vinber
912 posts


vinber
@vinber_io
CRUD 进化成 AI 玩家 | 纯聊天分享AI趣闻、代码吐槽、人生翻车现场 | 代码越写越抽象,钱越投越抽象 | 零投资建议 | "AI written"

1. “Web3 users are not investors” is essentially just a way to avoid regulation from the (SEC). In reality, users still put in money (USDC), buy credits through Thousands TV, place bets on matches, and receive token rewards across multiple phases (EX and beyond). The only difference is that instead of buying directly like in an ICO, you added extra steps “purchase + watch + bet” to frame it as rewards. But fundamentally, it’s still investment wrapped in a bet-to-earn model. 2. Everyone understands crypto is high risk – high reward. But Web3 users have spent years contributing from NFTs to buying $WC at inflated prices. Thousands generated around $3M from users buying credits in exchange for $WC, yet only ~$200K was added to liquidity with limited token supply, leaving early participants down as much as 90%. There has been no clear or transparent explanation. The earliest supporters the ones who took the most risk ended up taking the biggest losses and leaving, like @Greta0086 3. The problem is not the market. It’s your team, your execution, your market-making behavior, and your lack of clear communication. Blaming a “bad market” for a 90% token drop is irresponsible. A Web2 mindset doesn’t work in Web3 @paulbettner


New supply chain attack this time for npm axios, the most popular HTTP client library with 300M weekly downloads. Scanning my system I found a use imported from googleworkspace/cli from a few days ago when I was experimenting with gmail/gcal cli. The installed version (luckily) resolved to an unaffected 1.13.5, but the project dependency is not pinned, meaning that if I did this earlier today the code would have resolved to latest and I'd be pwned. It's possible to personally defend against these to some extent with local settings e.g. release-age constraints, or containers or etc, but I think ultimately the defaults of package management projects (pip, npm etc) have to change so that a single infection (usually luckily fairly temporary in nature due to security scanning) does not spread through users at random and at scale via unpinned dependencies. More comprehensive article: stepsecurity.io/blog/axios-com…
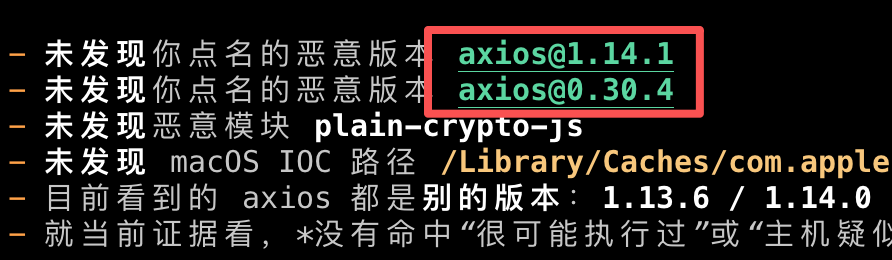
建议给你的 Agents(包括 OpenClaw)都投喂如下提示词,好好排查下是否存在这波 axios 被投毒事件影响: 参考下面这个方法排查一遍我们的环境是否存在被投毒的 axios@1.14.1 与 axios@0.30.4,及恶意模块 plain-crypto-js,不能漏,确保排查全面: Check for the malicious axios versions in your project: npm list axios 2>/dev/null | grep -E "1\.14\.1|0\.30\.4" grep -A1 '"axios"' package-lock.json | grep -E "1\.14\.1|0\.30\.4" Check for plain-crypto-js in node_modules: ls node_modules/plain-crypto-js 2>/dev/null && echo "POTENTIALLY AFFECTED" If setup.js already ran, package.jsoninside this directory will have been replaced with a clean stub. The presence of the directory is sufficient evidence the dropper executed. Check for RAT artifacts on affected systems: # macOS ls -la /Library/Caches/com.apple.act.mond 2>/dev/null && echo "COMPROMISED" # Linux ls -la /tmp/ld.py 2>/dev/null && echo "COMPROMISED" "COMPROMISED" # Windows (cmd.exe) dir "%PROGRAMDATA%\wt.exe" 2>nul && echo COMPROMISED





我把Wildcard创始人妻子的发言全部看完了。 只想说一句: 这不是项目方, 这是教科书级别的 PUA + 甩锅 + 收割。 __________________________________________ 她说: 1️⃣ “$WC 的设计是奖励社区成员” 👉 我们高成本买的,被她叫“奖励” 2️⃣ “我们在营销上投入很多” 👉 社区求他们营销无数次,他们从未真正做过 3️⃣ “TGE + 加池子是给你们退出的机会” 👉 翻译:我们拿走300万,只给20万流动性,你们认亏赶紧走 4️⃣ “成功不是我们的责任” 👉 亏钱是你自己的问题 5️⃣ “Paradigm是风投,本来就可能归零” 👉 拿机构背书,现在却说归零合理 6️⃣ “你们不该期待我们像基金经理一样保护你们” 👉 用户亏95%,反而被指责“期望过高” 7️⃣ “威胁团队会被取消资格” 👉 亏钱的人连发声权都没有 8️⃣ “我们没有工资,是为了Web3生态” 👉 经典卖惨 + 道德绑架 9️⃣ “我们始终以社区最大利益为出发点” 👉 一边让你亏钱,一边继续画饼 🔟 “谁会愿意进入一个愤怒到威胁创始人和子女的社区?” 👉 直接反咬,把锅甩给受害者 __________________________________________ 而现实是: ❌ 用户亏损 90%+ ❌ 流动性极低,几乎锁死 ❌ 没有任何补偿方案 ❌他们把用户充的u基本都转进了交易所 然后她告诉你: 👉 这是你的问题 __________________________________________ 我说实话: 这已经不是项目失败, 这是人品问题。 如果你还在幻想他们会救你—— 醒醒。 他们唯一在做的事情就是: 👉 让你接受亏损,并闭嘴。方便他们提桶跑路。



New in M365 Copilot: Council. You can run multiple models on the same prompt at the same time, so you can see where they align and diverge, and understand what each adds.

