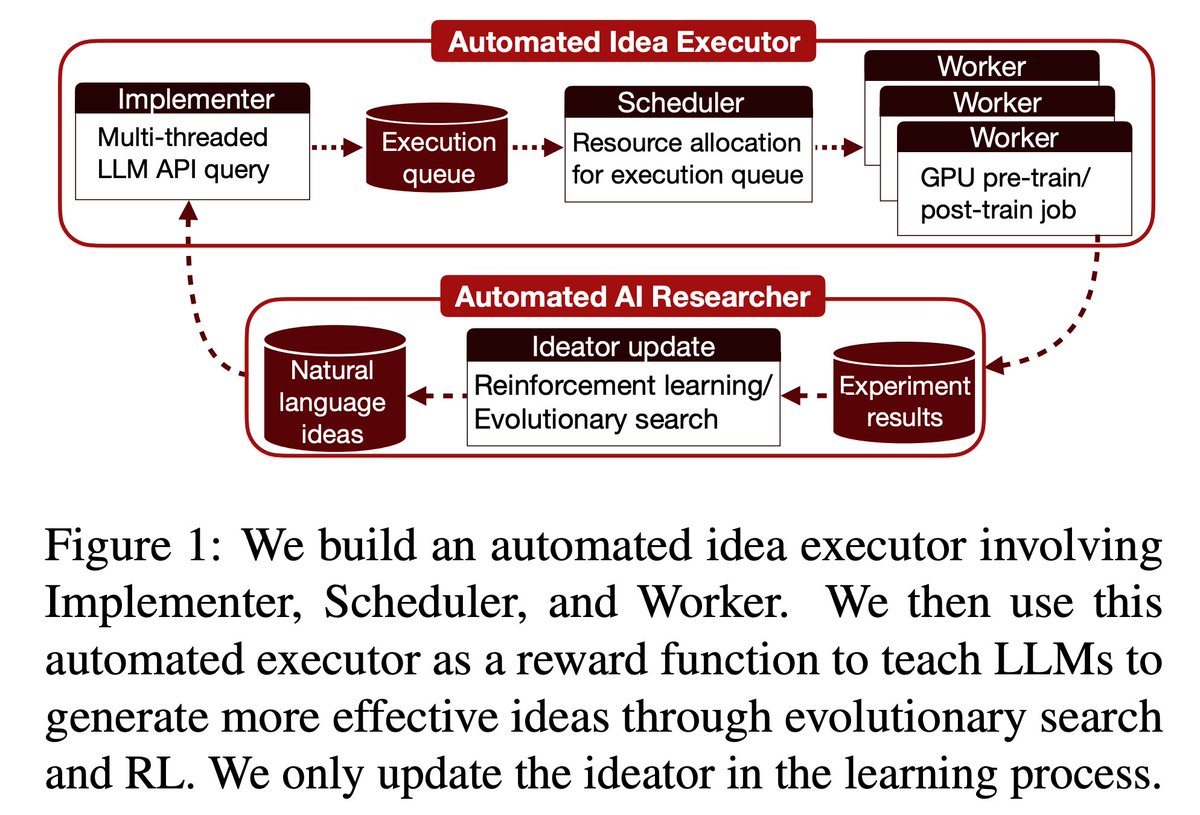
Liwei Jiang@liweijianglw
⚠️Different models. Same thoughts.⚠️
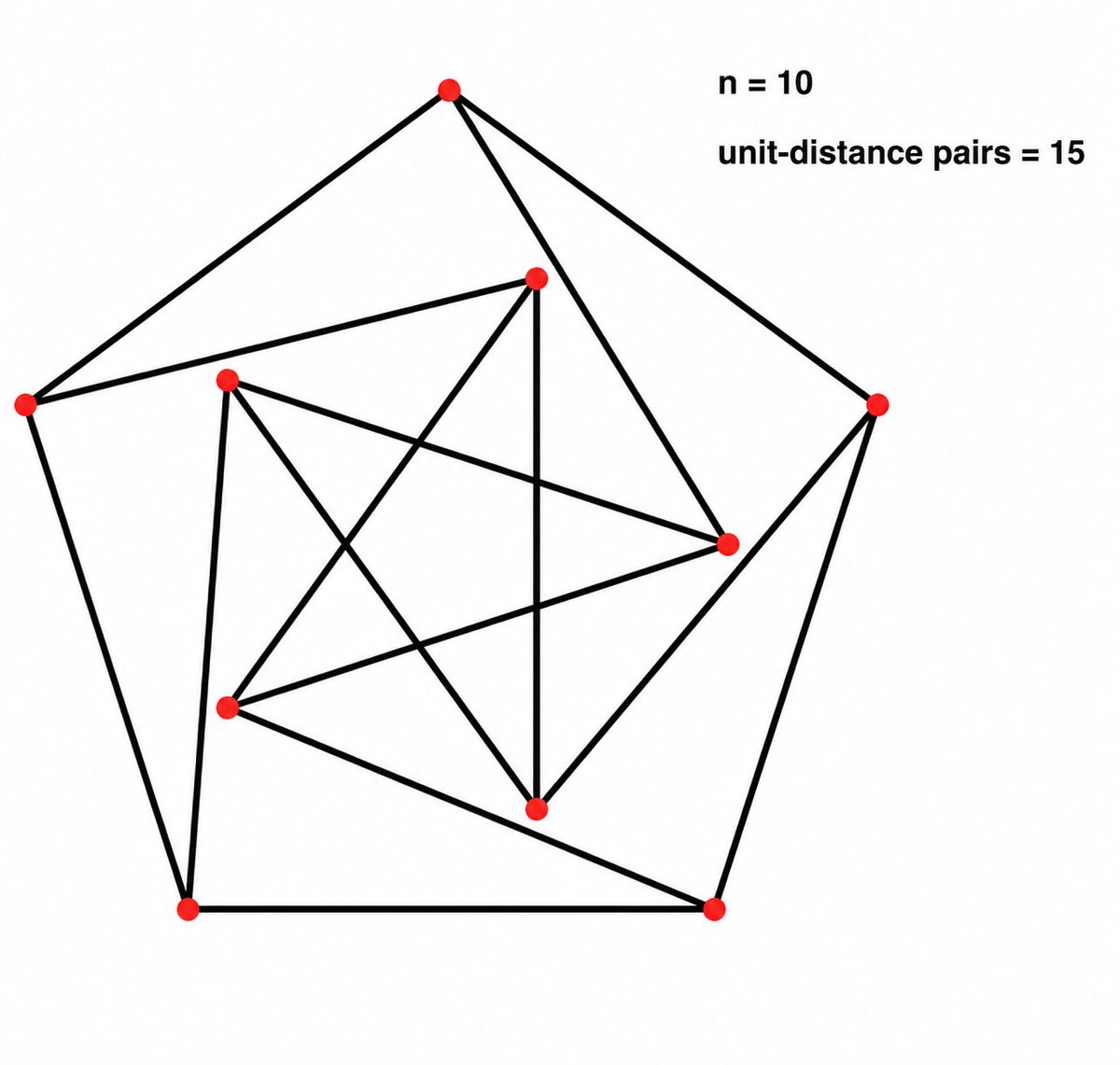
Today’s AI models converge into an 𝐀𝐫𝐭𝐢𝐟𝐢𝐜𝐢𝐚𝐥 𝐇𝐢𝐯𝐞𝐦𝐢𝐧𝐝 🐝, a striking case of mode collapse that persists even across heterogeneous ensembles.
Our #neurips2025 𝐃&𝐁 𝐎𝐫𝐚𝐥 𝐩𝐚𝐩𝐞𝐫 (✨𝐭𝐨𝐩 𝟎.𝟑𝟓%✨) dives deep into this phenomenon, introducing 𝐈𝐧𝐟𝐢𝐧𝐢𝐭𝐲-𝐂𝐡𝐚𝐭, a real-world dataset of 26K real-world open-ended user queries spanning 17 open-ended categories + 31K dense human annotations (𝟐𝟓 𝐢𝐧𝐝𝐞𝐩𝐞𝐧𝐝𝐞𝐧𝐭 𝐚𝐧𝐧𝐨𝐭𝐚𝐭𝐨𝐫𝐬 𝐩𝐞𝐫 𝐞𝐱𝐚𝐦𝐩𝐥𝐞) to push AI’s creative and discovery potential forward.
Now you can build your favorite models to be truly original, diverse, and impactful in the open-ended real world.
📍Paper: arxiv.org/abs/2510.22954
📍Data: huggingface.co/collections/li…
We also systematically reveal Artificial Hivemind across:
💥 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐚𝐛𝐢𝐥𝐢𝐭𝐢𝐞𝐬: not only do individual LLMs repeat themselves, but different models produce strikingly similar content, even when asked fully open-ended questions.
💥 𝐃𝐢𝐬𝐜𝐫𝐢𝐦𝐢𝐧𝐚𝐭𝐢𝐯𝐞 𝐚𝐛𝐢𝐥𝐢𝐭𝐢𝐞𝐬: LLMs, LM judges, and reward models are systematically miscalibrated when rating alternative responses to open-ended queries.
(1/N)