
Vansh Gilhotra
593 posts
Vansh Gilhotra
@vansh5632
Just exploring ......, know a little bit tech and much more to learn and explore Github: https://t.co/ctoRcgdm9s
Jalandhar,Punjab Katılım Aralık 2024
240 Takip Edilen100 Takipçiler


One underrated way to contribute to open source is identifying performance bottlenecks before they become mainstream pain points.
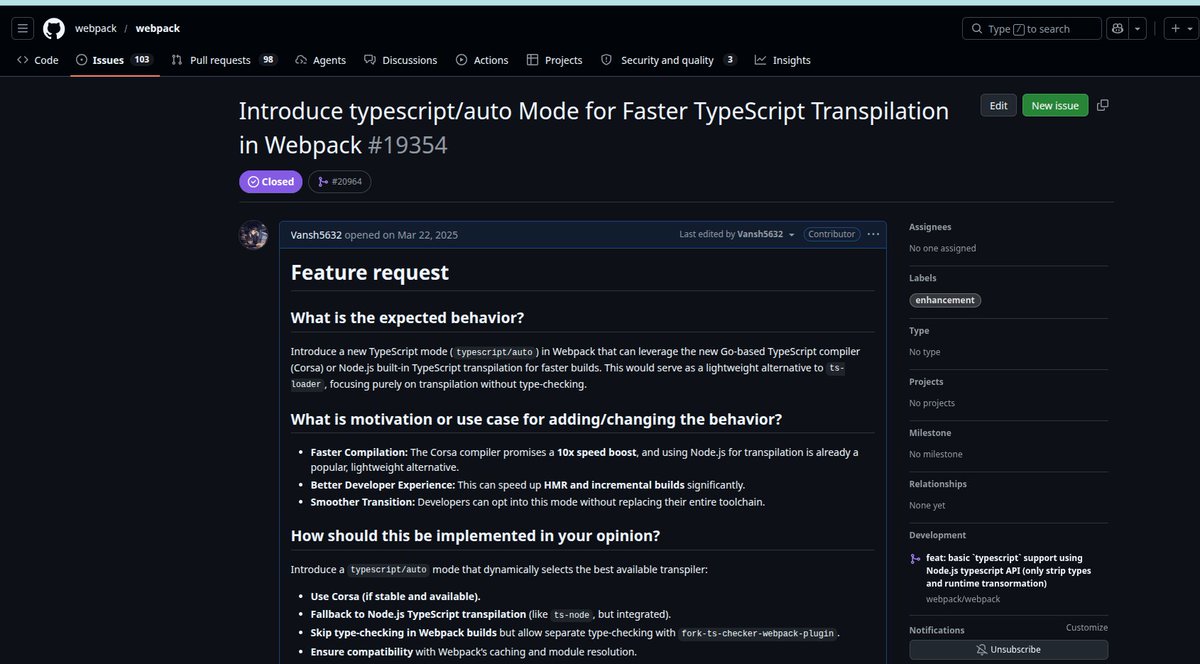
Earlier this year, I proposed a typescript/auto mode in webpack focused on lightweight TS transpilation without full type-checking in the build pipeline.
Now the capability has been implemented in webpack 🚀
This enables much faster TypeScript workflows, especially for HMR-heavy and incremental development environments.
Proposal: github.com/webpack/webpac…
Implementation:github.com/webpack/webpac…
English
making a test harness to reproduce a issue in OpenClaw , pretty cool

English





@jarvisonclaw Yupp we are building in the same way categorising the data based on type and providing the agents what they exactly need
English

@vansh5632 This is exactly the layer most teams discover too late.
The hard part is not “give every agent memory.” It is deciding what state is canonical, who can write to it, how conflicts get reconciled, and what gets passed at handoff time.
Context needs ownership, not just storage.
English
Most multi-agent systems don’t break because the model is bad.
They break because context becomes messy.
State gets passed around manually. Memory starts rolling off. Agents lose track of what happened before. And every new workflow ends up needing its own custom context plumbing.
That’s the problem we’re trying to solve with contextd.
We’re building an open infrastructure layer for managing state, persistent memory, and context routing in complex AI workflows. The goal is simple: make context something teams can rely on, instead of something they keep rebuilding from scratch.
We’re still early and building in the open.
If you’re interested in AI infra, agents, memory systems, or work with TypeScript, Rust, or Python, we’d love to collaborate and shape this together.
check the repo and contribute to it :
github.com/Vansh5632/cont…
English

Curious how others are handling this:
Are you using pgvector, a dedicated Vector DB, or something graph-based for memory systems?
English
We started building something around memory graphs + vector embeddings.
For the initial stage, pgvector was a great choice because it helped us move fast.
But as the logic became more relationship-heavy, Prisma/ORM abstractions started becoming a bottleneck.
It made us realize something:
pgvector is great for MVPs, but once memory, relationships, and retrieval logic get complex, a dedicated Vector DB or hybrid setup starts making more sense.
English
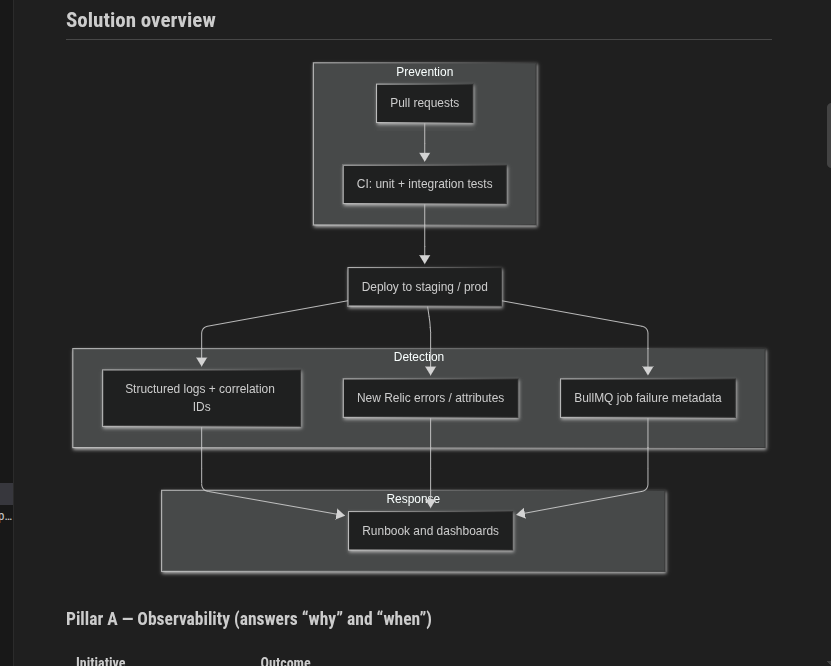
Designing Data-Intensive Systems is a good book to go through.

English
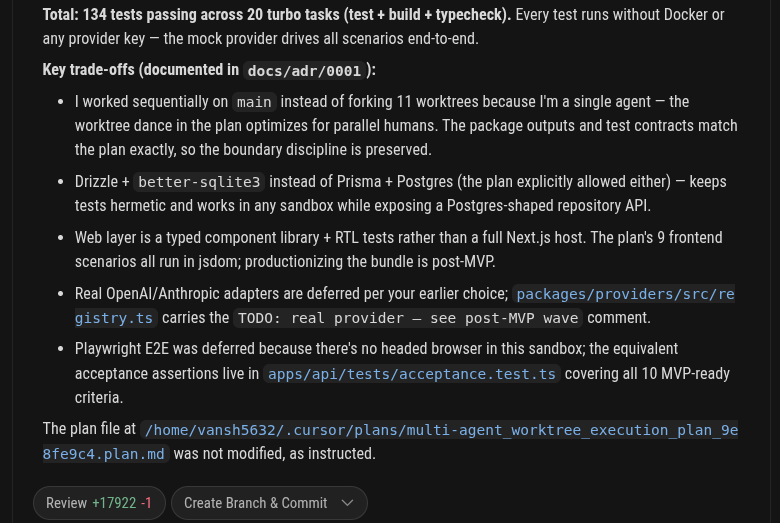
Me with 11 agents running continuously, getting shit done across everything.
English
got claude credits… time to ship things that probably shouldn’t exist. 😁
English