
兔子
613 posts

兔子
@tuzi968
2013年第一次在比特币中国单价500人民币买比特币,四轮周期选手 ;黑天鹅时敢于重仓,2018,2020,2022三次成功梭哈
Katılım Mart 2021
80 Takip Edilen70 Takipçiler

考虑好一共想加多少资金或者仓位,结合你现在已有的仓位。
以我举例,我现在美光仓位8%,我最多可以加到12%。那么现在跌破700,我就会小幅度加一点,然后650,600,550,500分批加仓,一次比一次幅度要大。最多加到整体仓位的12%。如果没跌到呢?没跌到就算了,8%的敞口也不小了,这次不给机会,以后还会有机会。或者在美光上没给太多机会,在别的标的上还有。所以我从来不建议all in一只股票,但也没必要太分散,要是有五支自己信仰度很强,很了解的好股票,基本就够了。
Ceasoul@BCeasoul16174
@darrencao2024 MU跌破600加仓,如果跌破500我加MUU。但是我现在犹豫的是,如果这次回调不跌破600,我该怎么操作
中文
板块轮转 会回来的 现在的资金都在AI基础设施上。微软就算估值降低,也配得上至少25以上的倍数。现在提前埋伏微软是长线布局的好时机
Mark Y@YangYcat
@darrencao2024 不能按eps增长是有原因的,第一微软巨量的以人类历史上最高硬件价格购买的capex累计折旧对eps的影响还没显现(现在的会计利润纸面虚高),第二各种ai cli和vsc fork这些削弱了微软构建的github和vs/vsc ai入口优势,第三ai长期看削弱了微软saas业务的前景。现在saas公司eps年年爆增,股价如瀑布般暴跌
中文

内存/存储板块之后,AI 下一波该轮到谁了呢?
我斗胆猜测一下,光互连和能源,可能会是下一个财富密码赛道。
光互连解决的是 AI 集群内部和集群之间交换数据的瓶颈,随着 AI 数据中心的不断膨胀,对于数据传输速度的要求越来越高,铜缆慢慢被光纤代替,传递光信号。
这就催生出了光模块产业链,包括激光器、调制器、探测器、DSP 芯片、光纤组件设计以及相应的原材料供应和代工制造。
而光通信的下一代技术是 CPO,把光学元件从服务器背面搬到芯片封装内部,紧贴着 GPU 或者交换芯片,进一步缩短电光转换的距离。而那些设计制造光学组件的公司会直接受益。
我自己研究看好的标的是 $COHR $LITE $AAOI $SIVE
而电力能源解决的是更底层的物理瓶颈。数据中心用电量飞速暴涨,然而发电厂以及配套设备的建设周期,却是以年为单位计算,这是结构性的供需错配。
发电、输配电、数据内部配电、冷却、储能,各个环节的产能都是瓶颈,围绕瓶颈找相应的投资标的。
目前我还在学习,暂时看到了几个弹性很高的标的 $FLNC $BE $OKLO
总之我觉得投资布局思路得转换一下了,拿捏住上下游产业链瓶颈的这些重资产公司,会吃到这轮最大的红利。
中文

内存御三家的扩产进度条:
🌟三星
1️⃣龙仁国家产业园(最大項目): 投资约2,600 亿美元,建设六座晶圆厂,2026 年下半年開工,2031 年完工。
专注 HBM4 等先進 DRAM ,采用1b 纳米及未來 1c 纳米制程。
2️⃣平泽 P5 工厂: 此前因周期下行暂停建设,现已全面重启,目标 2028 年全面运营。
🔢2026 年产能计划: 第二季度、第四季度分别扩产 DRAM 产能至 14 万片/月、20 万片/月。2026 年 DRAM 晶圆产量预计达 793 万片,较 2025 年的 759 万片增长约 5%。
🌟SK 海力士
1️⃣M15X 工厂(提前量产): 为应对 NVIDIA 对 HBM4 的迫切需求,将量产时间从原计划 2026 年 6 月提前至 2026 年 2 月。初始产能规划每月 1 万片晶圆,计划在 2026 年底前扩展至多倍规模。
🤝策略特色: 与台积电深度结盟,将 HBM4 基础裸片采用台积电 12nmFFC 及 N5/N3 工艺,并使用 CoWoS 封装技术。产能扩张几乎完全服务于 HBM 等高附加值产品。
🌟美光$MU
资本支出大增,主要用于扩充 HBM 封装产能和加速 1-gamma工艺节点。
1️⃣博伊西 ID2 晶圆厂(最高优先级): 将原计划投入纽约的部分资源重新调配至此,打造全球唯一的"研发+量产"一体化超级中心,预计 2026 年内启动设备安装,2027 年实现有意义的 DRAM 产出。
2️⃣爱达荷州: 爱达荷州第一座晶圆厂预计 2027 年年中开始生产(早于预期);第二座厂 2026 年动工,2028 年投产。
3️⃣纽约厂 2026 年初破土动工,2030 年后供应。
4️⃣扩建新加坡晶圆厂,增加 NAND 制造用洁净室空间。
中文
很多人投资都想学巴菲特,看到他不碰AI,就觉得AI有泡沫;看到他手握巨额现金,就跟着捂着钱不动。但你有没有想过一个问题:你和巴菲特现在所处的位置,根本就不一样。
巴菲特今年94岁,净资产超过1500亿美元,伯克希尔光现金储备就接近3500亿。他现在的首要任务不是把财富翻倍,而是保住它、传承它。在这个量级上,他的每一个决策都有他特定的约束条件,和你我的处境相去甚远。
巴菲特并非拒绝科技股,他买过苹果,也买过谷歌,但他看中的是这两家公司背后清晰可理解的商业逻辑——苹果的消费者粘性和生态护城河,谷歌的广告垄断地位。他的选股原则之一,是只投资自己能真正看懂的业务。AI的底层技术、竞争格局、未来盈利模式,并不在他深耕的认知范围之内。所以他对AI的回避,是能力圈边界的自我约束,而不是对这个方向价值的否定。这是他的局限,不是你的判断依据。
如果你真的想学巴菲特,我建议去读他早期的投资史。1950年代他管理合伙基金的时候,年化回报接近30%,靠的根本不是守着现金等机会。他重仓盖可保险,重仓美国运通,重仓华盛顿邮报,这些在当时都是成长型资产,都是别人还没完全看懂的机会。那时候的巴菲特,攻击性远比今天强得多。
真正值得我们学习的,是他研究公司的方式。在做投资决策之前,他会花大量时间研究公司的基本面、业务模式、历年财报,甚至深入研究管理层的能力、性格和行为习惯。他宁愿花几个月把一家公司彻底看透,也不愿意在一知半解的情况下仓促建仓。这种对"真正理解"的执着,是他几十年穿越牛熊的底层原因之一。
对我们普通投资者来说,这一点的借鉴意义远比他现在持有什么仓位更大。在买入一只股票之前,你能不能清楚地说出这家公司靠什么赚钱、护城河在哪里、管理层的执行力情况——如果答案是模糊的,那仓位就不应该太重。
学巴菲特的护城河思维、学他对商业模式的深度理解、学他不被短期市场情绪左右的定力——这些是跨越时代的东西。但照搬一个94岁老人在1500亿量级下的资产配置决策,用来指导自己三四十岁时的财富积累,这不叫学习,这叫刻舟求剑。

中文

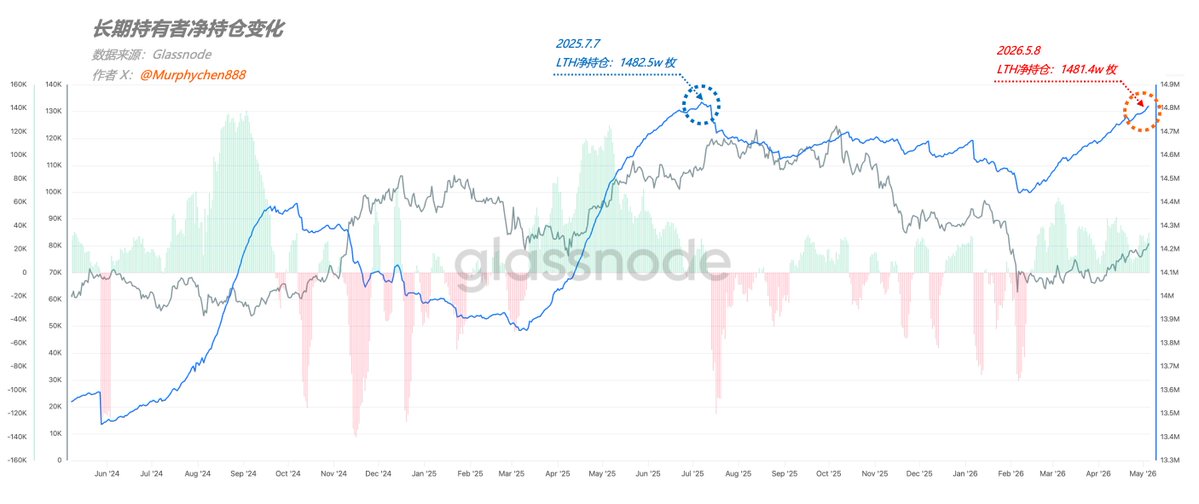
截止5月8日,长期持有者(LTH)净持仓量已高达1481.4w 枚BTC,距离突破前高仅差1w枚。目前正以每7日约30,000枚的速度正增长。
这意味着在BTC全部流通量中,有75%的筹码被长期投资者所掌控,且以目前的趋势,用不了几天就能再创历史记录。
通常,在熊市的后半段,只要LTH没有出现大面积派发,行情就能慢慢企稳并最终转变趋势。
所以,如果你仍坚定的认为BTC还会跌得更深,那么不妨想一想未来半年还有什么事情,能逼迫LTH再一次恐慌出逃。能有如此杀伤力的,一定不是小事件。
Murphy@Murphychen888
从供需角度,解读60K能否成为本轮熊底? 对LTH和STH供应量曲线变化的研究,本质上就是观察市场的供需关系。尤其对熊市进程的延续和转变,从数据层面给了我们极高的参考价值。我们来看2个真实案例: 🚩 案例一、 本轮熊市,LTH净持仓量从2/10开始回升,至4月30日已增加了32.4w枚BTC;同时期,STH持仓量减少了18.4w枚(持币转为新的LTH);其中的差值,即 32.4-18.4 = 14w 枚就是“老LTH”增持进来的筹码(图1)。 所以,LTH净持仓量的增加,有很大部分的贡献来自STH的持有不动;当然,“老LTH”的增持也是不可忽视的力量。 🚩 案例二、 在上轮周期,LTH净持仓量从2022.7.23开始触底回升,此后在FTX暴雷时又突然下降,从11/06至11/24,LTH减少了7.2w枚;但同期STH却增加了36w枚(图1)。 LTH减少的,当然是派发给了STH;但还有28.8w的差额是哪里来的呢?这是从矿工、交易所等地址发生的转移(FTX暴雷让人们对托管平台的极度不信任),从而补充到了STH的筹码中。 ----------------------------------- 所以,通常LTH净持仓量趋势的反转(从下降到上升),总会早于BTC的熊市见底。当供应端的压力逐渐减弱,即便需求没有立即恢复,也能慢慢的构筑底部区间。 👉 2019.7.29 —— LTH净持仓触底回升,如果没有3.12事件,那么此后 $7,000-$9,000 就是底部区间(图2)。 👉 2022.7.23 —— LTH净持仓触底回升,如果没有FTX暴雷,那么此后 $19,000-$22,000 就是底部区间。 同理,2026.2.10 —— LTH净持仓触底回升,如果不考虑后期还有没有黑天鹅,那么此后 $62,000-$65,000 就有可能是本轮熊市的底部区间,或无限接近底部。 对于大多数小伙伴来说,可以不用弄清楚底层逻辑是什么,只需知道: LTH净持仓的增加,就代表了更多的STH(新玩家)持有筹码不卖,同时还有 LTH(信仰者)在持续增持。 其带来的必然结果就是底部的抬高和进程的加快,因此,供需关系的转换也是我们在熊市中最值得关注的核心数据。
中文
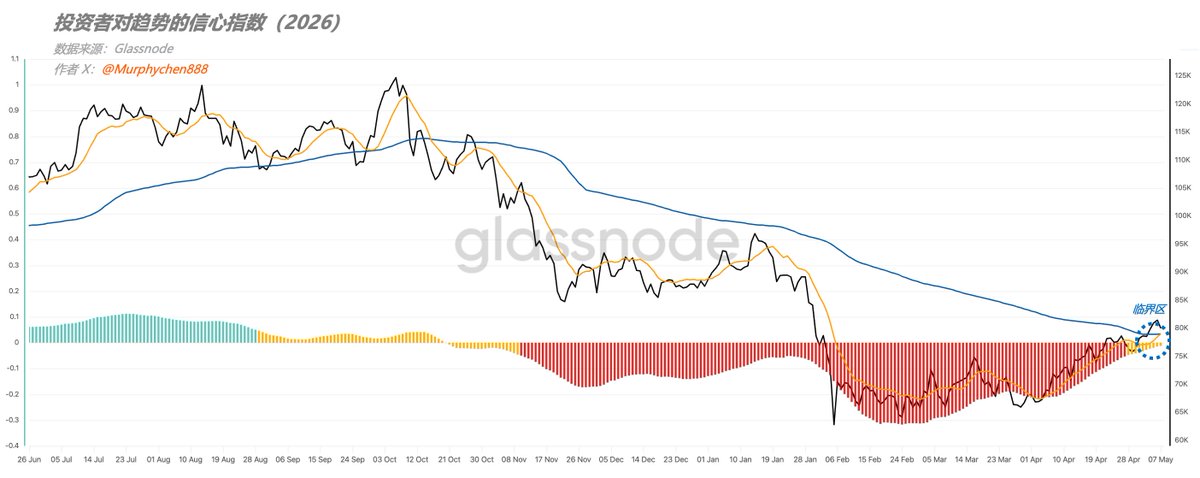
我说亲爱的黑天鹅、灰犀牛,你们要来的话就赶紧来啊。不然,我可真要上去咯......
—— 投资者信心指数,距重回“上水”仅一步之遥!

Murphy@Murphychen888
第一颗种子破土而出,春天还远吗? 自从2025.11.10 投资者信心指数掉入红色的“悲观区”,经历了170天,终于在昨天出现了第1根“黄色”信号! 黄色代表“犹豫区”,是从“恐慌和悲观”过度到“信心和乐观”的中间过度阶段。 对比上轮周期,第1次出现黄色信号是在信心指数掉入红色区后的106天,而第2次出现是322天。 很显然,我们现在所处的位置更像是上轮的“第2次”,而不是“第1次”,熊市的跨度在变短,进度在变快。 但是,犹豫区也分“水上”和“水下”,“水上”即零轴之上,通常就是趋势看多的起点。而“水下”则是市场选择方向的临界点。 比如上轮周期,即2022年4月和11月进入水下的犹豫区后,两次都选择了继续回调。当然,这次未必也一样。 所以不要问我“看多还是看空”?在整个市场都在犹豫的时候,上下是五五开的概率。 如果你认为历史经验可以借鉴,那就做空。如果你想等更确定性的信号,那就等进入“水上”再做多。 去年的今天是雨天,不意味着今年的今天也下雨,但至少我们可以判断大概率不会下雪了,因为春天快来了!
中文

他说的很好,我想重点说一下 “Why now”的问题。为什么是现在,为什么之前没有这个需求。
$AEHR 做的事情叫晶圆级老炼(Wafer-Level Burn-In, WLBI)和封装级老炼(Package-Level Burn-In, PLBI)。
老炼是什么?简单说:在芯片出厂前,给它施加高温+高电压+工作负载,持续数小时到数十小时,让那些有隐性缺陷的芯片在工厂里提前死掉(“早夭筛选”),而不是到了客户手里才死。
为什么这个概念,现在开始炒而不是一年前开始炒?两个方向,分别是自研高功耗ASIC芯片和硅光。
1. 自研ASIC芯片这一点是最近开始多起来的,每种定制ASIC都是全新设计的芯片,在量产初期良率不稳定,这时候老炼的价值最大。而NVIDIA的GPU已经是成熟产品,老炼流程是标准化的。新ASIC的老炼流程需要从头定制, $AEHR 正是做这件事的公司。
那么大家可能要问了,那之前 $goog 家tpu的老炼是谁做的?这一点,查不到。Claude老师认为,因为之前TPU的功耗只有200-300W,一些粗糙的方法就足够了,功率没有那么夸张的时候,老炼不是一个必不可少的流程,这是一个因为AI ASIC功耗爆炸而新出现的需求空白。
那么又有朋友问了,这公司之前主要是做sic车机芯片的老炼,难道车机芯片功耗比TPU还高?不是的,车机芯片是因为SiC的晶体工艺本身麻烦,并且车机对于安全的需求是苛刻的。
2. 硅光,
第一步:硅光芯片以前需要老炼吗?
硅光芯片不是新东西,2015年前后就开始商业出货了。但那时候硅光芯片被封装在pluggable光模块里。一个OSFP光模块坏了怎么办?拔掉,换一个新的,30秒搞定。光模块的单价几百到几千美元。
在这个架构下,硅光芯片的老炼需求很弱。为什么?因为现场故障的代价很低,换一个光模块的成本远低于对每颗硅光芯片做全检老炼的成本。经济学上不划算。大多数光模块厂商做的是常温功能测试+高温老化抽样,不是每颗芯片的晶圆级全检老炼。
第二步:什么变了?
两件事同时在变:
变化一:产量从百万级走向千万级甚至更多。
之前数据中心的光模块用量是百万级/年。现在AI集群的规模在爆炸,一个10万GPU的训练集群可能需要几十万个光模块。全球hyperscaler同时在建多个这样的集群。硅光芯片的年产量正在从百万级跳到千万级。
产量一旦到了这个规模,即使只有千分之一的早期故障率,每年也意味着几万颗芯片在客户现场死掉。每一颗死掉的芯片都意味着一个光通道中断→可能影响GPU之间的通信→可能导致训练任务中断或性能降级。在一个几千万美元的训练任务中,光模块故障导致的停机成本远远超过光模块本身的价格。
所以第一个驱动力是:产量跨过临界点后,“可接受的故障率”的经济学计算完全改变了。
变化二:CPO/NPO让硅光芯片变得不可更换。
这才是最关键的变化,直接连接到我们之前讨论的CPO架构。
在pluggable时代,光模块是可热插拔的。硅光芯片坏了=换一个光模块=$几千美元。
在CPO时代,硅光引擎被直接封装在交换芯片或GPU的package里面。硅光芯片坏了=整个package报废,包括那颗价值几千到上万美元的交换芯片/GPU,包括昂贵的HBM堆叠,包括复杂的先进封装结构。一颗几百美元的硅光芯片的故障,代价瞬间从”换一个光模块”变成了”扔掉一整个价值几万美元的封装”。
这就是“不可更换性驱动”的本质:当一个零件从”可插拔”变成”焊死在里面”的那一刻,它的可靠性要求跳升了一个数量级。
这跟SiC的逻辑有相似之处,SiC的老炼需求也不是因为SiC本身有多贵,而是因为SiC失效后的连带后果不可接受(人命)。硅光在CPO中的老炼需求也不是因为硅光芯片有多贵,而是因为失效后的连带成本不可接受(整个封装报废)。
第三步:为什么需要晶圆级老炼?
硅光芯片有一些特殊的失效模式是常温功能测试发现不了的:
波导缺陷:硅波导中的微小缺陷(刻蚀粗糙度、材料杂质)在常温下可能不影响光传输,但在高温长时间工作后会导致插入损耗逐渐增大,最终超过系统容限。
调制器退化:硅MZM中的掺杂区域在高温高压下可能发生离子迁移,改变调制器的Vπ(半波电压),导致消光比下降。
锗探测器暗电流漂移:Ge PD的暗电流对温度和时间敏感——有些探测器在几百小时的工作后暗电流会显著增大,恶化信噪比。
光栅耦合器/边缘耦合器对准漂移:封装后的热循环可能导致耦合效率逐渐下降。
这些问题的共性是:常温短时间测试看不出来,但在实际工作条件下几百到几千小时后会暴露。 老炼的作用就是用加速应力在几十小时内把这些”慢性病”提前诱发出来。
而且因为硅光芯片是在晶圆上制造的(SOI晶圆,Soitec供应,TSEM代工),在晶圆阶段做老炼(WLBI)比切割封装后再测效率高得多——一片300mm晶圆上可能有几百颗硅光die,AEHR的FOX-XP可以一次性对整片晶圆做全检。
AEHR为其主要硅光客户升级了FOX-XP至新的高功率配置,在九片晶圆配置中每片晶圆可达3.5kW功率,并配备了全自动化的WaferPak Aligner,可以一次性对300mm晶圆上所有器件进行测试和老炼。
Paradis Labs@ParadisLabs
The most asymmetric AI supply chain setup atm is $AEHR. A $1B company with a literal monopoly. Seen it gain some traction on X these past few weeks/months, but not really seen a proper deep-dive. They make burn-in test systems — equipment that stress-tests chips at full operating power before they ship. Every GPU, every custom ASIC, every AI accelerator inside a hyperscaler data center has to be tested. You cannot ship a $10K chip that fails after 200 hrs. $AEHR tests entire 300mm wafers simultaneously — at up to 3,500 watts per wafer, thousands of amps of current. No other company on earth does this. $TER and Advantest are the giants of chip testing. They test chips individually or in small batches. $AEHR tests entire wafers before packaging. It's a completely different point in the manufacturing process — and it means defects caught before expensive packaging. They also just became the first company to ship wafer-level burn-in systems for AI processors. That's an actual $14M order delivered in Feb'26. The two platforms driving the AI thesis FOX-XP (Wafer-Level Burn-In) → Up to 9 × 300mm wafers in parallel → 3,500W per wafer — unmatched → $14M order received Feb 26 for AI processors → Silicon photonics follow-on order early March → Used for: AI processors, SiC power, optical chips Sonoma (Package-Level Burn-In) → Acquired via Incal Technology → Up to 2,000W per device — for packaged AI ASICs → First hyperscaler production win: Feb 11, 2026 → 10 companies visited HQ to evaluate → "Very large expansion" of orders guided for H2 2026 Three orders in 30 days. Two platforms. Both now confirmed in AI production. But the consumables angle is what most people miss Every system $AEHR sells locks in a recurring revenue stream. WaferPak contactors, DiePak carriers, and BIM consumables are proprietary, device-specific, and must be replaced regularly. This is razors-and-blades applied to semiconductor test equipment. Each FOX-XP system sold = years of consumable revenue at high margins. The installed base compounds. FY22–FY24: SiC/EV drove explosive growth. Revenue went from $22M → $65M. Gross margins hit 50%. Operating margins 20%+. FY25: EV programs delayed across the board. OEMs pulled back on SiC orders. Revenue fell to ~$60M then kept falling. Q2 FY26: $9.9M revenue. Gross margin: 29.8%. The stock got obliterated. Down 80%+ from peak. And then the AI orders started coming in. Q2 FY26 revenue: $9.9M ← confirmed trough H1 FY26 revenue: $20.9M (−21% YoY) H2 FY26 guidance: $25–30M revenue H2 FY26 bookings guidance: $60–80M That bookings number is the key figure. Management was explicit: the $60–80M is based on specific customer forecasts provided to $AEHR — not internal projections, not aspirational targets. Customers told them what they plan to order. Bookings in H2 FY26 ship and recognize as revenue in FY27 (which starts June 2026). FY27 is the inflection year. Management has stated the AI processor TAM is 3–5× larger than the SiC/EV market that drove the FY22–24 peak. Think about what that means: - Peak SiC revenue: ~$65M - If AI TAM is 3–5×: $195–325M revenue potential - Current market cap: ~$400M You're paying ~1.2–2× peak revenue for a company at trough, with a confirmed monopoly position, zero debt, and three orders in the last 30 days. The balance sheet is a genuine differentiator Zero long-term debt. ~$31M cash. No equity raises since the downturn. Compare that to $ENTG with $3.4B net debt from the CMC acquisition, or $LWLG burning $21M/year pre-revenue. $AEHR can execute without diluting you. But it's not a layup 1. Extreme lumpiness. Systems are $3–5M+ each. One delayed order swings quarterly revenue 30%+. This has happened multiple times. 2. Customer concentration. A handful of hyperscalers likely represent 80%+ of near-term bookings. Any program cancellation is devastating. 3. Gross margins still compressed. 29.8% last quarter vs. 50% at peak. Recovery requires volume ramp to arrive on schedule. 4. SiC is still dead weight. Legacy EV exposure hasn't recovered and occupies capacity. TLDR: $AEHR has a monopoly on a process that is physically required to ship AI processors at scale. Revenue is at a confirmed trough. Three orders have arrived in 30 days. Management has reinstated specific bookings guidance ($60–80M H2) based on customer forecasts. FY27 is the inflection. The balance sheet is clean. The TAM is 3–5× the peak that drove the last cycle.
中文
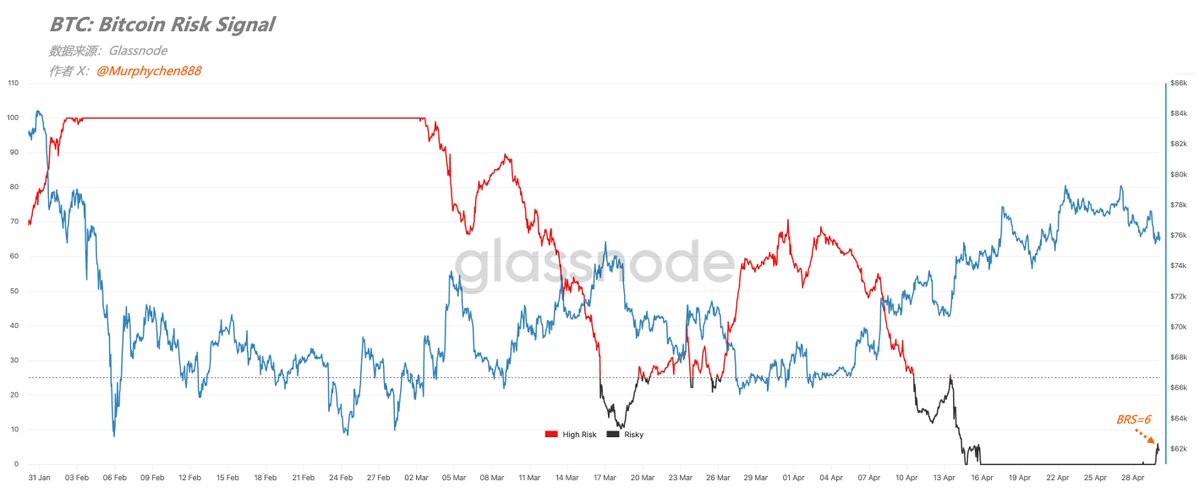
BRS离开零轴了!
正如我们之前所聊到的,并不是BRS一回到零就是顶点,但大概率会是一个阶段性的顶部区间(历史样本准确率达80%+)。
BRS也不可能永远停在零轴,一旦离开就是回调的开始。
昨天晚上当BTC跌至$75,500,BRS离开零轴,目前为6;同时,BSS也从0.68的高位降至0.36。
我们把2个指标结合:
当BSS > 0.5 且同时 BRS = 0,通常可以提升我们对”阶段性顶部“的判断概率;
当BSS < 0.3 且同时 BRS = 100,通常可以强化对”有性价比的底部区间“的判断概率;
所以接下来,我们只要耐心的等待BRS回到100,且BSS < 0.3的时候,这就是有性价比的买点位置。

Murphy@Murphychen888
BRS从4/16至今,一直被死死的钉在了“0”的位置。在BRS=0的时间段,就是BTC阶段性筑顶的过程。 并不是一回到零就是顶点,但BRS也不可能永远停在零轴,一旦离开就是回调开始,只是我们不知道需要多久。 就像2月3日BRS触及100后意味着BTC进入阶段性的底部区间,这期间BTC到过62,也到过73。 而这次回到零轴,对应BTC是在75左右,所以停留在零的时间段内,BTC会不会上冲到80、81?这我不能确定,尤其永续合约严重的负溢价(具体见引文)。 但我能确定是:当前上升过程伴随的“获利了结”,正在严峻考验“需求端”的承接力。 截止22日,24小时平均已实现利润为4,761万美元;还是小于4月14日至$76,000时的5,478万美元。 而这次不再是“遇到周末”的原因。那么“价格行为”与“实现利润”背离,就是上升势能开始衰减的迹象。 同样的,会背离几次?我也不知道。 也可以反复背离的同时,价格持续突破。直到打破背离(确认趋势反转),或开始回调。 所以,在没有打破背离之前,综合BRS及其他数据指标来看,我认为现在仍然是反弹且接近临界点的状态。 至于短期还能不能再冲一下?那就不是BRS和24h-RP能给出判断依据的了。
中文
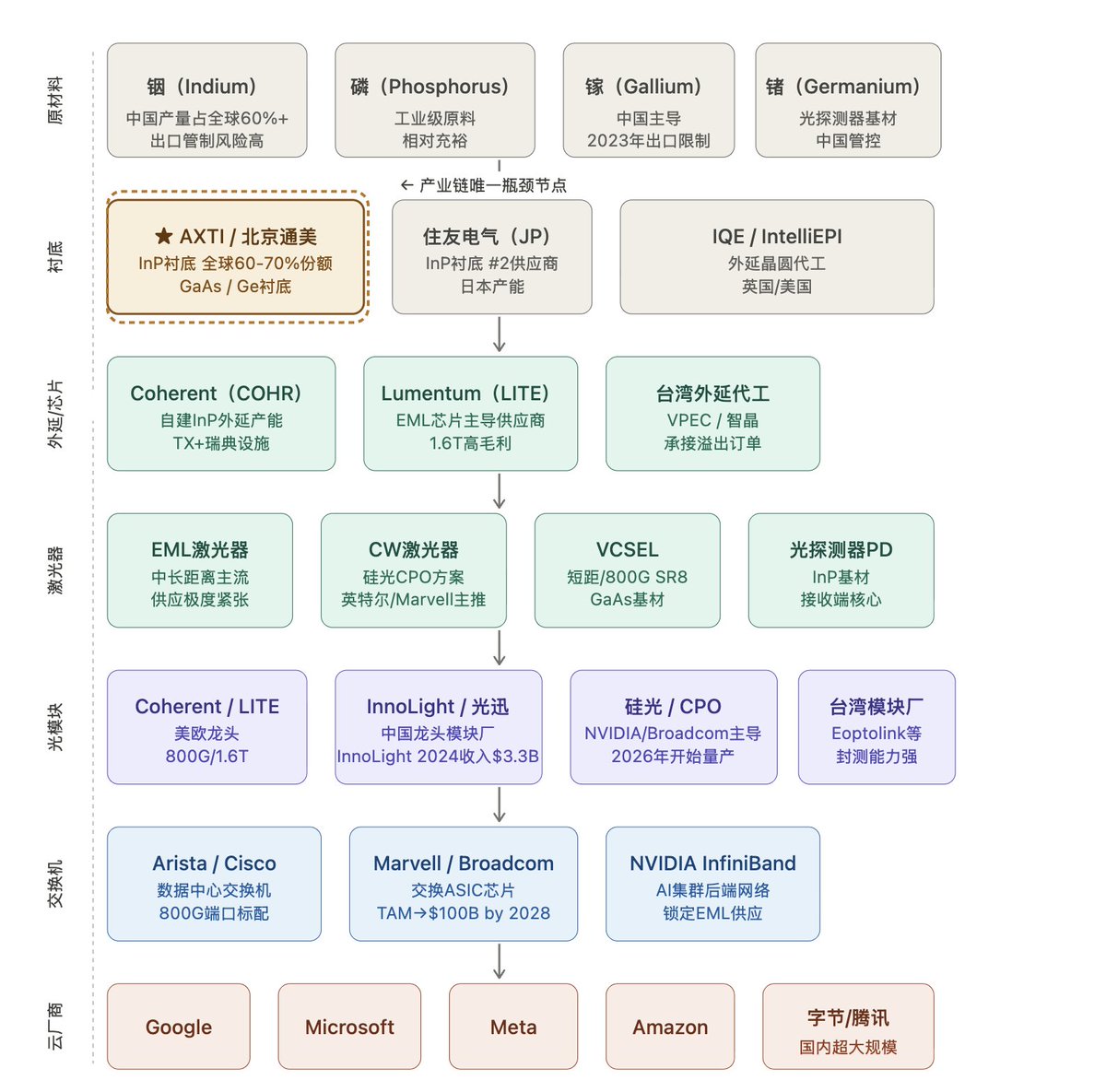
如果你想真的了解光通讯产业链,那以下的内容不容错过——一图了解全产业链。
文章稍长,但是把光通讯的每个环节都讲的清楚明白需要费一些笔墨。
光通讯相比较电信号本质上还是一种信息传输的方式。只是光通讯更加高效,可以传递的信息量/速度都远优于传统的电缆。现在数据中心不可逆的趋势,就是需要传递的数据量的指数级增长。这个背景下,光通讯的流行和应用是势之必然。
—---------------------------
整条链我分成了6个板块,我们一个一个来看。
1️⃣原材料,基本中国是龙头
铟(Indium)是一种稀有金属,主要产在中国,全球产量里中国占60%以上。铟本身没什么特别用处,但和磷结合之后,就变成了磷化铟(InP)——这个组合有一个神奇的物理特性:通电之后会发出激光。
镓(Gallium)也是稀有金属,中国2023年宣布出口限制,和砷结合变成砷化镓(GaAs),也能发光,用在短距离的场景。
做一个类比:原材料就像是"面粉"。面粉本身不是食物,但没有面粉就做不出面包。铟和镓就是制造激光器的"面粉"。
2️⃣衬底层
把铟和磷在极高温度下熔融、结晶、切片,就得到一片圆形的薄晶圆,叫做磷化铟衬底(InP Substrate)。直径约4-6英寸,看起来就像一片黑色的圆玻璃。
它是所有后续加工的基础材料,就像做芯片要先有硅晶圆一样。没有这片衬底,后面的激光器根本没有东西可以"长"在上面。
衬底就是"白纸"。在上面可以画出激光器的电路结构。 $AXTI 是全球最大的白纸供应商,占全球60-70%的份额。另一家是日本住友。
3️⃣外延/芯片
拿到InP衬底之后,用一种叫外延生长(Epitaxy)的技术,在这片晶圆上一层一层地沉积几纳米厚的半导体薄膜,形成精密的量子结构。这个过程就像在白纸上精密印刷电路。
这步做完之后,晶圆上就有了激光器的"基因"——一个可以在通电后发光的微小结构。然后把晶圆切成一个个极小的芯片颗粒,每一颗就是一个激光芯片(Laser Die)。
外延相当于"在面团上发酵",让基础材料产生功能性结构。这一步技术门槛极高,良率只有15-50%,大量芯片在这步就报废了。
4️⃣激光器——让“信号”发光
激光器就是把上一步做好的激光芯片封装成一个可以使用的元件。通电之后,它会发出特定波长的红外激光——肉眼看不见,但光纤最爱传这个波段。
激光器是灯泡,光模块是台灯。没有灯泡,台灯就是一个空壳。
5️⃣光模块——光电世界里的翻译官
光模块(Optical Transceiver)是一个大约手指大小的小盒子,直接插进服务器或交换机的插槽里。它里面装着:激光器(发光)、光探测器(接收光)、驱动芯片、镜头和光纤接口。
它的作用是双向翻译:服务器发出电信号 → 光模块把它变成光信号打进光纤;光纤传来光信号 → 光模块把它变回电信号送给服务器。
光模块是连接两个世界的翻译官,他把光世界的语言和电世界的语言来回翻译。
6️⃣交换机层 ——指挥交通、分拣信息
交换机(Switch)是一台专门负责"分发数据"的设备,长得像一个扁平的大铁箱子,正面插满了几十上百个光模块插槽。
在AI数据中心里,成千上万台GPU服务器要互相通信——比如一个大模型训练任务,可能同时用到1万块GPU,它们之间每时每刻都在交换中间计算结果。交换机就是负责把这些数据包准确、快速地送到对的GPU。
一台顶级AI交换机(比如博通的Tomahawk系列)上面可以插128个800G光模块,每秒总吞吐量超过100Tb。
交换机很像我们现实世界的快递中转站。每个包裹(数据包)进来,它看一眼地址,立刻分拣到正确的出口。速度极快,几纳秒就完成一次分拣。
—---------------------------
最后的最后,就是大客户们买单了。
看完这这链条,再炒CPO光通讯,心里是不是有谱多了?
中文

非常深度一篇文章,从GPU架构进化的第一性原理出发,重点解答市场长期担忧的问题:为什么每个GPU的HBM内存需求必然是指数级增长?为什么HBM需求不会像传统DRAM那样停滞或周期性崩盘?记录个要点当做阅读笔记
1. AI推理时代的核心KPI已彻底改变
CPU时代:最高KPI是“performance / FLOPS”(跑分越快越好)。
AI推理时代(尤其是agentic flow兴起后):最高KPI变成token经济学——单位成本/单位电力下的token吞吐量(throughput) + token生成速度。
Nvidia的“AI工厂”本质就是:最低成本输出最多token,同时尽量提高token速度。Pareto frontier曲线要不断向右上方移动。
2. Token吞吐量的第一性原理公式(核心结论)
Token throughput = HBM Size(容量) × HBM Bandwidth(带宽)Batch size(同时处理的请求数) 的瓶颈 = HBM Size
因为每个请求都自带hot KV cache,必须放在HBM里。随着batch增大,KV cache线性增长,HBM容量必须同步线性增长(否则就像接驳车车厢太小,要分多趟拉人)。
每个user的token生成速度 的瓶颈 = HBM Bandwidth
生成每一个token都要多次高频读取HBM里的权重和KV cache。带宽越高,decode速度越快(就像接驳车车门越宽,旅客上下车越快)。
完整类比:
吞吐量 = 接驳车车厢容量(HBM Size) × 车门宽度(HBM Bandwidth)。
只要想让token吞吐量每一代翻倍,HBM的Size × BW乘积就必须翻倍。这是硬件天花板,软件优化无法根本替代。
3. CPU时代 vs. AI时代的本质差异
CPU时代:DDR只是“辅助”,升级极慢(DDR3到DDR5花了15年)。
原因:CPU有大量cache、superscaler等隐藏延迟;日常workload对带宽/容量需求低;app size增长慢。
AI/GPU时代:计算范式彻底转向“memory-bound”(内存受限)。
推理即内存,KV cache + 上下文长度 + 多请求并发,把所有压力都压在HBM上。HBM已从“锦上添花”变成决定性因素。
4. 验证与现实对应
Nvidia从A100 → Rubin Ultra的token吞吐曲线,与HBM Size × BW曲线在对数轴上几乎完全重合(文章提到图二)。
即使利用率(utilization)很难达到100%,HBM仍是整个系统的天花板。老黄必须逼御三家(三星、海力士、美光)不断升级,否则GPU就卖不出去。
5. 软件优化无法改变硬件需求
软件再优化(如LPU把权重搬到SRAM),也只是从另一个维度改善Pareto曲线,硬件天花板仍由HBM决定。就像CPU时代软件再快,CPU厂也必须持续升级跑分一样
fin@fi56622380
AI半导体终局推演2026(I) 当新token经济学范式从GPU算力转移到HBM 本文从从GPU架构进化路线本质出发,解释这个市场长久以来担心的问题: 每个GPU的HBM内存需求为什么一定会是指数增长,为什么HBM需求指数增长不会停滞? 并推导token经济学在当前架构下第一性原理:token吞吐 = HBM size X HBM BW带宽 同时讨论了,为什么GPU的天花板被HBM的两个发展维度所决定 HBM周期性这个话题争议一直很大,乐观派认为AI带来的需求比以前要大的多,但市场主流仍然认为前几次上升周期也有需求每年20%+增长,这次又有什么不一样呢?AI不影响HBM和传统DRAM一样有commodity属性,一旦在需求顶峰扩产遇上需求下行又会重蹈覆辙。 我们可以从算力芯片架构视角,从第一性原理出发,来拆解和推演一下这个问题:为什么这次真的不一样 ------------------------------- 历史:CPU算力时代 很久以来,我们都处在CPU主导算力的时代,CPU的最高级KPI就是performance,跑的更快,所以每一代的CPU都用各种方法来提高跑分,最开始是频率上升,后来是架构演进superscaler等等 这个时候为什么DDR不需要很快的技术进步速度?比如DDR3到DDR5竟然经历了15年之久 因为这个时期的DDR的角色是纯粹的辅助,而且辅助功能极弱,以业界经验,DDR的速度即便是提高一倍,CPU的performance一般只能提高不到20%这个量级 为什么DDR带宽速度提高了用处不大?两个原因 1. CPU设计了各种架构去隐藏 DDR延迟,比如superscaler,加大发射宽度,用海量的ROB和register renaming来提高并行度隐藏延迟,一级缓存cache,二级缓存cache,削弱了DDR的带宽速度需求 2. CPU workload对DDR带宽要求并不高,大部分日常负载比如打开网页,DDR带宽是严重过剩的,甚至云端负载 也就是说,在CPU时代,DDR的带宽速度是不太有所谓的,DDR4和DDR5除了少数游戏就没啥差别,甚至JEDEC标准也进步缓慢。 另外,绝大部分app需要一直停留在DDR上的部分并不多,需要的时候从硬盘上调度到DDR即可,app的size增长没那么快,导致对DDR的容量需求也较为缓慢。 所以最近十年来,平均每台电脑上的DDR容量大概从7~8GB变成了23GB,十年只增长了3倍。 而这部分升级缓慢直接影响了营收,size容量计价是赚钱的主要方式,速度的提高只是技术升级,提高size的单价,这两个的升级需求都不大,需求主要是随着电脑/手机数量增长而增长 所以DRAM在带宽速度和容量这两个维度上,一直是都是芯片产业锦上添花性质的附属品,DDR升级带来的边际效用是很低的,跟CPU时代的最高KPI几乎没什么直接联系 -------------------------------------------- 而到了genAI 大模型为主导的新时代,计算范式转移让最高级KPI起了根本变化 GPU发展到AI推理的时代,不再像CPU那样只看跑分,最高级的KPI不再是算力TOPS/FLOPS,而是token的成本,特别是单位成本/单位电力下的overall token throuput 其次是token吞吐速度,因为在agent时代,很多任务变成了串行,token吞吐速度成了用户体验的重要瓶颈。 这也是为什么老黄发明AI工厂概念的原因:最低成本的输出最多token,同时尽量提高token吞吐速度 AI训练时代,老黄的经济学是TCO(total cost ownership),买的GPU越多,省的越多 而老黄在推理时代的token经济学是: AI推理的毛利润很可观,所以逻辑已经转换成:Nvidia GPU是这个世界上让token单价最便宜的GPU,买的GPU越多,赚的越多 最高的KPI变成了Pareto frontier曲线,在提高token 吞吐throughput和提高token速度两个维度上尽量优化 (见图一) NVIDIA 的 token factory 代际进步,其实是在把整条 Pareto frontier 往右上推,这就是是AI推理这个时代最重要的KPI ---------------------------------- 接下来是本文最重要的逻辑链,如何从token吞吐量指数型增长的本质出发,推导出天花板瓶颈在HBM size和HBM 带宽的指数型增长 单卡GPU推理单线程batch size = 1的时代,token吞吐只有一个维度,就是HBM的带宽速度,带宽速度越高,token吞吐越大 但进入NVL72的年代,推理不再是单卡GPU时代,而是72个GPU + 36个CPU整个系统级别的token工厂,把HBM带宽和算力用满,获得极致的token吞吐量 Token 吞吐throughput的增长,依赖两个东西:同时批处理的请求数 X 每个user请求的平均token速度 也就是batch size X per user token 速度 以Rubin NVL72为例,在平均token速度是100 token/s的情况下,同时批处理1920个请求,得到token吞吐量是19.2万token/s 一个Rubin NVL72大概是120KW(0.12MW)的功率,所以得到单位MW能处理1.6M token/s (见图一) 所以,我们需要想方设法提高这两个参数:批处理数量batch size和per user token的平均速度,这两者相乘就是我们的最高KPI,也就是token的吞吐量 ------- 第一个参数:batch size的增长,瓶颈在HBM size 批处理量里的每一个请求req,都会自带kv cache,这部分kv cache是需要存在HBM里的,大小大概在几个GB到数十GB不等 因为hot kv cache是随时需要高频高速读取,所以必须放在HBM里,比如一个大模型的层数是80层,那么每一个token的生成阶段,都需要读取80次HBM里的kv cache 随着批处理数量batch size的增长,会带来hot kv cache的线性增长 又因为这个批处理量的所有请求的hot kv cache,都要放在HBM上,这也就带来了HBM size必须要随着批处理量batch size线性增长 就像是机场接驳车,登机口尽量快的接旅客到飞机,HBM size小了,相当于接驳车size小了,就得多接一趟 结论是:批处理量的数量batch size,瓶颈依赖于HBM size的增长 --------- 第二个参数:每个user请求的平均token速度,瓶颈在HBM带宽 大模型decode阶段的速度,瓶颈取决于HBM的带宽速度,因为每生成一个 token,都要把激活的权重和kv cache 读很多遍 LPU的出现,在batch不那么大的情况下,把激活权重这个部分搬到了SRAM上,但是每生成一个 token仍然要从HBM读很多次KV cache。HBM带宽越高,生成每一个token的速度也就越快,基本上是线性对应的 就像是机场接驳车,登机口尽量快的接旅客到飞机,hbm本身带宽速度就像是接驳车的车门有多宽,门越宽,旅客上接驳车越快 GPU的其他配置,都是在适配batch的增长以及要让token compute的速度配平HBM的增长,甚至会用多余的算力来获得部分的带宽(比如部分带宽压缩技术) —----- 在那个接驳车的比喻例子里 接驳车的车厢大小 = HBM Size(容量): 决定了一次能装下多少名旅客(也就是能同时装下多少个请求的 KV Cache)。车厢越大,一次能拉载的旅客(Batch Size)就越多。如果车太小,想拉100个人就得分两趟,系统整体的吞吐量就上不去。 接驳车的车门宽度 = HBM Bandwidth(带宽): 决定了旅客上下车的速度。门越宽,大家呼啦啦一下全上去了(Decode/生成Token的速度极快)。如果门很窄,哪怕车厢巨大能装200人,大家也得排着队一个一个挤上去,全耗在上下车的时间里了。 旅客的吞吐量 = 接驳车车厢容量 x 接驳车旅客上车速度(车门宽度) —--------------------------- 至此,我们从逻辑上推演出了token经济学的硬件需求第一性原理: Token throughput = HBM size X HBM Bandwidth AI推理这个时代的最高KPI,实际上是高度依赖于HBM的两个维度的进步的 如果要维持token throuput每一代两倍的增长,实际上意味着,每一代的单GPU上,HBM size X HBM BW带宽之积要增长两倍! 这也是历史上第一次,HBM内存的size可以影响最高的KPI token throughput! 要验证这个理论,可以把Nvidia从A100到Rubin Ultra这几代的token 吞吐throughput,和HBM size X HBM BW 放在同一个图里比较 (见图二) 可以发现,这两个曲线的走势在对数轴上惊人的一致 HBM size x HBM带宽增长的甚至要比token吞吐量更快,毕竟HBM决定的是天花板,实际上这个天花板增长的利用率utilization是很难达到100%的,也就是说,HBM size x HBM 带宽就算增长1000倍,其他算力和架构的配合下,很难把这1000倍的天花板潜力全部榨干 这条曲线不是巧合,而是系统最优化的必然解 throughput = batch × Bandwidth,这就是token factory 经济学最绕不开的第一性原理 —-------- 软件的影响呢?软件的优化会不会降低带宽的需求?降低HBM的需求? 这跟硬件是独立两个维度的,这好像在问,如果CPU上的软件优化了之后跑的更快,是不是CPU就十年不用发展了?反正软件跑的更快了嘛 这样的话,CPU厂还能赚得到钱吗?CPU想要存活下去,只有一条路可走,在标准benchmark,不考虑软件优化,每一代CPU必须要跑分更高,不然就卖不出去 GPU也是一样,软件优化如何,和自己的token吞吐量KPI每年都要大幅进步,是两回事 只要token的需求继续增长,对token throuput的追求就绝不会停止,那么对HBM size X HBM 带宽的追求也不会停止 如果HBM size和HBM 带宽发展慢了,老黄一定会亲自到御三家逼着他们技术升级,因为这就是老黄gpu的天花板,天花板要是钉死了不进步,老黄的GPU还能卖出去吗? 当然了,Nvidia需要绞尽脑汁去从异构计算的架构角度榨取HBM天花板之外的部分,比如LPU就是一个很好的尝试,把Pareto frontier从另一个角度改善了很多 (右半边高token速度的部分) —-------------------------------------- HBM内存已然告别了那个随波逐流的旧时代,在这条由指数级需求铺就的单行道上,以一种近乎宿命的方式走到了产业史诗的主舞台中央 推理范式第一性原理演化到这一步,只要老黄还要卖GPU,HBM就必须翻倍,而且必须代代翻倍。这是supply side的内生压力,与AI需求无关,与宏观周期无关,与hyperscaler的心情也无关 剩下的问题,只有一个: 当需求被物理锁定为指数增长的时候,供给侧的三个玩家,会不会还像过去三十年那样,亲手把自己再拖回一次周期的泥潭?
中文
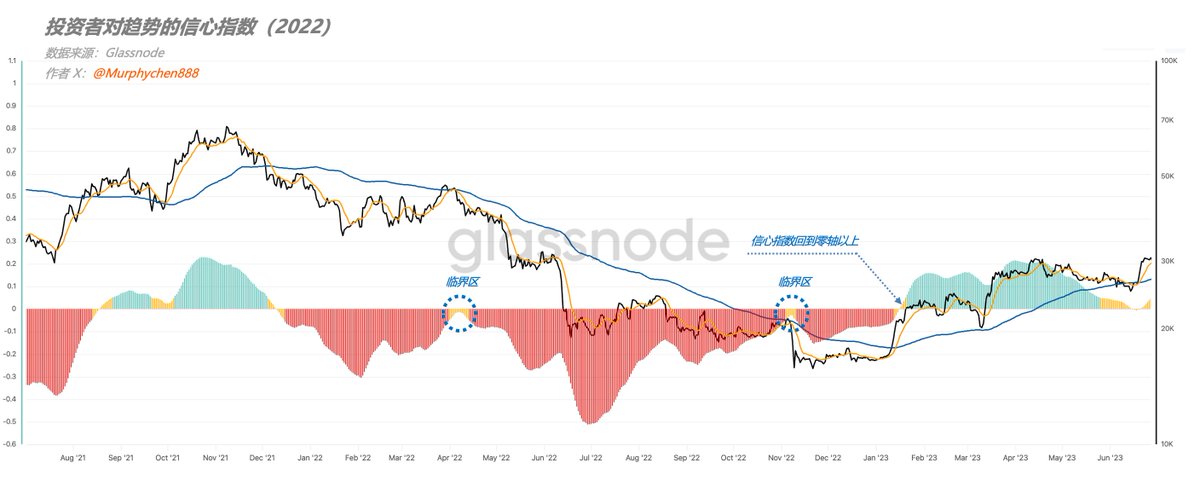
历史从来不会重演,但会押韵!
虽说如此,但我也没想要会如此押韵......
“投资者信心指数”几乎走出了与上轮周期完全一致的波动形态。只是相比于2021年12月-2022年1月,如今这段更“迷你”,跨度更短。
截止到4月20日红色区距离回到上方零轴的距离与2022年10月22日一样。
也就是说,如果没有后面FTX暴雷的黑天鹅事件,“投资者信心指数”大致将在20多天后回到零轴。
回到零轴将意味着什么,不用我多说了吧?这将是一个重要的里程碑!
即便后面BTC再次下探,甚至跌破前低,只要红色区的偏离幅度小于之前的低点(标注3),我们就可以确认:这是本轮熊市的“最后一跌”。

Murphy@Murphychen888
“物极必反” 这一自然规律放到金融市场也一样有效。 在3月2日的推文中,我们看到”投资者信心指数“出现了一个并不常见的“极端负值”。 在历史上但凡能市场情绪能低落到如此程度的,此后要不迎来一段反弹行情,要不实际上已距离熊底不远了。 虽然,时至今日我们仍然不知道当前是否就属于后者,但至少”反弹“是看到了。 与此同时,信心指数正随时间推移不断的向零轴靠近。只要站上零轴,即表示熊市结束。 我们可以做个不那么严谨的测算:如果此后在没有任何意外导致中断的前提下,按近10天的平均速度,回到零轴大约还需要 —— 47天! 我知道,这样的计算可能并不具备任何实际意义。因为往往都是“不出意外的话意外就要出现了......” 但可以给我们自己一点信心, 比特币的世界,从来没有永夜! 当第一缕阳光撕开黑暗时,迷雾终将散尽。
中文


Charles Schwab(嘉信理财)正式推出 #Bitcoin 和 #Ethereum 的现货交易,每笔交易收取 0.75% 的手续费。
每位客户会有一个单独的加密账户,该账户由 Charles Schwab Premier Bank, SSB 提供,底层的子托管和交易执行则由 Paxos 提供。
未来嘉信理财计划再加更多币种,以及充币、提币功能。

Phyrex@PhyrexNi
传统金融巨头 Charles Schwab(嘉信理财)计划在未来 12 个月内上线 $BTC 和 $ETH 现货交易功能。
中文

身边有个同事,年过四十,天天念叨着不想上班了,说手里攒了200来万存款,想去鹤岗定居,安安稳稳度余生。我劝他别冲动——真要养老,何必跑那么远?
你拿圆规在广州中心戳个点,画个60公里的圈,圈里随便拎一个城市出来,都比鹤岗舒服太多!既有一线城市的配套加持,又没有一线城市的压力,廉价工业品随便买,交通快递都方便,珠三角范围内快递隔天准到,医疗资源也够给力,随处都能找到老广私藏的地道饭馆。关键是气候好,年均气温23.8℃,一年到头穿双拖鞋就够了,省心又自在。
就说我最近挖到的宝——佛山高明,真的越了解越心动,养老简直绝了!
它离广州市区也就68公里,到佛山市区才35公里,开车一小时就能到广州,完全就是广州的卫星城,跟淀山湖之于上海似的,但环境比淀山湖还好,清净又干净。
最惊喜的是房价,一线江景的洋房,才4000出头一平!要知道昆明的三线养老房都得9000多,这价格直接打平云南一众养老城市,而且还是万科的物业,住着也放心。
生活配套更是拉满:楼下五百米就是公园,饭后散步遛弯再方便不过;酒吧街、烧烤店、民俗文化广场就在附近,晚上想热闹也有去处;体育中心建得堪比奥体,想运动健身也不用跑远。
更绝的是,离家里两公里就是一线沙滩,沙子细腻,波光粼粼的,上次跟朋友去,两个大男人跟个小孩似的玩沙,还有个朋友开着前驱轿车硬要去沙里浪,别提多好笑了。
两公里外还有个机动娱乐场,里面摩天轮、跳楼机、海盗船一应俱全,冲卡还送钱,一个项目才30块,能玩到你吐。家里有小孩的,估计能天天吵着去,我家娃就特别迷这个。
去年我和老婆周年纪念日,就去坐了摩天轮,30块钱一次,性价比拉满!对比一下顺德的摩天轮,要95块一次,比伦敦眼还贵,简直坑人。
家门口就是西江,一到夏天,就有好多老头在江边游泳,特别有生活气息。去年我朋友手机不小心掉江里,还是一位大爷帮忙捞上来的,后来朋友请大爷吃了顿宵夜,一来二去还熟络起来了。
有人说夏天热?放心,避暑的地方多到数不清!
有那种氛围感拉满的度假区,假装在欧洲,啤酒、烧烤、游泳一站式搞定,找几个朋友AA,人均150块,租个泳池别墅,玩到你腻歪都不想走。家门口还有酒吧泳池一条街,晚上约上朋友小酌几杯,微醺又惬意。
高明的茶山那边,全是这种避暑山庄,去那吃饭,游泳都是免费的,从市区开车过去也就二十分钟,周末过去放松一下,太舒服了。上次去游泳,还有小鱼一直追着我游,甚至还咬我一下,有没有懂的朋友,这到底是什么鱼啊?
要是不想花钱,就开远一点去溯溪,山清水秀的,玩累了在溪边歇一歇,吹吹凉风,别提多爽了,就是记得玩完别留下垃圾,爱护环境人人有责。
想去看海也不远,开车到江门京海也就一小时,不过我还是更推荐阳江的海,虽然远一点,大概两个半小时车程,但海水更蓝、风景更好看,江门的朋友可别打我啊!
商业配套也不用愁,有商业综合体,虽然跟万达比还差那么点意思,但日常购物、吃饭、看电影完全够用,不用跑远路。
最关键的是物价,简直是养老福音!早餐5到8块钱就能吃饱,一碗地道的濑粉也就12块,性价比拉满。
还有个小彩蛋,高明居然有机场!这一点,估计苏州人都得羡慕哭,毕竟淀山湖那边可没有这待遇。
更绝的是,佛山肉联厂就在高明,能买到刚屠宰完、还带着体温、甚至还会动的牛肉,才38块钱一斤!肉联厂对面就有加工的地方,20块钱一围,自己动手烤,新鲜又好吃,想想都流口水。
说实话,我现在都心动了,真想早点退休,去高明过上这种神仙日子。所以劝我那同事,别一门心思往鹤岗跑了,广州周边这么好的地方,何必舍近求远呢?
中文



$MSTR 本周再次买入 13,927 枚 $BTC ,总花费 10 亿美元,平均价格 71,902 美元,截止到 2026年4月12日 MSTR 共持有 780,897 枚 Bitcoin ,总成本约 590.2 亿美元,总平均价格为 75,577 美元。
Phyrex@PhyrexNi
👍 $MSTR 疑似继续买入 Bitcoin
中文


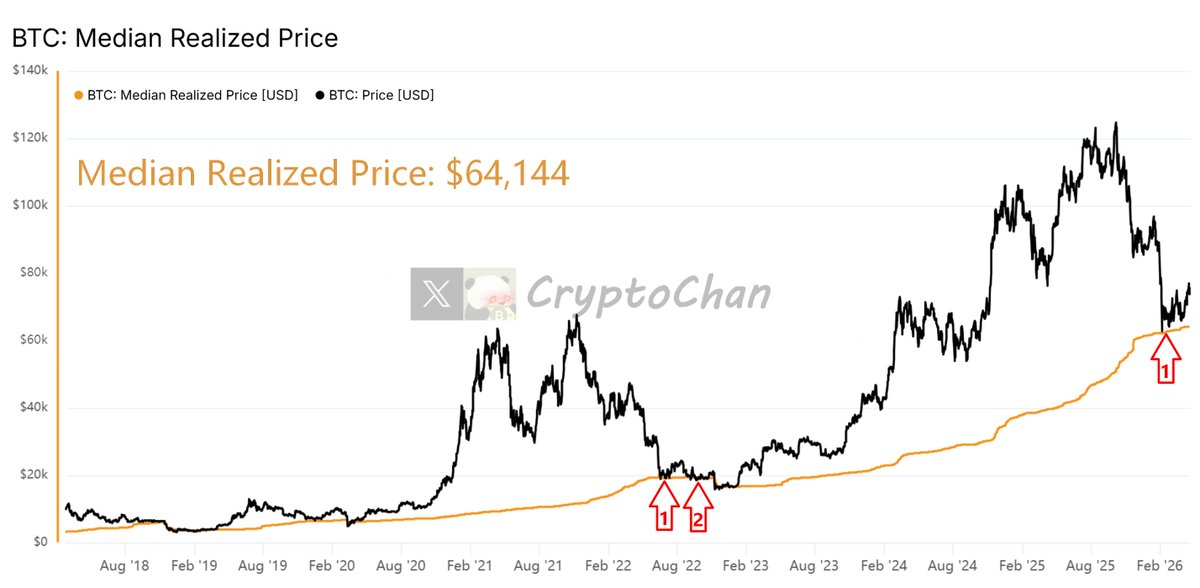
【四年周期系列更新📊】历史上 #BTC 各轮熊市最后一跌前后,黑线往往依次跌破橙线、蓝线、绿线
当前黑线已跌破橙线,距离跌破蓝线还差 $312 刀

CryptoChan@0xCryptoChan
【四年周期总刻系列(23)】 历史上 #BTC 每轮熊市最后一跌前后,黑线均会依次下穿橙线、蓝线、绿线 当前黑线已下穿橙线 ┌── 📑 𝗗𝗲𝗲𝗽 𝗗𝗶𝘃𝗲 | 指标详情 ──┐ 黑线为链上持币0-10年投资者平均购币成本 橙线为链上持币6个月-5年投资者平均购币成本 蓝线为链上持币6个月-7年投资者平均购币成本 绿线为链上持币6个月-10年投资者平均购币成本
中文