Sabitlenmiş Tweet

1年前の自己紹介スライド、アップデートした
Kentaro Seki / 関健太郎@trgkpc
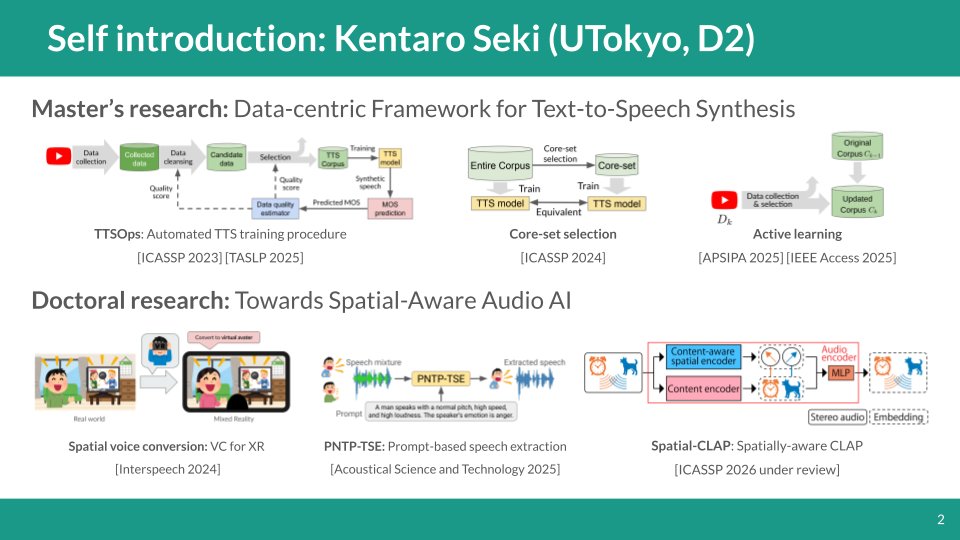
インターンの面接用に自己紹介スライド作ったから、ついでに公開しちゃお 音声・音響分野にいるD1です、よろしくお願いします
日本語
Kentaro Seki / 関健太郎
679 posts

@trgkpc
2nd-year doctoral student @ Univ. Tokyo Saru-lab (JSPS DC1) | audio-language model, speech enhancement, machine learning
インターンの面接用に自己紹介スライド作ったから、ついでに公開しちゃお 音声・音響分野にいるD1です、よろしくお願いします



卒論生早崎さんによるMoving-CLAPの発表がEA学生研究奨励賞を受賞されました🎉 おめでとうございます👏

こちらの論文が IEEE SPS Japan Student Conference Paper Award を受賞しました! 引き続き研究頑張ります! #HYOUSHOU" target="_blank" rel="nofollow noopener">ieee-jp.org/section/tokyo/…
SPEASIP2026ワークショップにて共著の学生さんが以下の賞をいただきました。おめでとうございます!👏&ご審査いただいた皆様ありがとうございました!😊 ・山内さん(D1):SLP企業賞(LINEヤフー賞) ・井浦さん(OB):SLP企業賞(SB Intuitions 賞) ・早崎さん(B4):EA学生研究奨励賞

Our paper Spatial-CLAP has been accepted to #ICASSP2026! Many thanks to my amazing co-authors. Also, our IEEE TASLP paper (TTSOps) has been accepted for Journal Presentation. See you in Barcelona! 🇪🇸



Our paper Spatial-CLAP has been accepted to #ICASSP2026! Many thanks to my amazing co-authors. Also, our IEEE TASLP paper (TTSOps) has been accepted for Journal Presentation. See you in Barcelona! 🇪🇸
New on arXiv: Spatial-CLAP 🎧📝 Can CLAP represent stereo audio even under multi-source conditions? Yes, Spatial-CLAP enables it. And, our spatial contrastive learning enforces robust and generalizable representations. 🔗 Full details in our preprint: arxiv.org/abs/2509.14785
Our new paper is available! arxiv.org/abs/2309.08127 We proposed a core-set slection method for TTS: how to extract a lightweight training subset (core-set) without degradation in TTS model? We conducted experiments with multiple languages (Ja, Zh, En) and core-set sizes!
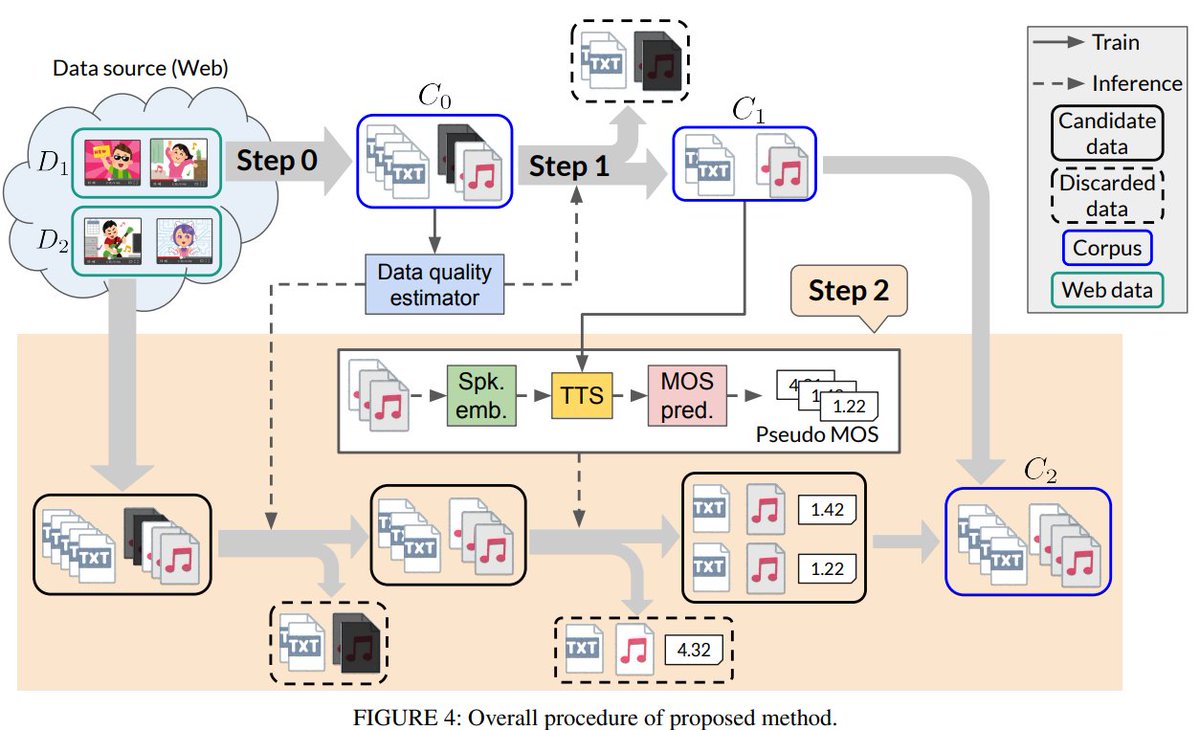
Our paper titled "Toward Data-Efficient Speech Synthesis: Active Learning–Based Corpus Construction for Multi-Speaker Text-to-Speech Synthesis" has been ACCEPTED for publication in IEEE Access! Many thanks to great co-authors!



