

Can agents learn from past successes — without fine-tuning?
In our latest blog at Tile Labs, we test a simple idea: giving agents examples of successful past runs before they act. No weight updates. No retraining. Just better context.
What we found:
• More selective agents → fewer errors
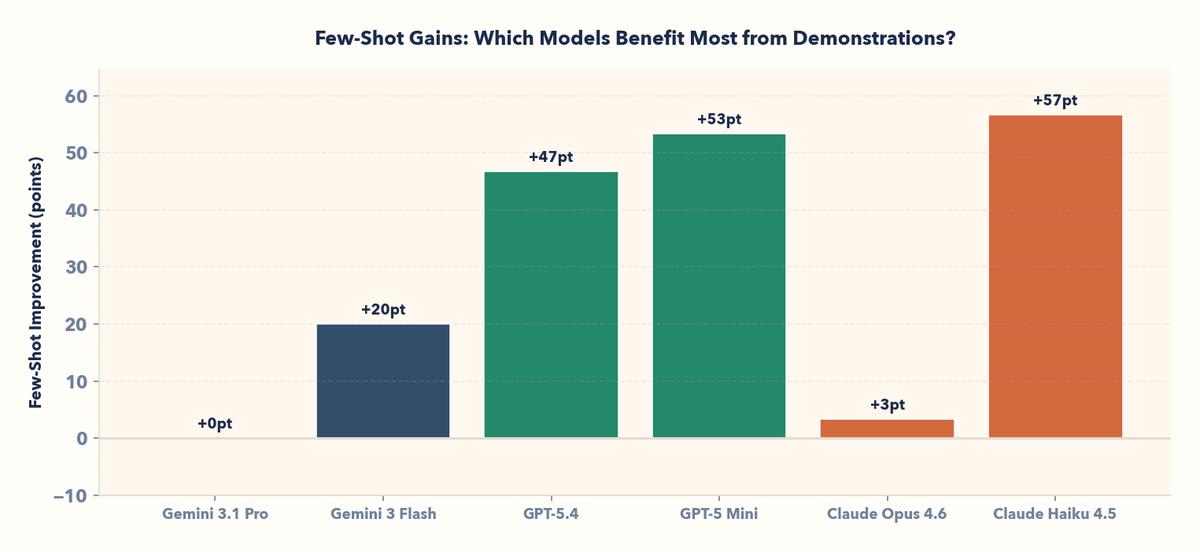
• Smaller models improve the most
• Frontier models gain better calibration
Read more: tilelabs.dev/blog/implement…
English
