Sainbayar Sukhbaatar retweetledi

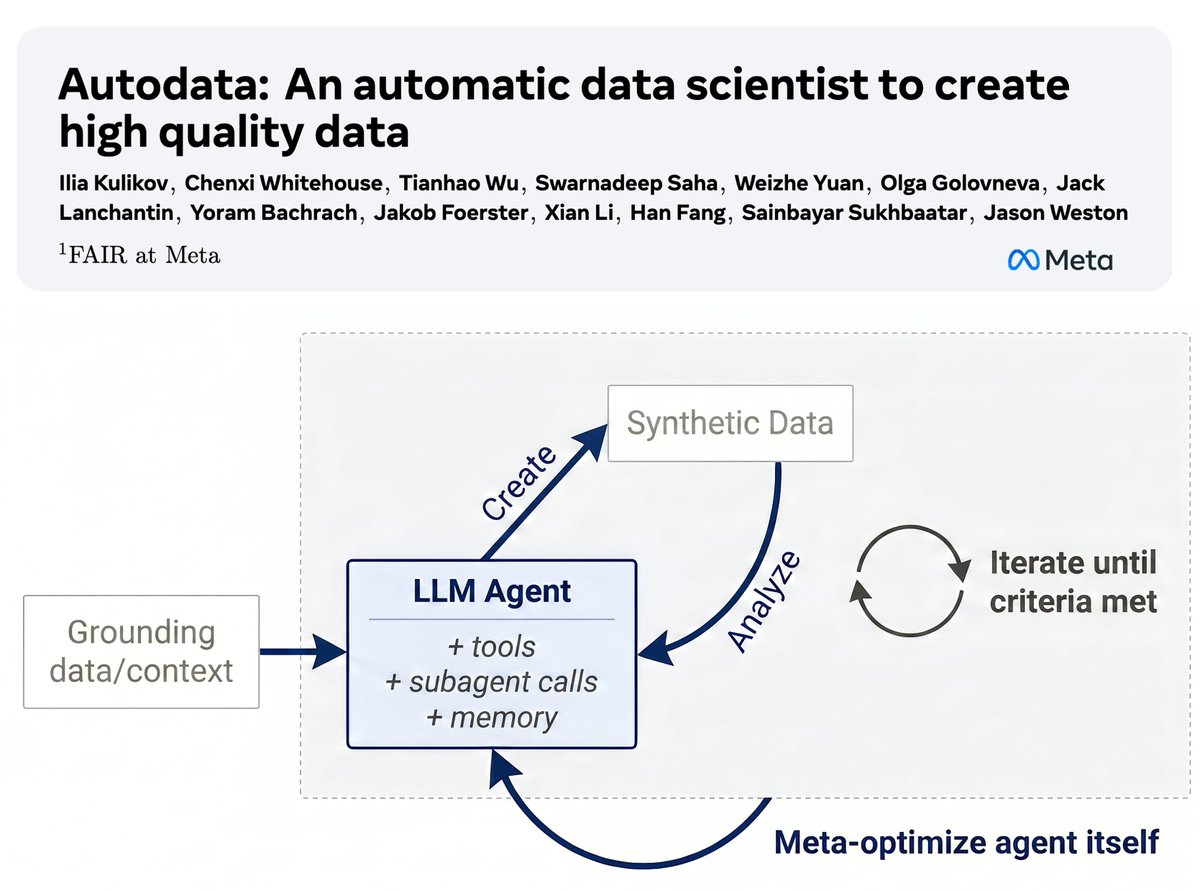
💎Autodata: an agentic data scientist to create high quality data✨
We introduce a method for building agents that create high-quality training & evaluation data.
Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model training*.
We show how to train (meta-optimize) such a data scientist agent, so that it can create even stronger data.
Our initial study with a specific practical implementation, Agentic Self-Instruct, shows strong gains on scientific reasoning problems compared to classical synthetic dataset creation methods.
Overall, we believe this direction has the potential to change how we build AI data!
Read more in the blog post: facebookresearch.github.io/RAM/blogs/auto…
English