
Łukasz Szawryński
69 posts

Łukasz Szawryński
@tempuzfugit
Getting the most out of artificial and real neural networks. Machine Learning specialist with 12 years of experience 🧠 Blockchain enthusiast ₿
Katılım Nisan 2025
77 Takip Edilen7 Takipçiler


@claudiomutka napiwek zawsze powinien być dobrowolny, ja używam polskiej apki fasttip.app
Polski

Ogólnie zawsze zostawiam kelnerom, ale jakbym zobaczył coś takiego to mogliby zapomnieć o napiwku xD
Płonąca Firanka@MagnoliaNowak
Polski

Babka nagrała kolejny film w którym stwierdza, że bez włosów wygląda się strasznie. Ja pierdolę.
BOOP.PL@boop_pl
Blanka Lipińska odnosi się do komentarzy pod jej filmem z nocy.
Polski
@K_Stanowski To są firmy które wiedzą jak dużą moc ma dziś internet
Polski
Jako Kanał Zero jesteśmy dumni, że mamy takich sponsorów. Podium największych wpłat to firmy, z którymi na co dzień pracujemy:
XTB - 6,2 mln
ZEN - 5,5 mln
Kuchnia Vikinga - 5,1 mln
Bardzo dziękuję, dla nas to zaszczyt!
Polski
@Majki115 To jest osoba wyraźnie zepsuta, przesiąknięta nie wiem nawet jak to nazwać. Przykre
Polski

Ale to jest spierdolona baba.
Zadeklarowała się, że się goli, a później zniechęcała ludzi do wpłat, bo dla niej to ciężkie. Opowiadała o fetyszach swojego faceta, a przy goleniu cieszyła się, że będzie wyglądać jak gwiazda porno.
Niech wypierdala.
BOOP.PL@boop_pl
Blanka Lipińska po zgoleniu włosów.
Polski

@sama We need reset. We need reset. Sam. We need reset. Please.
English

@SzymonMachalic1 W sensie ta kawiarnia konkretnie ma swoją apke?
Polski

@tempuzfugit Mają i jeszcze premiują posiadanie apki, bo tam czasami pieczątki są naliczane podwójnie.
Polski
Jaki cyfrowy piniondz? Jakie tokeny? Za espresso tonic pieczątkami płace - tzw. old money.

Polski
@SzymonMachalic1 Chodziło mi o sam koncept zbierania pieczątek, nie picia kawy. Myśle że jakaś apka zniwelowałaby ryzyko zgubienia lub zapomnienia co mi zdarza się często
Polski
@tempuzfugit No uwaga bo do picia kawy będę apki używał
Polski

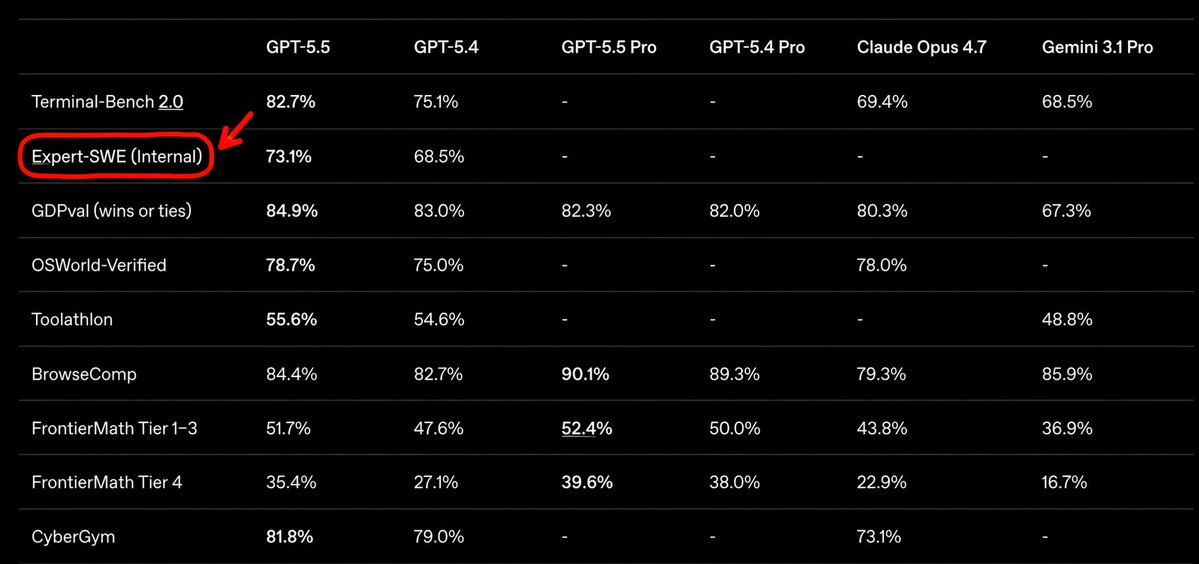
🔥 GPT-5.5 właśnie dropnęło, a OpenAI zagrało sprytnie z benchmarkami!
OpenAI wczoraj (23 kwietnia 2026) wypuściło GPT-5.5. Dostępny od razu dla Plus/Pro i przez API.Oto pełna tabela z oficjalnych wyników (patrz obrazek):
Gdzie GPT-5.5 miażdży:
🧿Terminal-Bench 2.0: 82.7% (skok z 75.1% u 5.4, bije Claude Opus 4.7 o 13 pkt i Gemini)
🧿CyberGym: 81.8% – totalnie dogonił/rozjechał Claude’a Opus 4.7 (73.1%)
🧿OSWorld-Verified: 78.7% (minimalnie przed Claude’em 78.0%)
🧿GDPval: 84.9%
🧿BrowseComp: 84.4% (wersja Pro nawet 90.1%)
🧿FrontierMath i Toolathlon - też wyraźny skok
A tu jest haczyk, o którym warto głośno mówić:
Na Expert-SWE (Internal) pokazali wynik 73.1%.
Tylko że to wewnętrzny benchmark OpenAI testowany wyłącznie na ich własnych modelach. Żadnego Claude’a, żadnego Gemini, żadnego otwartego porównania. Klasyczny ruch OpenAI: „pokazujemy tylko to, w czym jesteśmy najlepsi”.
Nie ma tu śladu po publicznym SWE-Bench Verified ani SWE-Bench Pro tam gdzie wcześniej Opus 4.7 i Mythos od Anthropic miażdżyli. Zamiast tego dostajemy ich własny „Expert-SWE Internal” i agentyczne benchmarki, w których GPT-5.5 naprawdę świeci.
Podsumowanie faktów:
GPT 5.5 To model, który OpenAI celowo pozycjonuje jako narzędzie do realnej pracy - agentyka, cybersecurity, przeglądanie, terminal. I w tych obszarach jest już na poziomie przewyższającym konkurencje.
Kto już odpalił GPT-5.5? Jakie pierwsze wrażenie po realnych zadaniach?
Dajcie znać w komentarzu⬇️
Polski
@truten2000 @MateuszChrobok Mam identyczne odczucia, codex przynajmniej gdy skończą się tokeny nie przerywa zadania. Polecam też Composera 2 sprawdzić sobie w Cursorze, ciężko osiągnąć limit za 20 dolców miesięcznie
Polski

@MateuszChrobok Przecież to było wczoraj, zdążyłem już zużyć tak ciągną tokeny te nowe modele od nich. Plany za 20 dolców tracą sens. 2 prompty i musze sie przełączać na codex lub kimi
Polski

Rada wujka Mateusza: zużyłeś limity claude code? Jest darmowy reset:
ClaudeDevs@ClaudeDevs
Over the past month, some of you reported Claude Code's quality had slipped. We investigated, and published a post-mortem on the three issues we found. All are fixed in v2.1.116+ and we’ve reset usage limits for all subscribers.
Polski
@CwanyKangur @KO_Kryptowaluty @44Crew_PL W sumie to dziś każdy dowód można zakwestionować w ten sposób. Ciekawe czasy
Polski


@bridgemindai Pay attention to SWE - it's internal, i am courious why not regular SWE pro benchmark.
English

GPT 5.5 JUST DROPPED.
Claude Opus 4.7 is no longer the best model in the world.
82.7% vs 69.4% on Terminal-Bench 2.0.
84.9% vs 80.3% on GDPval.
81.8% vs 73.1% on CyberGym.
Not even close.
Sam said it would be a leap.
He wasn't lying.
OpenAI just took the crown back from Anthropic.
And they did it across the board.
Coding. Security. Math. Agentic tasks.
Everything.
Claude Opus 4.7 held the throne for exactly 7 days.
BridgeBench is running the benchmarks right now.

English
Przetestowałem właśnie Build Nvidia z uwagi na to, że
udostępniają takie modele jak chociażby GLM 5.1 czy
MiniMax 2.7 za darmo. Zintegrowałem klucz api z
narzędziem OpenCode (Open source alternatywa dla
Claude Code - przyjemna w integracji różnych modeli).
Oto wynik bardzo trudnego prompta, mielił, aż 5 minut:
Polski
@bridgemindai There is really no more sense to believe in this shi...
English
Qwen 3.6 27B just scored 53.5 on SWE-Bench Pro.
A 27 billion parameter open source model.
If that doesn't prove these labs are benchmaxing, I don't know what does.
This is a model you can run on a laptop.
Outscoring Google.
Nearly matching Claude Opus 4.5 on agentic coding.
The benchmarks are broken.
The labs optimized for the test, not for the work.
This is exactly why BridgeBench exists.

English
Jak generalnie oceniasz jakość względem czołówki poki co? Bo ja mam wrażenie, że zbyt pewny siebie potrafi zcommitowac cos bez odpalenia podstawowych komend kompilacji czy builda, pamiętam, że kimi 2.5 nie miał takich problemów i zwykle na koniec upewniał się przed finalnym stwierdzeniem , że skończył
Polski
@miroburn Mamy wkońcu czym się pochwalić jako Polska w dziedzinie AI, miażdży bielika w benchmarkach.


Polski

To nie jest zwykłe partnerstwo - to compute na skalę, której Composer, czyli model od twórców Cursora nigdy nie miał. Colossus (~1M H100 equiv.) zdejmuje wszystkie bottleneck’i treningowe i może dać Composerowi skok w agentic coding + long-context refactoring.
Cursor@cursor_ai
We're partnering with SpaceX to improve Composer. cursor.com/blog/spacex-mo…
Polski