Fengyu Cai retweetledi

Claude Code for Academics
"A gentle introduction in how to use Claude Code for Academics."
presentation slides and github repo from Alessandro Spina
link in reply

English
Fengyu Cai
11 posts


@trumancfy
Ph.D. student @ SOS&UKP TU Darmstadt





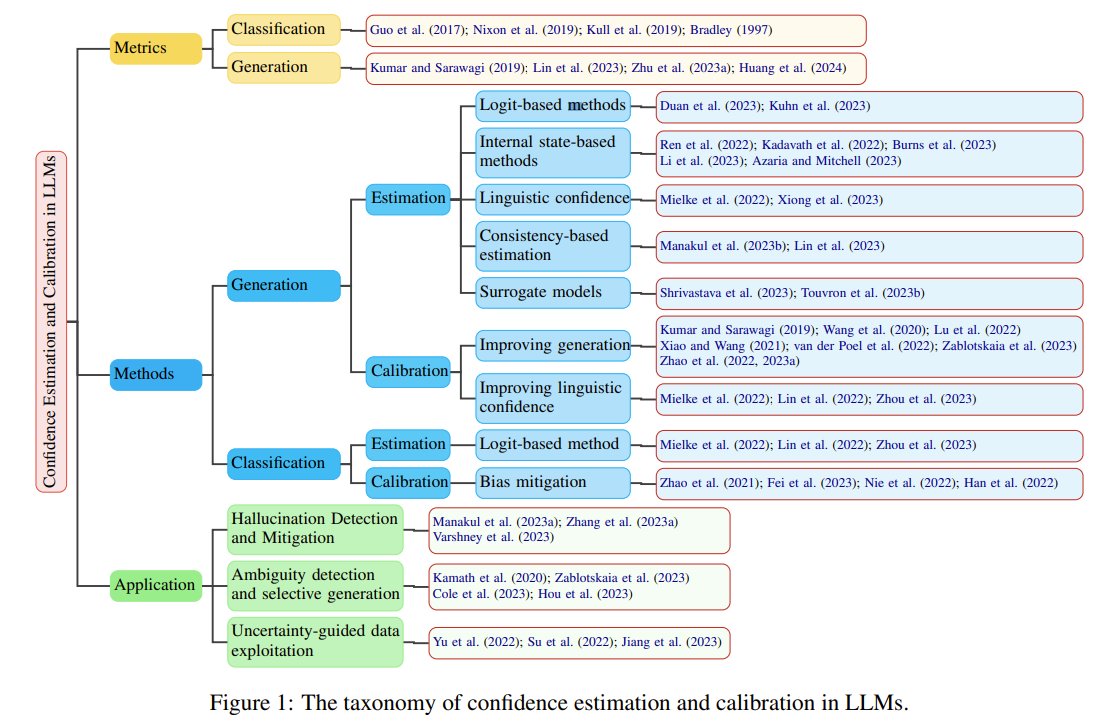

How to enjoy the best of both worlds of efficient training (less communication and computation) and inference (constant KV-cache)? We introduce a new efficient architecture for long-context modeling – Megalodon that supports unlimited context length. In a controlled head-to-head comparison with Llama2, Megalodon achieves better efficiency and accuracy than Transformer in the scale of 7B and 2T training tokens.