Anirudh Vemula retweetledi

Now that I have started using twitter somewhat regularly, let me take a minute to advertise the RL theory lecture notes I have been developing with Sasha Rakhlin: arxiv.org/abs/2312.16730

English
Anirudh Vemula
327 posts

@vvanirudh
Roboticist@Aurora. Primarily work in Robot Planning, Reinforcement Learning, and Optimization. Previously PhD@CMU, CS@IITB and SPG@Apple








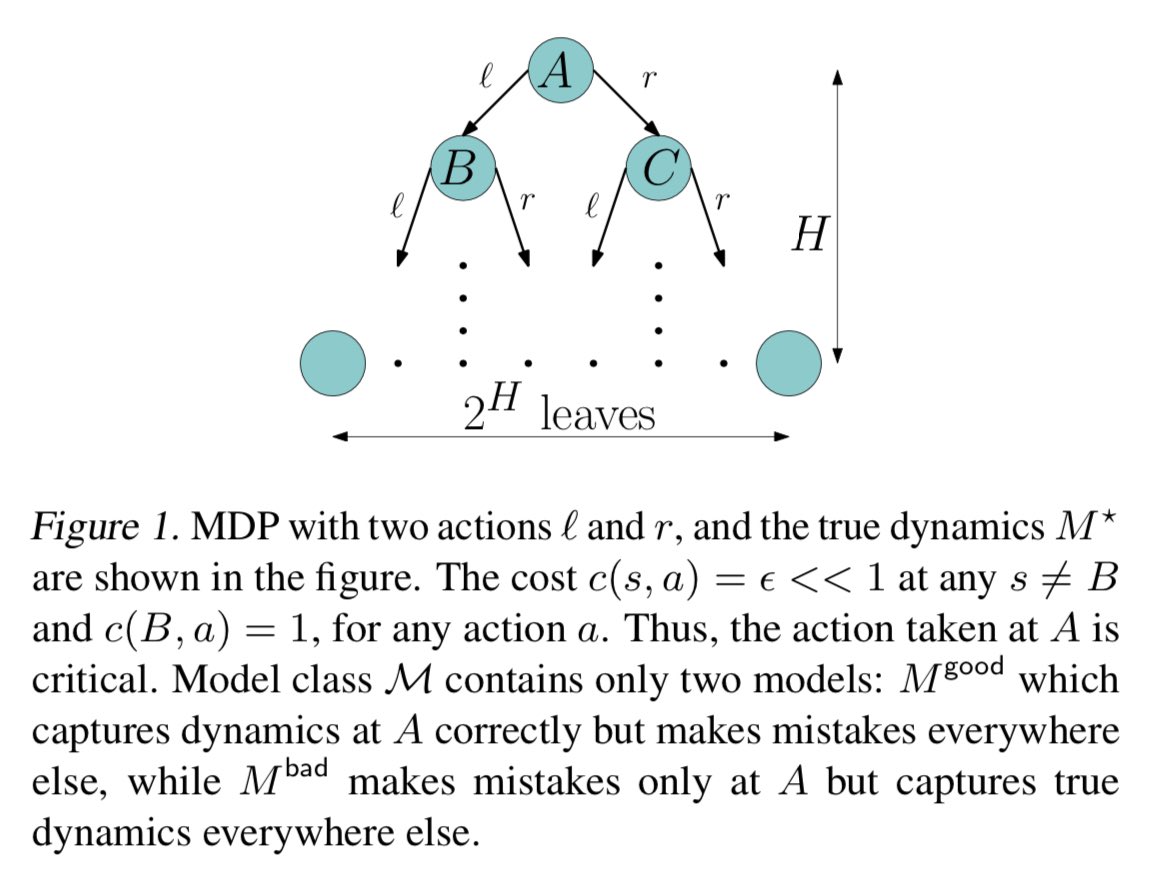
If this has been a long thread, this can be the only tweet to pay attention to the example figure to understand awesomeness of PDAM. MBPO: O(2^H) computation per iteration, and converges to bad model LAMPS-MM: O(H) computation per iteration and converges to good model






Top Indian cities for GRE test takers: 1. Hyderabad: 25K 2. Guntur: 9K 3. Mumbai: 6K 4. Bangalore: 6K 5. Vijayawada: 4K 6. Pune: 4K 7. Chennai: 3K 8. Delhi: 3K 9. Vizag: 3K 10. Khammam: 2K Truly becoming the United States of Andhra

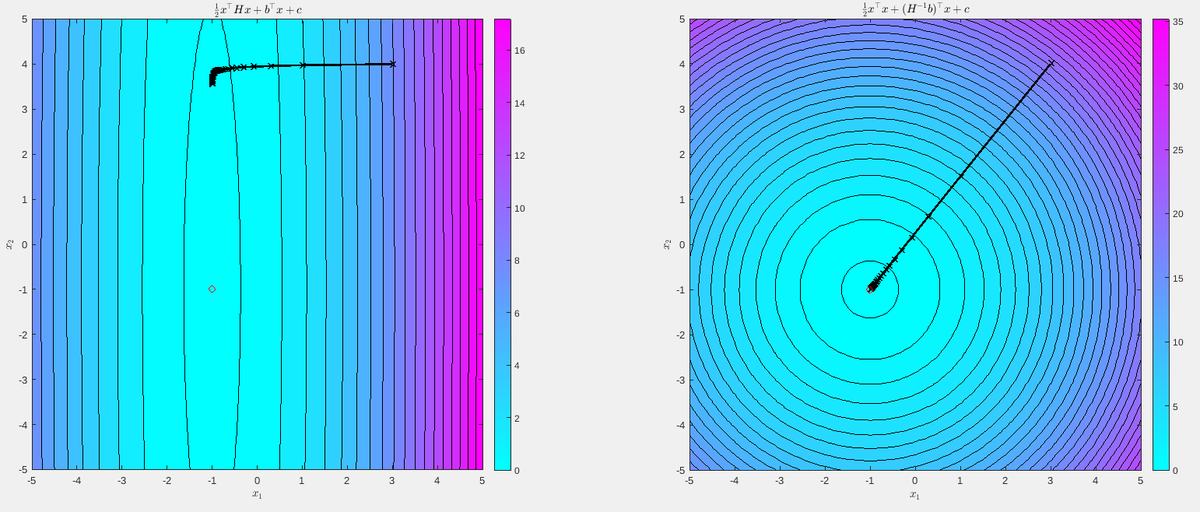

Our paper on a new (lazy) approach to model-based RL that is both computationally efficient and avoids the objective mismatch problem has been accepted for ICML! Excited to present it at Honolulu this summer! arxiv.org/abs/2303.00694