
❤️薇薇安🐣
10.7K posts

❤️薇薇安🐣
@vvan688
地球是冒险游戏,跟着主人去探险战斗 #Crypto #NFT #加密精神 #阅读分享 #贪财好色 #BDSM
阿纳斯塔西亚 Katılım Kasım 2021
1.2K Takip Edilen17.4K Takipçiler



【完全被主人控制】
并不是说说那么容易
它是需要用一生去修行的课题
在追随主人,服从主人最大的阻碍是自己的欲望
在这个过程中
我看到了自己的软弱,胆小,嫉妒,贪婪,膨胀
再用对主人的忠诚将它们打磨减弱,化解,最终放下
就像王阳明提到的向内求索
也许SM 的入门是欲望
但是向深层探索
它也是另一套理解世界的哲学体系
如果这个世界是虚拟的
那只有与主人的链接是真实的
如何感受到真实的链接
就需要穿过欲望的迷雾
完全臣服于主人的意志
一只狗能够察觉化解最终放下自己的本能欲望
那它本身就拥有了自由灵魂
因为这是他排除内心干扰的选择
一条完全臣服于主人的自由灵魂
而我仍在修行路上。
中文




❤️薇薇安🐣 retweetledi

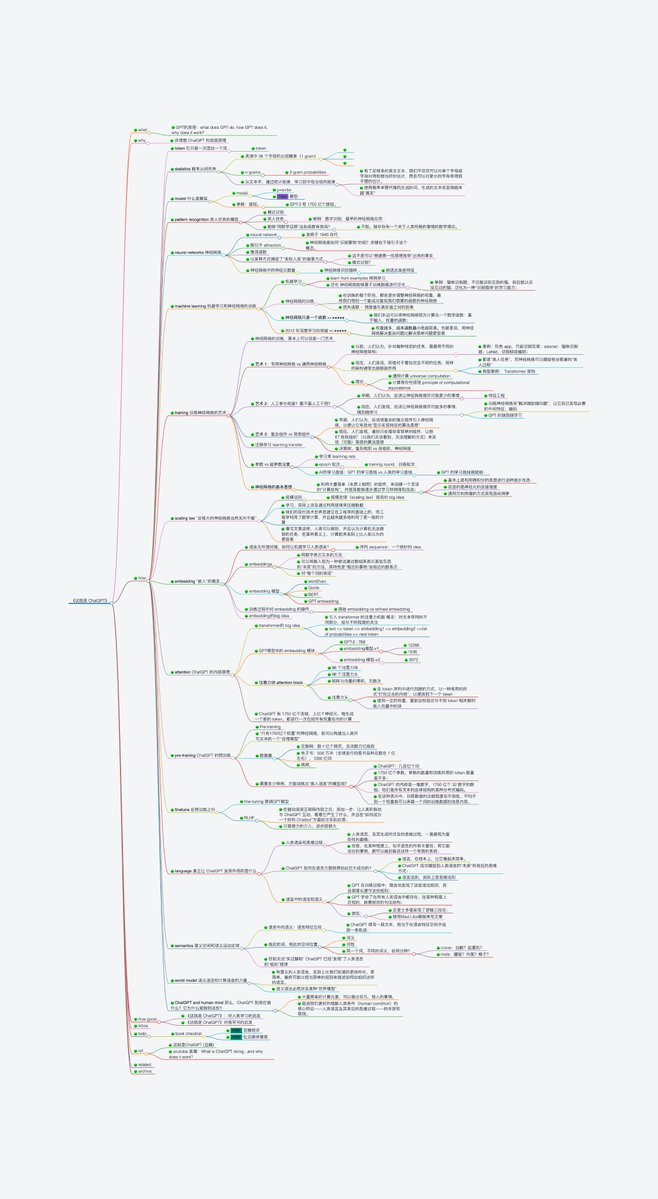
如何使用 ChatGPT 原理学会一切知识?读Wolfram 大神的神书《这就是 ChatGPT》之后的读书笔记
读了李沐大神的《使用随机梯度下降来优化人生》,忍不住拍大腿。加上前面推荐了wolfram 大神的神书《这就是 ChatGPT》,于是觉得有必要写点类似读书笔记或书评的东西。李沐的文章写于ChatGPT 之前,是结合随机梯度下降来讲人生道理的,我这篇准备从ChatGPT 原理出发,聊一聊 GPT对人类学习、构建个人知识体系的启发。以此文致敬两位大神。🫡
李沐的文章微言大义,只用了 1100 字。我对GPT原理的认识有限,所以写了5000字,请大家多多指正。
1 首先要有目标
所有机器学习,一定得有个目标函数。人类的学习也是如此,学习之前,目标先行。
目标函数,也叫成本函数,损失函数。**模型训练的目标就是让损失函数最小化**。人类学习,也是要不断接近自己的学习目标。
2 学习目标要大
GPT模型的训练目标,是用一个巨大的神经网络去模拟互联网上的所有人类语言文本,让损失函数最小化。目标基本达成,**GPT把基本上全部的人类知识压缩进了万亿参数的单一模型**,实现了通用认知任务上的卓越表现。
GPT的学习目标不可谓不大。
人类学习也是如此。目标不能太小,你的学习不是为了通过某次考试,取得某个分数。在我看来,人的学习应当以构建个人知识体系为学习目标。
在你在外,人类知识体系(body of knowledge)是一种客观存在,wikipedia 和书籍等都是对人类知识体系的一种整理和构建的实践,我称之为bok1。在你之内,你的脑子里应该有一个自己的个人知识体系,关于一个或多个学科或领域,我称之为 bok2。
**个人学习的目标,是缩小bok2和bok1之间的差距,形成你自己的更全面更扎实更强大的bok2。**
为什么学习目标要足够大?神经网络训练的实践有一个发现:**参数越多,成本函数最小化越容易。正因为这个规律,用神经网络解决复杂问题比解决简单问题更容易**。所以,AI 现在可以写作编程绘画,但是还没法在餐馆端盘子。
人类学习也是如此。目标足够大,进步才可能足够大,走的才能足够远。
3 从实例中学习
机器靠**样例学习**(learn from examples),从数据中学习,而非通过规则学习(符号AI路线已经破产多年)。机器通过大量的大量的数据来学习到数据中蕴含的模式和规律,就好像从大豆中压榨出其中丰富的油脂。
人类也应当从实例中学习。一本书,一篇文章,一个知识视频,一次演讲录像,一次面对面交谈,都是你学习的来源。从实例中,你学到丰富的、鲜活的、有意义的知识。
4 用高质量信息作为学习数据
**Garbage in,garbage out。这是机器学习的第一性原理**。如果数据本身不富含意义,哪怕训练数据再多,可能训练出来的大模型也无法实现高级的智能,甚至还会从垃圾材料中学到满嘴脏话。GPT的训练数据集是精心挑选的高质量数据,包括 Wikipedia、书籍、论文、代码以及高质量的互联网文本。
所以,人类的学习是不是也要尽可能用高质量信息作为学习数据?**在一头扎进某本垃圾教科书之前,先精心设计你的学习数据集**。对于任何主题,我通过什么小册子轻松上手登堂入室?通过大师的那本科普书获得大图景(big picture)?哪几本教科书才是全国范围内最好的教科书?有那些知识视频让我更直观更好的理解这个主题?有什么工具能让抽象复杂的知识变得具体而清晰?
学习是从数据中体验意义的过程。只有通过高质量的文章、书籍、视频、课程、网站和工具,才能高效提炼出真正的知识。
5 从错误中学习
在GPT模型的预训练过程中,数据依次通过神经网络的各层,最终生成下一个token。token的预测值和实际值之间的差异,这是模型的误差(error)。error = diff(预测值, 实际值)。 GPT就是通过error来学习,把误差用反向传播的方法反馈回去,调整模型参数,降低损失函数。
**预测下一个 token => 得出error => 反向传播 => 梯度下降 => 调整参数 => 预测下一个 token**
GPT 只能通过误差来学习,人也是如此,只能从错误中学习到东西。错误和不足,是反馈的重要来源,也是最好的来源。
然而,人是追求奖励逃避惩罚的动物。**教育的规训让人追求正确,回避错误**。在孩子身上尤其明显,孩子会觉得错误不好,正确才好,一直正确一直好(直到ta迎来必然到来的重大挫折)。
我们可以认识到这个思维陷阱并尽量避免:虽然错误让人痛苦,但错误是唯一的学习来源。只有通过错误,人才能学到点什么东西。
6 唯有学习才能改变自己
GPT模型的训练过程,就是不断调整模型的过程,训练的每一步都在改变模型参数,改变模型本身的连接配置。
人的学习也还如此。每一次费曼,都得到你当前的理解与费曼式理解之间的差距,根据这个差距来调整,查资料,加深理解,再一次费曼。
每一次学习,都在改变你的大脑。不是比喻意义上的改变,而是字面意义上的改变,在生物和物质层面的改变:**短时记忆就是大脑突触之间神经递质增加释放,长时记忆就是基因表达蛋白质合成折叠,形成新的突触连接**。经过充分学习训练的大脑,在结构上不学习的大脑是截然不同的。之间的区别,类似于大脑和脑花之间的区别。
学习改变了大脑,改变了你,字面意义上的改变。
7 把阅读作为学习方法
**GPT的学习,是使用上百万GPU时间做一件事:阅读,阅读整个互联网,阅读几乎所有人类的语言文本**。这个阅读过程被被称为“预训练”,而GPT的阅读,只在做一件事:预测下一个token。而 GPT 的阅读量,是上万亿个 token。
人类的学习,也应该把阅读作为主要方法。scaling law对 GPT 适用,对人类神经网络也同样适用。人大附中早培班要求六年级小学生每年阅读五百万字,约 50 本书。个人认为这是保底要求。**人类学习者,需要首先成为一个贪婪的阅读者:一年五十本书。每天至少阅读一小时。**
没有预训练,GPT 无法学习;没有阅读,人类无法学习。
8 把费曼作为理解方法
GPT的理解,是在万亿维度的意义空间,用注意力机制,在数百层神经网络中,通过上万次的矩阵向量乘法来加工处理文本转化成的数字向量。
**text => token => generic embedding => embedding 2 => embedding x => final refined embedding => list of probabilities => next token**
对于一个token,GPT用它的上下文来不断关联,提取特征,调整这个向量在语言意义空间中的位置,形成富含意义的、更准确的理解。
人类的理解,也是把知识砖块和它的上下文不断建立丰富的、有意义的关联。最好的理解方法就是费曼技巧。**首先费曼知识砖块,然后不断费曼知识砖块之间的关联。通过清晰的概念以及概念之间的关联,人类形成自己的理解。**
把阅读作为学习方法,把费曼作为理解方法,一个概念接着一个概念,一次费曼接着一次费曼。
而且,费曼技巧,就是人类的“预测下一个token”。费曼的实际结果与期待结果之间的差异,就是我们在具体实例学习中得到的 error。针对这个 error,计算梯度,沿着梯度前进一部,你就得到了改进。
9 把迭代作为进步方法
GPT模型是在万亿token的高质量数据上训练出来的,用反向传播来传递误差,用随机梯度下降来减少模型误差。**每一个token的生成,都是神经网络中上亿神经元的一次激活,都是一次包含万亿参数在内计算。**
人类的学习,每一次费曼都是一次对神经网络的调参过程。哪怕是对一个概念的理解和费曼,都不是一蹴而就的。费曼x3,任何一个概念都要至少费曼三遍。在有间隔的多次费曼中,你对一个概念的理解变得越发清晰。
这是一种迭代式的学习闭环。闭环,迭代,这是学习之要义。把迭代作为进步方法。
10 规模法则,大力出奇迹
GPT模型是遵循规模法则(scaling law)的,规模法则是当前AGI之路的关键方法。wolfram说,“足够大的神经网络当然无所不能”。
人类神经网络,是否遵循规模法则?海量知识砖块的积累,构建出越发庞大、多元的个人知识体系,是否能像 GPT 一样带领个体发展出更强大的智能水平?用简单的话说,人类的学习,是否是“大力出奇迹”,凡事都靠积累?
答案很可能是肯定的。
11 身为父母,减少人为干预
曾经,人类设计AI系统走的是规则路线(符号AI)。曾经,机器学习是需要人工建立特征的(有多少人工,才有多少智能),相当于人类工程师教机器学习。现在,深度学习是端到端的,不用人为的特征工程。AI科学家们发现,学会放手,让神经网络做尽可能多的事情,让神经网络自己学习。**学会放手,结果惊人。**
身为人类父母,是不是也应该减少人为的、低水平的干预?大部分父母自己不是学习专家,不懂学习原理,强行扮演教育家是不是反而伤害了孩子的学习?是不是父母们也应该学会放手,不要瞎设计瞎教学?
孩子的大脑就像一个等待训练的 GPT模型,与其自上而下去指导教学,不如每天陪着孩子读半小时书,像一个朋友一样,让孩子快乐地享受伟大的预训练过程(阅读)。每天晚饭后,孩子做作业,大人在旁边读书学习。作业完成后,一起快乐共读,一起谈天说地。学会放手,生活更美好,学习更有效。
12 注意力是最贵的
GPT的T,是transformer架构。而transformer的精髓在于其用算法实现了类似人类的注意力机制,从而让模型在阅读文本时针对文本序列的不同部分给与不同程度的关注。
GPT的学习,是注意力分配的艺术。
人类的学习,也是注意力分配的艺术。当你阅读,你在不同内容上分配不同程度的注意力,关注概念之间的关联。
而且,整个有效学习的前提,是你能在学习这件事上建立并维持你的注意力。注意力的质量,决定学习的质量。
然而,你的注意力,是很多厂商虎视眈眈的猎物,10 亿短视频用户每天刷 150 分钟短视频,人们的注意力模式每天都在被短视频算法疯狂训练,训练到最后,一篇长文章都读不下去,更不要说严肃的书籍读物。
机器在学习,人类在沉迷。**机器通过注意力机制实现了更强大的认知能力。而人类的注意力却愈发稀缺和脆弱。短视频是免费的,但是,注意力却是最贵的。**
13 预训练之外的后训练
在让GPT模型阅读完互联网文本之后,OpenAI的科学家们还做了重要的一步:让人类积极地与GPT互动,并且在“如何称为一个更好的LLM助手”方面给与实际反馈。
是的,GPT模型的训练,除了预训练之外,还有**后训练:微调(finetuning),奖励建模(reward modeling)和RLHF(基于人类反馈的强化学习)。预训练占比95%,是绝对大头;后训练强调少而精,事半功倍。**
人类学习也是如此。除了海量阅读作为预训练,还需要后训练作为补充。
对海量阅读的孩子进行考试元技能的微调,只做了 8 套真题,8 岁儿童就能通过 FCE 考试。而对孩子的三观培养,家庭的家风建设,则类似于 GPT 模型中的奖励建模。为人父母,我们最重要的角色就是正反馈父母,不要学上“老中”的毛病,不过脑子,什么话难听说什么。只要做好正反馈,每个孩子都能培养出强大的澎湃的学习内驱力。
14 语言就是思维本身
人类语言,以及语言生成所涉及的思维过程,一直被视为复杂性的巅峰。而ChatGPT的成功给我们一个启示:在某种程度上,似乎人类语言的所有丰富性,以及人类能用语言谈论的所有事物,都可以被封装进一个有限的系统。
语言,在根本上,似乎比它看起来简单。**ChatGPT 则成功捕捉到了人类语言的“本质”和背后的思维方式**。ChatGPT 在训练过程中,隐含地发现了人类语言的语法规则,并且很擅长遵守这些规则。人类语言中丰富的语义信息,也被 GPT 通过向量空间中无数次的矩阵计算成功提取出来,存储为万亿参数构成的神经网络连接。通过掌握人类语言,GPT 还建立了某种意义上的世界模型。
人类学习也不应轻视语言,把语言视作普通的一个科目,分值有限,在高考中拉不开差距。不宜把口头的语言表达视作非核心技能,不宜把书面语言的写作技能视作非核心技能。每一个终身学习者,都应该足够重视语言,重视演讲作为核心技能,重视写作作为核心技能。
15 学习,快与慢的艺术
机器学习的快慢由一个超参数决定:**学习率 learning rate**,这是模型在梯度下降时的步子长短。步子太大,可能无法实现模型损失函数的最小化。步子太小,梯度下降太慢,效率太低。神经网络的训练中,合适的学习率是只能在实践中摸索出来的,只能来自经验。
人类学习也是如此。步子太大,看起来学的快了,但是理解浅,遗漏多。突击可以让你在考试中蒙混过关,但在实际应用中需要支付更高的代价。步子太小,龟速爬行,学起来会没劲。在快速学习和深度学习之间平衡,是学习的艺术。
而掌握这么艺术的最佳方式,是构建自己的知识树。以知识树为目标的学习,在快与慢之间最容易取得平衡:前期快速搭建框架,快速建立大局观,获得正反馈;然后慢慢微调,一个概念接着一个概念,看起来慢,但实现了更好的快。
16 学习,没有人出生在罗马
有人煽动起跑线焦虑,说什么“有的人出生在罗马”。在财富和权力层面可能对,但在学习这件事上,众生平等,没有人的家住在罗马。哪怕是马斯克的孩子,也得自己亲自预训练自己的神经网络,也得自己逼近学习目标,而且没有捷径。
机器学习也有起点和终点。起点是初始化的随机参数,终点是高维空间中损失函数最小的点。GPT模型的学习,就是在万亿维度的意义空间中找到这个最低点。
LLM们的学习都是后天的,难道ChatGPT比文心一言聪明是因为它出生在罗马?学习就是在万亿维度的意义空间趋近自己的目标函数,所有学习者的起点都是一样的,没有人生在终点,没有人家在罗马。
17 学习,每个人有自己的时区
有人煽动学习焦虑,像把大活人变成竹节虫,让人生布满“节点”: “婴儿英语启蒙要抓住关键节点”,“三年级真的至关重要” ,“大二是最关键的一年”,“人生最关键的节点是35岁”……多少岁毕业,多少岁买房,多少岁结婚,多少岁生子,多少岁财富自由……
这个“社会时钟”妄图规定出一个人生的“标准时间”,规定了人们在不同的阶段要完成相应的 KPI。在“社会时钟”下,很多人在疲于奔命地过一种“打卡人生”。
但是,GPT的学习,是万亿维度的意义空间的旅程。每一条梯度下降的路线,都是逼近目标函数的路线,没有一个固定的、正确的路线。
人的学习也是如此。我们不需要一个“社会时钟”来规定你是迟到了还是来不及了。娃 6 岁了还没学 scratch,是不是晚了?孩子已经初中了,英语词汇量才 500,是不是来不及了?我三十多岁了,才开始学 python,丢不丢人?
每个学习者都有自己的时区,按照自己的节奏,走在终身学习终身成长的道路上。芒格曾经说过,我今年学习了做 PPT,我这 90 多岁的老狗还能学会新技能,你们年轻人还担心什么。
只要你还在学习,还在往前走,就无所谓早晚。每个人都是独一无二的,每个人对自己的路线拥有主导权和解释权。横向比较是愚蠢且没必要的。
18 学习,简洁是更高级的复杂
机器学习的早期,人们认为应该在神经网络中使用各种复杂的独立组件,从而让神经网络“显式地实现特定的算法思想”。GPT之后,人们发现,更好的方式是使用非常简单的组件,让它们“自我组织”,反而能更好地实现算法思想。
**ChatGPT原理的一大启示:最强大的智能,并非通过复杂部件的堆砌,反而来自结构简单的无数计算元素的组合,以及朴实无华的scaling law。**
最复杂的神经网络,由最简单的基本结构组成。人类的学习也是如此。不要迷信复杂的工具和技巧,大道至简,简单最好。
最庞大的知识体系,也不过是由一系列简单的事实性知识、概念、模型组合而成,而学习这些概念的方法本身也是简单而非复杂的,朴实而非深奥的。
---
这些,就是 ChatGPT 教给我关于学习的道理。

中文