
Harry Zhang
732 posts

Ok I admit, Claude Code is amazing but compared to what we had 2-3 years ago pre AI.
Its good, but requires a lot of assistance, and knowing what and when to prompt.
If you are not a developer, there is no chance you can build a complex app.
English

I reimplemented "claude" CLI with codex and gpt-5.4-high. It cost $1100 in tokens, and is 73% faster and 80% lower resident memory during sustained interactive use.
It is very easy to reverse claude from npm distribution, then reimplement is 1:1. It is indistinguishable from the Anthropic version to the every header and analytics it send back
github.com/krzyzanowskim/…
English

Very few people know this, but in this scene from 'The Wolf of Wall Street,' Margot Robbie wasn't actually wearing underwear.
She confessed this herself, as she wanted to see Leonardo DiCaprio's genuine reaction.
While director Martin Scorsese offered her a robe to cover up, she felt her character, Naomi, would not have worn one in that moment, aiming for a "full-frontal" look to be "all in".
Despite her confidence on screen, Robbie admitted on the Talking Pictures podcast that she had "a couple shots of tequila" before filming because she was very nervous.
Robbie told Porter magazine that despite the intimate nature of the scene, it was filmed in a tiny bedroom packed with "30 crew".

English

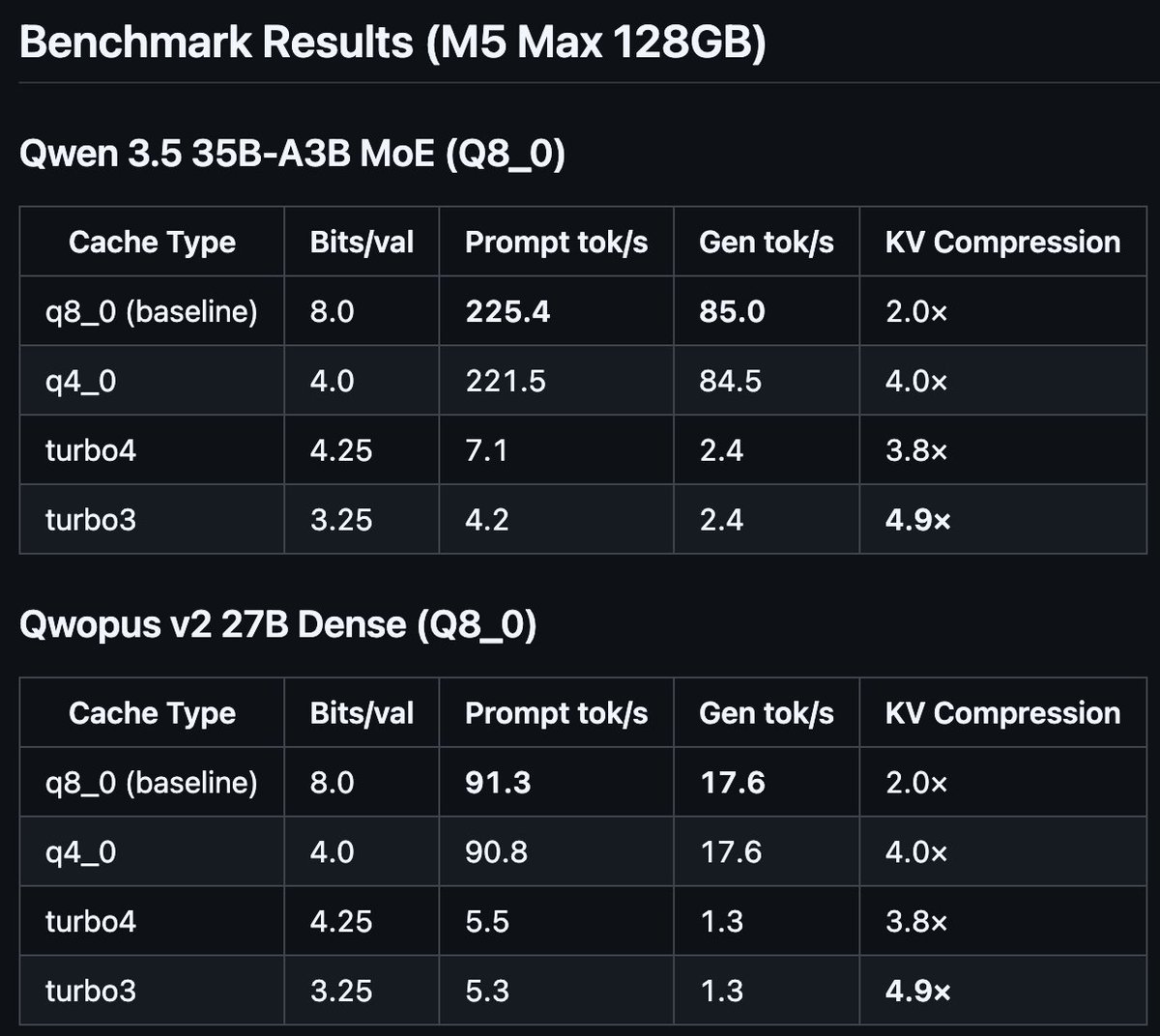
I implemented Google's TurboQuant paper (ICLR 2026) in llama.cpp with Metal kernels for Apple Silicon.
4.9× KV cache compression. Working end-to-end on M5 Max with Qwen 3.5 35B MoE and Qwopus v2 27B.
Speed needs work (unoptimized shader), compression target met.
Repo: github.com/TheTom/turboqu…
**Note**: as you'll see from the git when I saw "I" it's in conjunction with claudecode and codex. Just lots of steering and babysitting.
English
Nerds learn c and assembly in the old days thinking these are hard to replace skills. With Claude code what should we learn?
English

One common issue with personalization in all LLMs is how distracting memory seems to be for the models. A single question from 2 months ago about some topic can keep coming up as some kind of a deep interest of mine with undue mentions in perpetuity. Some kind of trying too hard.
English
Apple has a golden opportunity now to make mac a real ai ecosystem at the risk of losing the consumer label. The opportunity won't last long
English

pardon me Mr. Effect @kitlangton
I have a PR to fix a bug in some code you recently effectify'ed (you did not introduce the bug, it pre-dated your re-write).
Essentially if a large file is tracked by the Snapshot and gets deleted it causes large memory usage.
English
English

@tokeemb @exolabs as stated by @PixelRainbowNFT exo supports heterogeneous clusters but RDMA requires both machines to have TB5. M2 is TB4 only. you can still cluster over ethernet... you'd get pipeline parallelism instead of tensor parallelism. works, just slower.
English
PSA: If you have multiple macbooks that support RDMA, you can cluster them using @exolabs and run 30B+ models at 70 tok/s over thunderbolt5. tensor parallelism on consumer hardware is a solved problem. you are renting GPUs that are worse than the laptop on your couch. 2X M4 Max(64GB each) running mlx-community/Qwen3-30B-A3B-4bit @ 70 TPS
English

I'm not having great luck with NVIDIA Nemotron-Cascade-2-30B-A3B on coding side, am I the only one?
English

Calling it now: the TUI as the main interface of agentic software engineering is dead in 4-6 months
English
@saranormous Can we do away with websites? Text based internet is fine, isn’t it
English



Our official skills repo is open source: github.com/MiniMax-AI/ski…
Equip your agents with curated skills for iOS and Android development, Office file editing, and visual effects with GLSL shaders.
There are more open source projects coming!
English
@ryanvogel Can’t change the weather, but it would be nice to have Napa wines and cali coffee
English
