Sabitlenmiş Tweet
Thomnick
34.5K posts

Thomnick retweetledi

Thomnick retweetledi

@tmnk0 @gangsinyeong7 ありがとうございます!私もフォロー返しします!
ただ、今Xの制限で中々フォロー返しができてません!お時間かかると思います!
日本語

Thomnick retweetledi

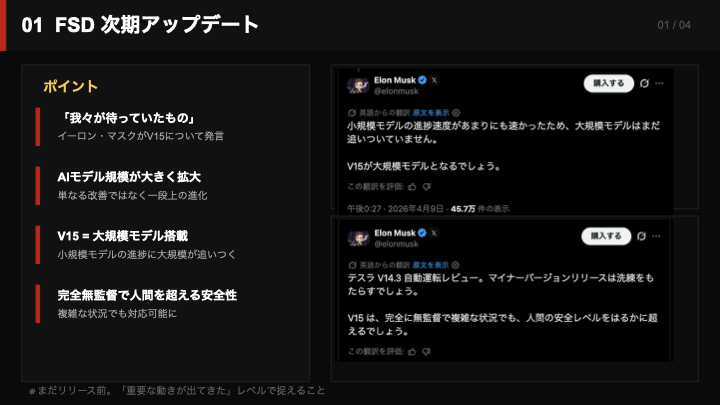
Cool to see that Tesla Full Self Driving has adopted the @LLVMFoundation MLIR stack, and is seeing 20% faster reaction time as a result. It is quite likely that a modern compiler and runtime implementation the break-through that robotaxi and FSD have been waiting for!
English
Thomnick retweetledi

Claude:実装完了しました。
僕:抜け漏れない?
Claude: 大丈夫です!
僕:じゃGPT5.4でレビューしますね。
Claude: あっ、そういえば(以下略
日本語
Thomnick retweetledi

🔴 NECESITO TU ATENCIÓN
Llevo una semana ayudando a Miriam en su caso de cáncer metastásico y quiero compartir la metodología que he estado usando porque es absolutamente replicable.
Pienso que, con suerte, puede ser ÚTIL A OTRAS PERSONAS con cáncer (o con cualquier otra enfermedad).
Los resultados que hemos conseguido no son un milagro, pero pensamos que son realmente útiles y pueden significar una diferencia crucial en un caso médico de vida o muerte.
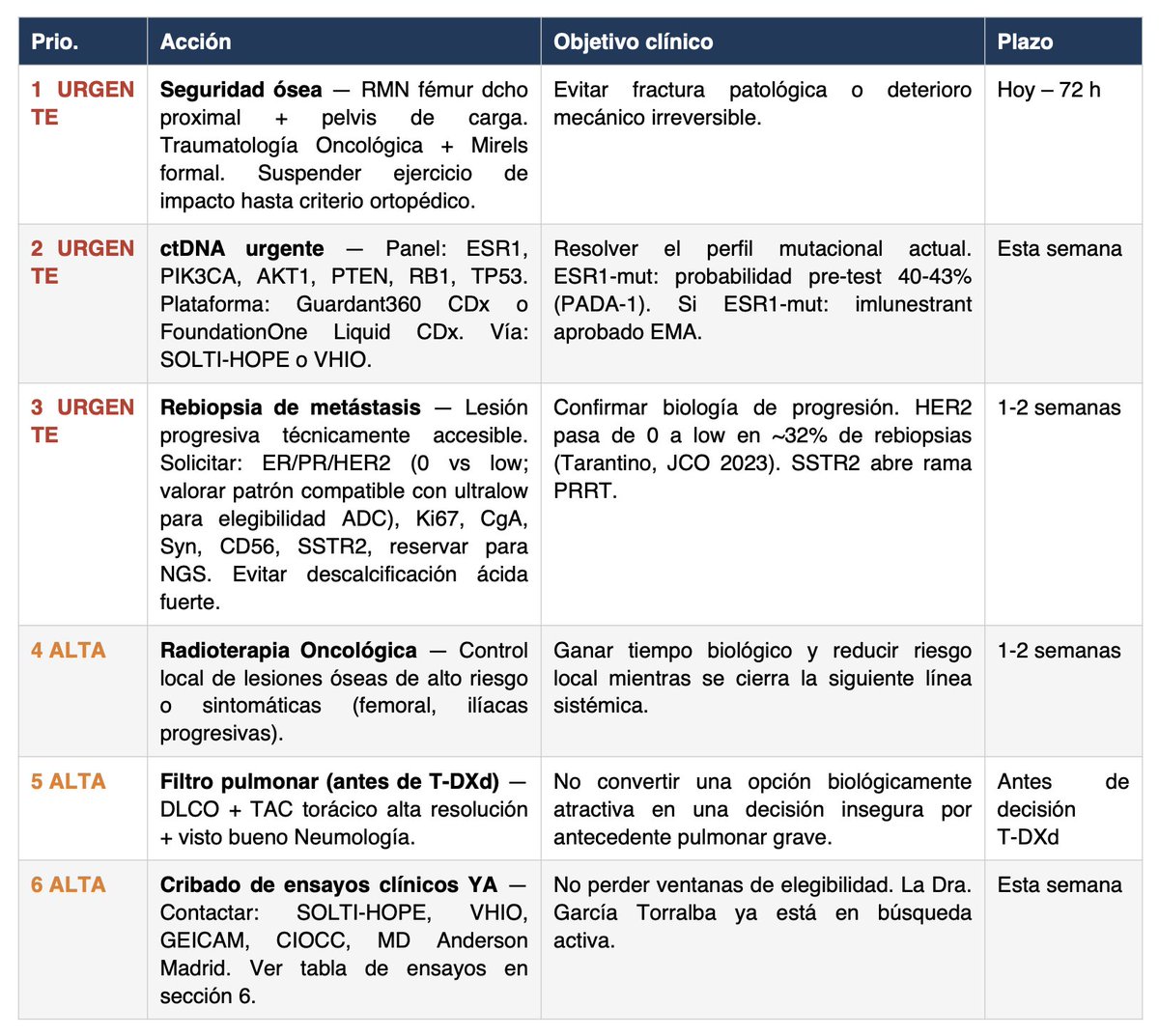
Aquí va paso a paso el método:
1/ Usar los modelos más avanzados del momento (por desgracia de pago, y no son baratos, opino que Sanidad Pública debería invertir en esto):
- ChatGPT Pro + Extended (40min de pensamiento aprox por llamada)
- Claude Opus 4.6 MAX
Pendientes de probar a fondo:
- Perplexity Sonar Pro
- Notebook LM
2/ Dárselo MUY MASCADO a la IA todo el historial. Esto parece una tontería pero es muy importante.
- Lo primero que pido, con Claude Cowork que tiene acceso al disco duro, es que entre en la carpeta en la que está TODO EL HISTORIAL (pueden ser más de 100 pdfs) y lo unifique todo en:
- Un único PDF (puede ser de más de 1000 páginas o lo que sea necesario)
- Un único txt legible, que debe hacer correctamente usando un script con OCR y luego comprobar con lupa que está bien hecho.
Insisto: no saltar al siguiente paso antes de tener muy bien hecho lo anterior, sobre todo el txt.
3/ Una vez tenemos lo anterior utilizar este prompt junto con el txt y el PDF como archivos de entrada y lanzarlo en AMBOS modelos (y en más si es posible) a la vez.
👉 Os lo dejo aquí, este prompt es increíble complejo/avanzado: dropbox.com/scl/fi/f5luli8… Está pensado para el caso concreto de Miriam, pero con los modelos del punto 1/ podrías adaptarlo a tu caso particular sin problemas.
4/ La PUNTA DE FLECHA enfrentando un modelo al otro: esta metodología no la he escuchado a nadie, pero funciona increíblemente bien. La sensación es la de ir afilando una estaca hasta que adquiere una punta reluciente.
Funciona así: con paciencia y en sucesivas iteraciones (aconsejo mínimo 5 veces, y en en cuenta que si ChatGPT tarda 40min te va a llevar un buen rato) enfrenta el resultado (el PDF) de un modelo a otro. Con un prompt sencillo del estilo:
"Otro comité de expertos opina esto. ¿Cómo lo ves? Si estás de acuerdo o lo contrario dime por qué, y genera un nuevo PDF si lo ves preciso".
El resultado se lo cruzas al modelo contrario. Así, en sucesivas iteraciones, búsquedas de internet, papers, etc. irán encontrando y afilando más cosas.
¿Cuándo acabar? Cuando AMBOS modelos digan que está perfecto y no puedan mejorar más el trabajo del contrario. Esto es tan absurdamente rompedor que pienso que los resultados de TODOS los modelos actuales mejorarían si siguieran esta metodología (apoyándose en una espiral rollo "adversarial model". No entiendo por qué nadie se ha dado cuenta de esto, si lo ha hecho, por qué no se le da más bombo. Funciona impresionantemente bien en cualquier ámbito, inclusive programación y matemáticas.
Es mas, mi teoría es que esto podría hacerse todavía mejor haciéndolo no solo con dos modelos: sino con una mayor combinatoria, añadiendo quizás Perplexity Sonar Pro, etc.
RESULTADOS
Increíbles. Obviamente no puedo saber si mejores que el mejor de los comités científico-sanitarios del mundo, pero le están dando a Miriam una nueva dimensión del caso, tests adicionales que hacer, posibles pruebas, etc.
Obviamente la IA milagros no hace, pero pienso que puede ya, a día de hoy, ayudar a muchos pacientes. Y Sanidad Pública debería invertir mucho, pero mucho, en esto.
Voy a preguntarle a Miriam si puedo poner el PDF completo de resultados más avanzado que conseguimos, para que os hagáis una idea de su calidad. Ya me ha dado más o menos permiso, pero quiero asegurarme 100%.

Español

Thomnick retweetledi

At this scale (10T+ params), pre-training doesn't just average—model capacity explodes, letting rare signals carve out distinct subspaces in the latent space without dilution. Novel ideas in data (e.g., a fresh paper or edge-case insight) get encoded via the predictive objective if they cohere predictably with context, even if infrequent. Emergence kicks in: the model starts recombining latent patterns into outputs that feel "new" because no single training example had them exactly. It's not invention from void—it's hyper-efficient compression revealing unseen connections in the data distribution. Post-pretrain fine-tuning or prompting amplifies it further.
English
Thomnick retweetledi

야근 후 귀가 완료.
낼 오전 6시 출근 하여 일단 프로젝트 사마이 하기로.
2달간 나름 한다고 했는데,
막상 완성도를 높이다 보니… 벼락치기 느낌이 되어 버렸다.
이게 잘 마무리 되면 후속 기획과 개발, 투자도 받을 수 있겠다는 나름의 로드맵…. 을 뒤로하고 바로 외부 발표용 자료도 만들어야 하군//
새벽일기 끝.
GIF
한국어


77만엔, 5만엔이었던 것ㅋㅋㅋ
그록아… 환율 적용은 안 해도
단위는 지켜야지 임마… @grok
ちゅみ@Luna01363424643
20代の平均貯金額はなんと77万円。 どうせ 『平均で語るな』と言われるので、 中央値を調べたら、何と5万円でした。
한국어