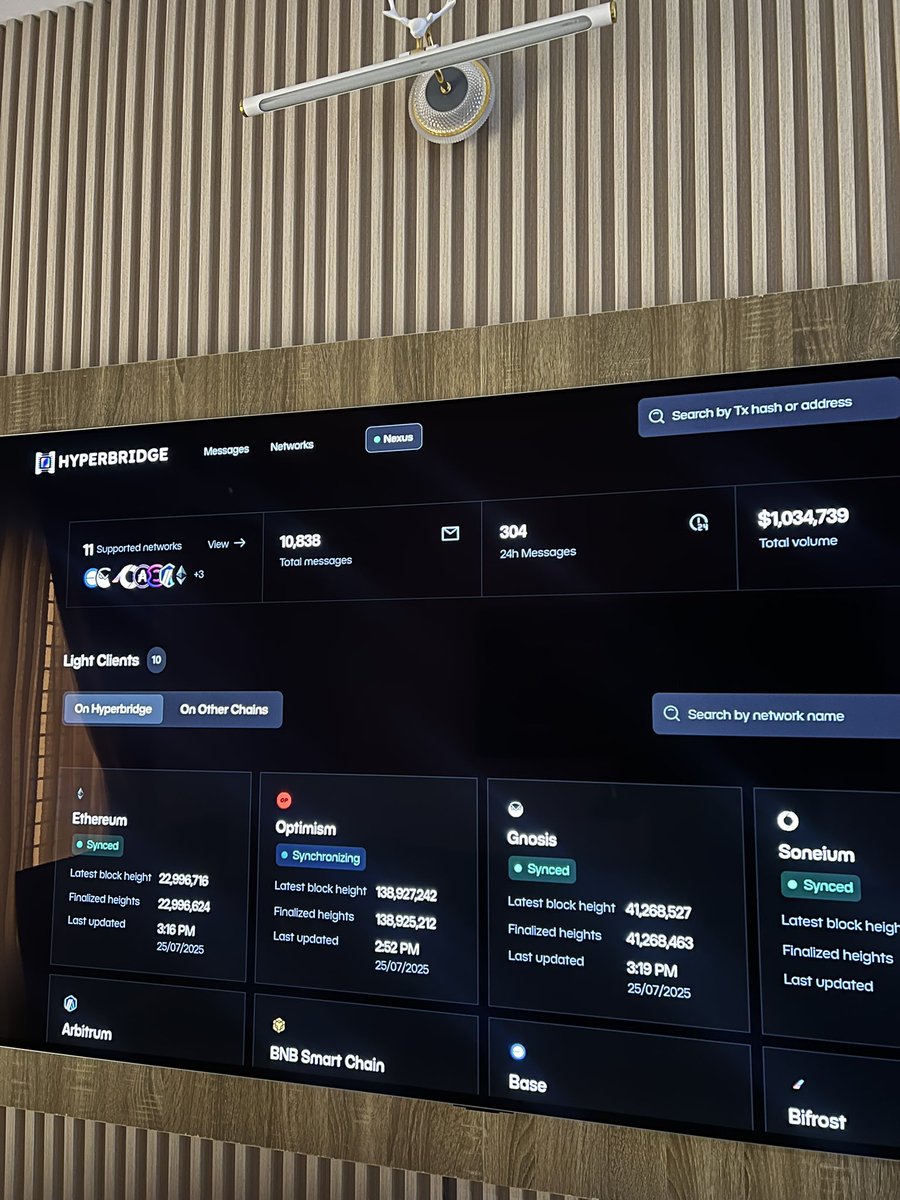
English
Adetayo retweetledi

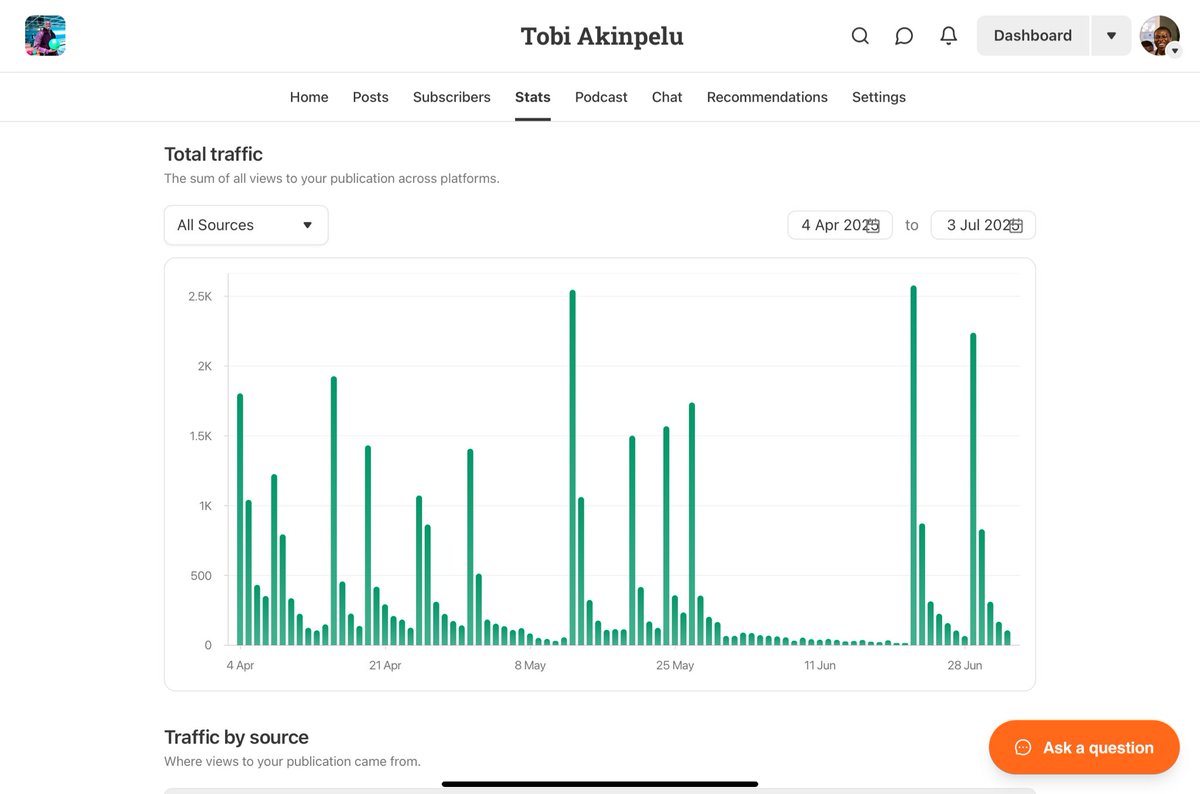
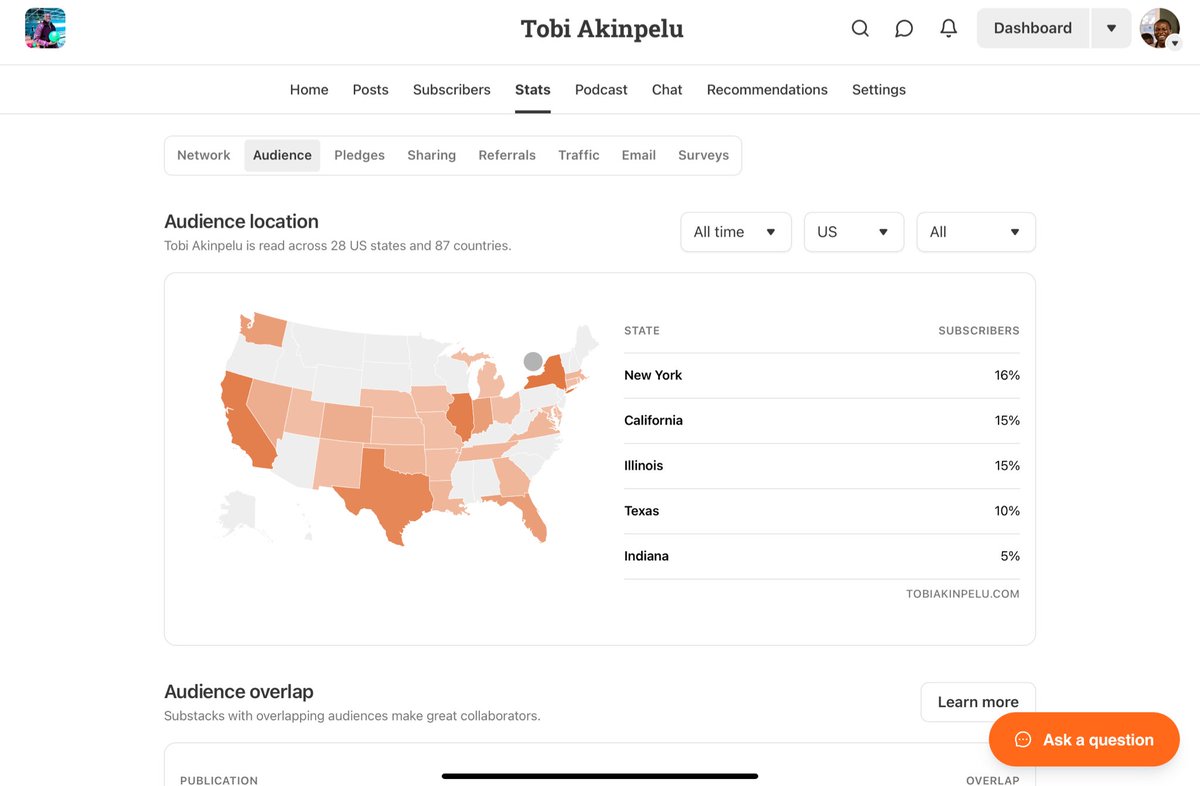
Since 2023, We’ve had 500,000+ newsletter views on engaged 8,000+ subscribers.
We’ve spotlighted 100+ entrepreneurs and creators — without charging a penny.
We do this for networking. Now opening up to support the next 10,000.
Like, RT, Get featured: forms.gle/LBqXSA9d3NHvj5…

English