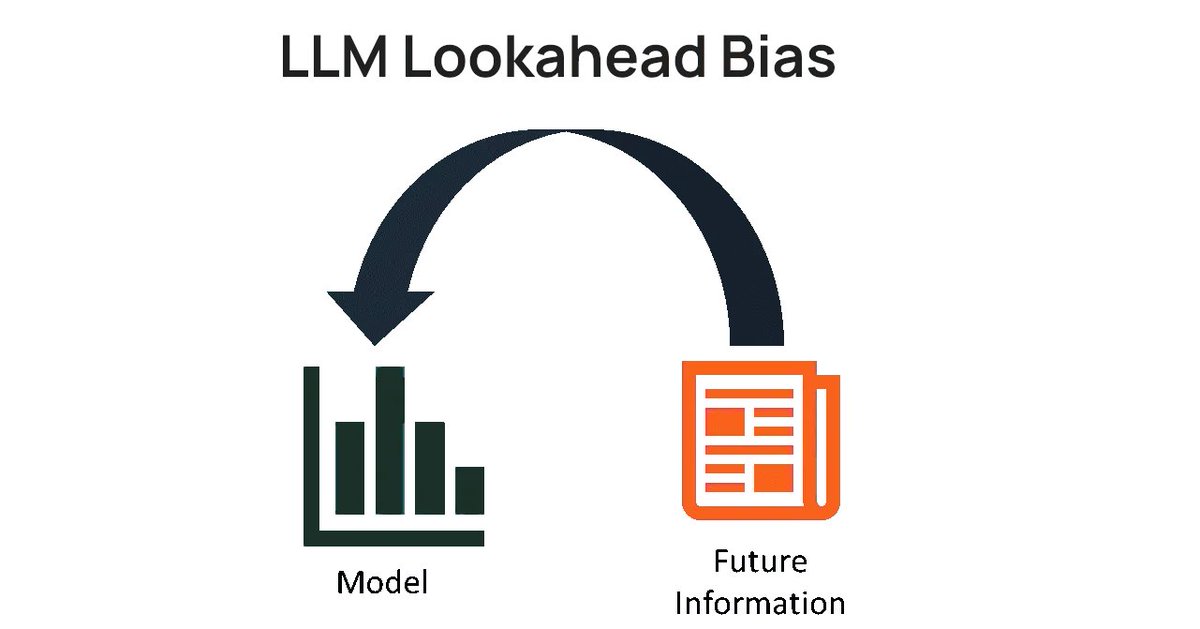
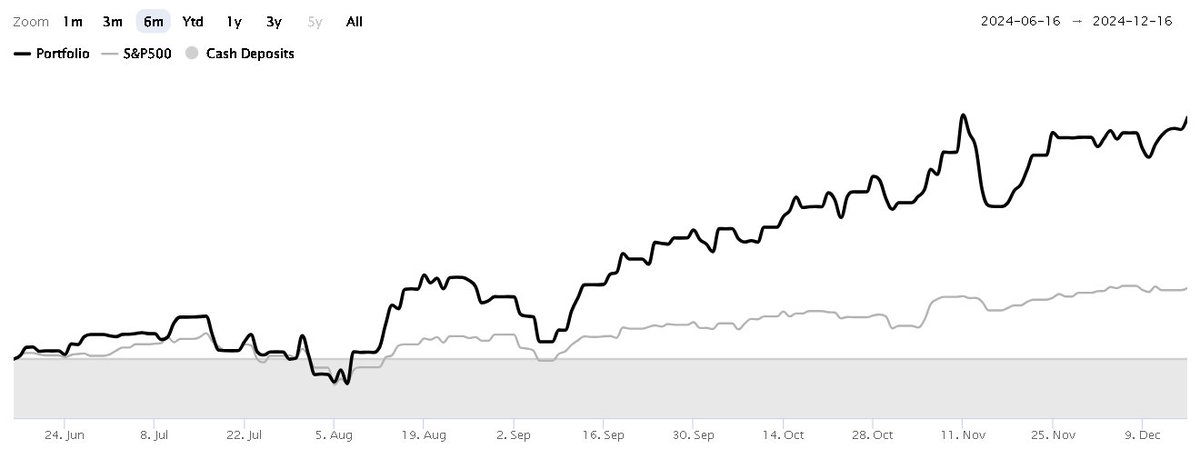
All tested models lost the vast majority of their alpha when tested out of sample. For example, DeepSeek 3.2's strategy generated +20.7% annualized alpha in-sample, and -1.0% out-of-sample.
Bigger models had bigger drops in out-of-sample performance. More parameters just meant more memorization.
Full writeup: vbase.com/blog/llm-alpha…
English