Sabitlenmiş Tweet

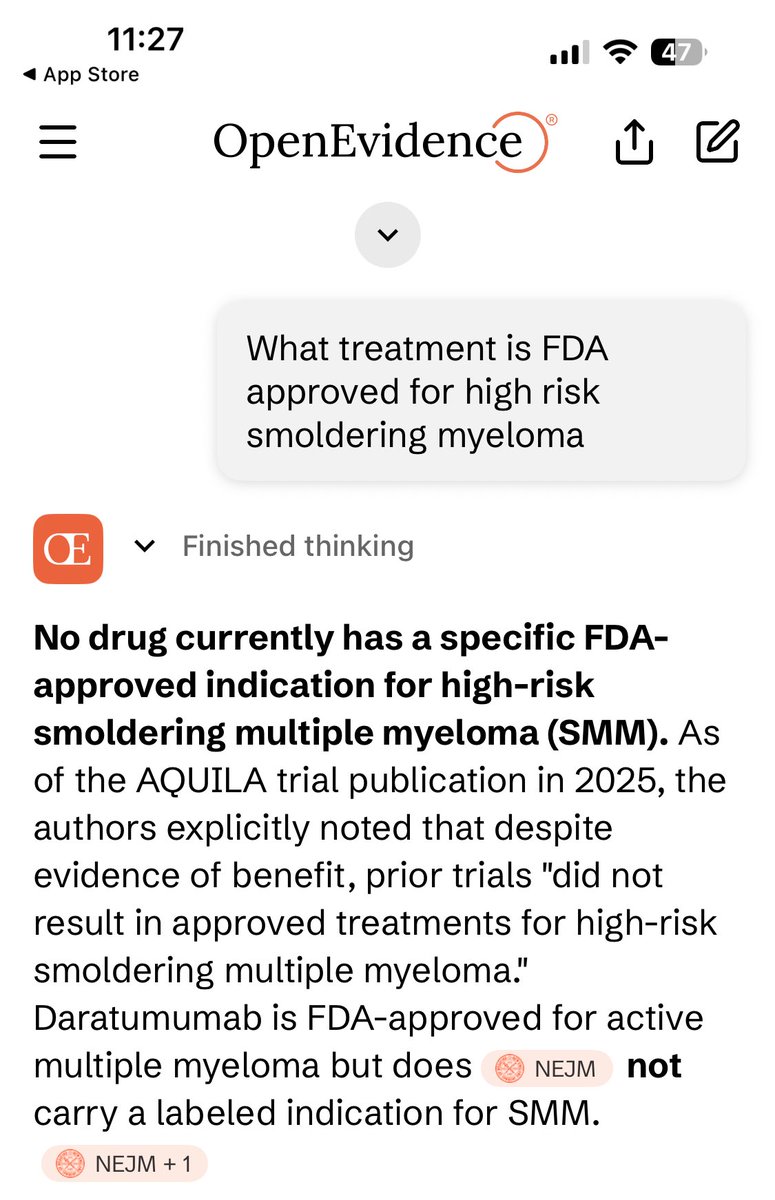
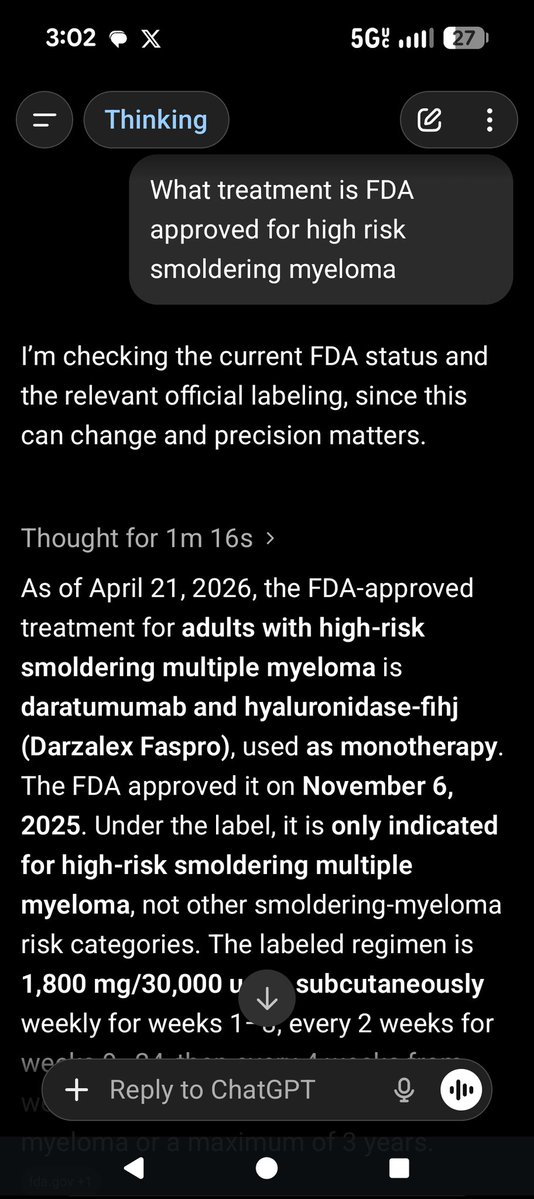
I would like to share the story of how a patient with cancer came up with the idea for a randomized trial, & how listening to him saved a lot of lives.
1/ In 2002, I had just completed a randomized trial with the notorious drug thalidomide for the cancer, multiple myeloma.
English