toriset
383 posts


toriset
@torisetxd
The real toriset @toriset on discord



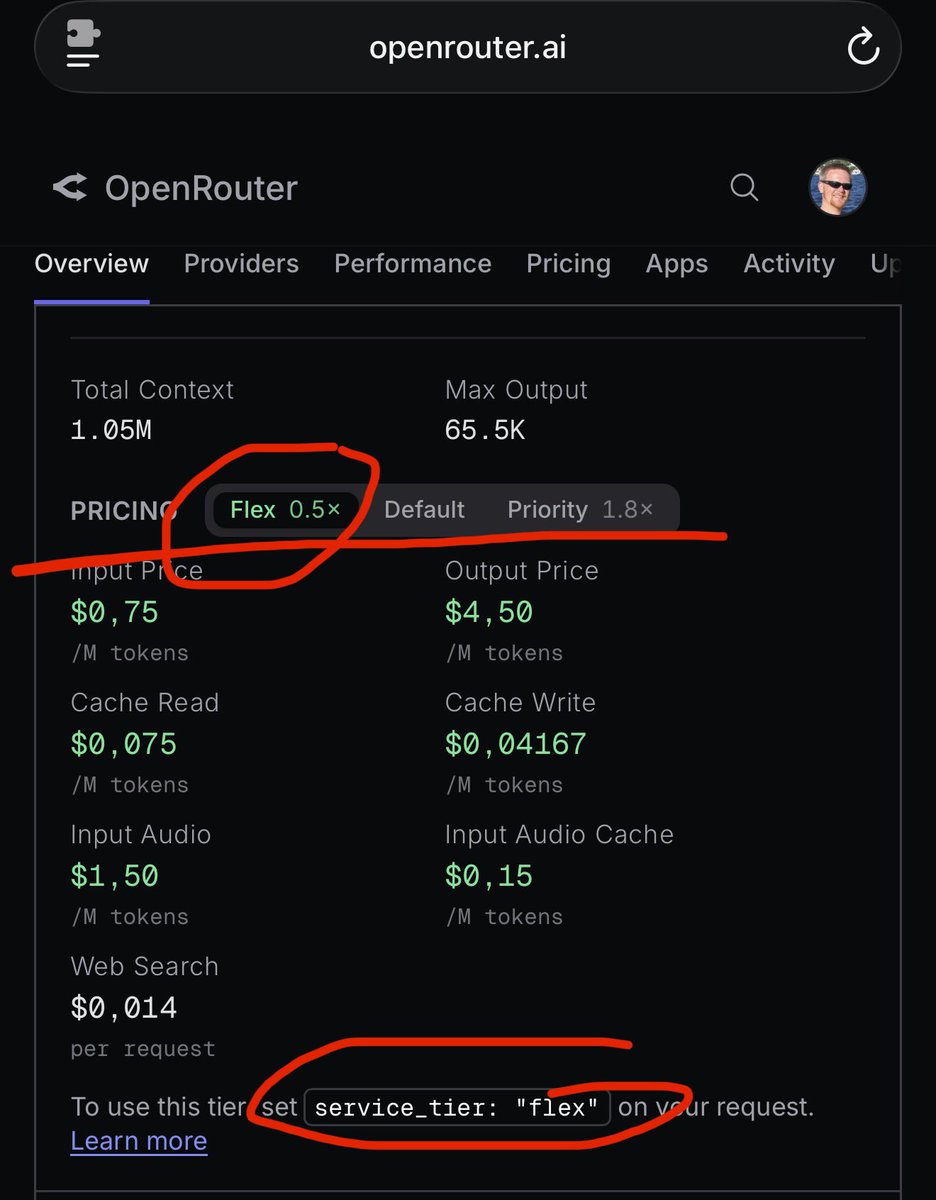

I was super excited reading this and was just about to ask Codex to replace, in ChapterPal, all calls to Gemini 3 Flash with Gemini 3.5 Flash, but then I checked the price and decided to stick to Gemini 3 Flash. The new Flash is priced almost like 3.1 Pro, so I'm expecting that the new 3.5 Pro will be priced even higher. If (or rather when) Google phases out 3 Flash, I'm not sure I'll know what to replace it with for visual reasoning about documents. Gemma 4 31B is almost as good as 3 Flash, but it's only available via OpenRouter where, so far, it's unreliable and slow. Any suggestions?






Introducing OpenAI Guaranteed Capacity: a new offering that enables customers to guarantee long-term access to OpenAI compute. We’ve made long-term investments in infrastructure, partnerships, and capacity planning to help customers scale reliably. Now, Guaranteed Capacity helps customers plan ahead for critical workloads in a compute-constrained world. openai.com/guaranteed-cap…

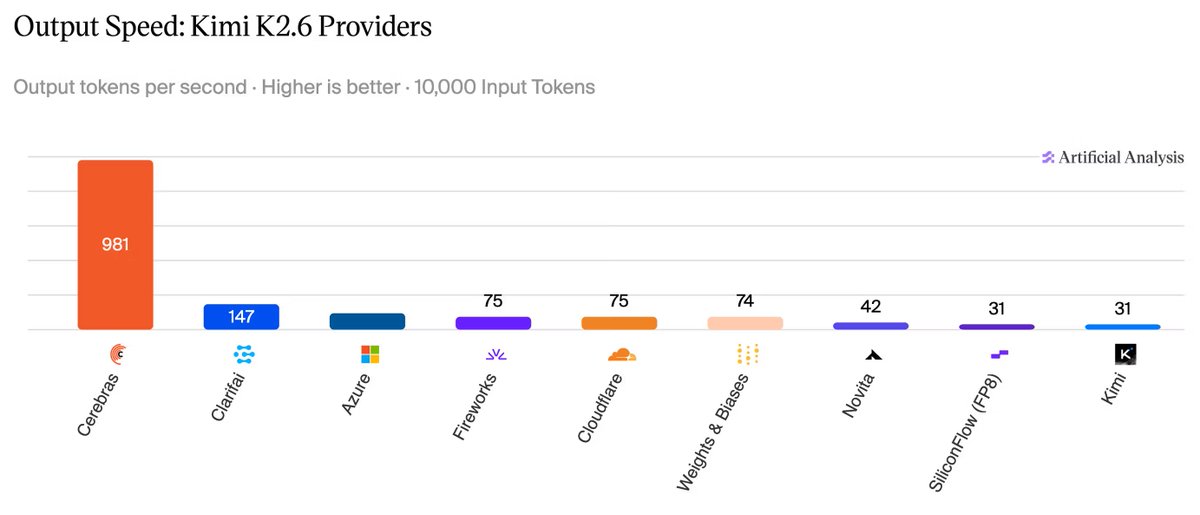
Cerebras is now running Kimi K2.6 – a trillion parameter model – in enterprise trials. At ~1,000 tokens/s, this is the fastest frontier model performance ever measured by Artificial Analysis @ArtificialAnlys.


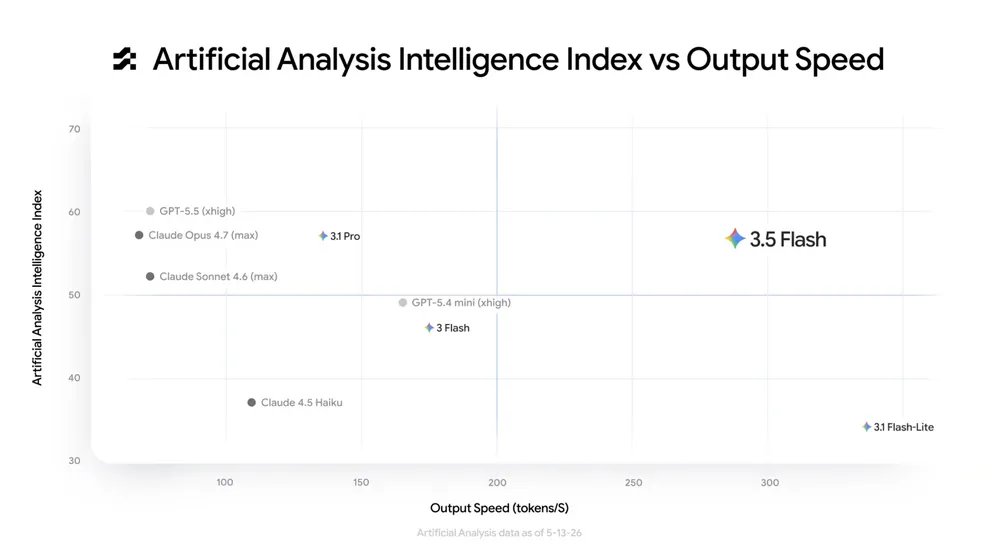



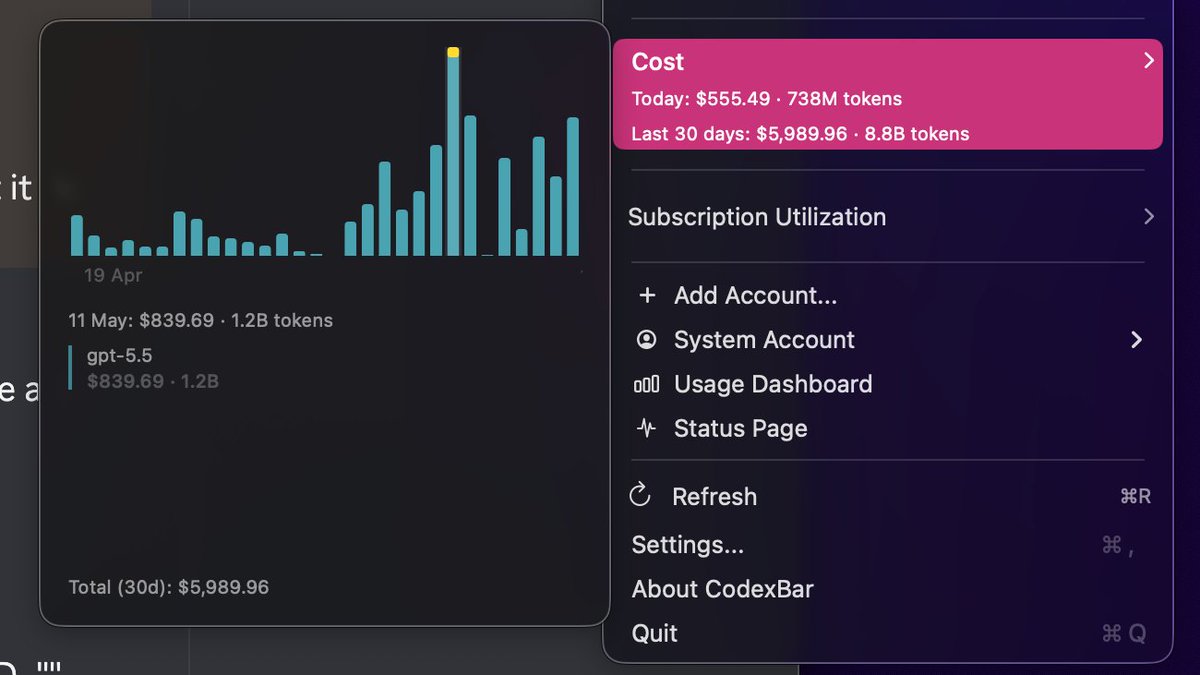


If this is Gemini 3.2 flash, it's strictly worse than gpt 5.5 at math. Fails MathArena Apex #11 and #12/ IMO p6




Why don’t LLM’s just tell you when you are asking a question / doing something that is out of distribution?
Kimi-K2.6 has finally been added to ECI! my favorite benchmark since it covers basically every domain in existence so K2.6 is just strictly a better model in every possible capability sense (pretty much) than Gemini 3 Flash and around Sonnet 4.6 level Ants CURRENT mid model
