
Jeyong Lee
11 posts

TechCrunch wrote a nice story about our $335M raise at Ricursive, some background and some of our plans!
techcrunch.com/2026/02/16/how…
English
Jeyong Lee retweetledi

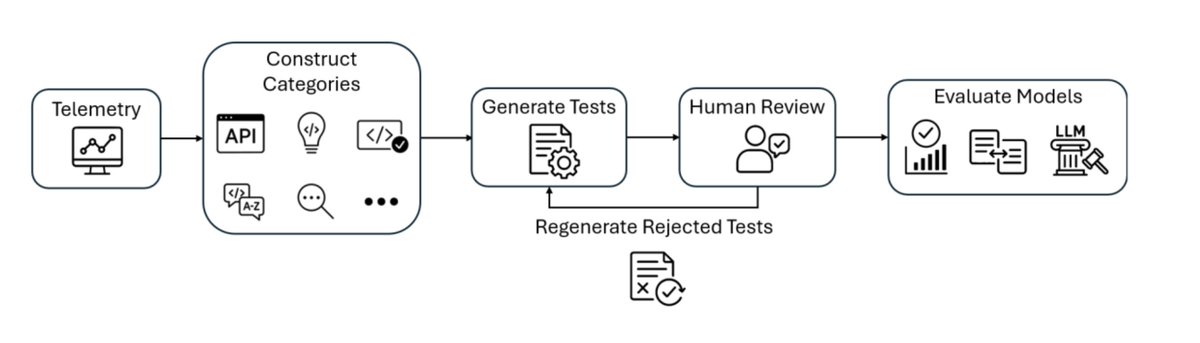
What if your benchmark scores are lying to you?
Today, I'm excited to share @Microsoft's DevBench, the first telemetry-grounded code generation benchmark, covering six languages, and the first to combine synthetic generation with manual expert review for contamination resistance.
📄 arxiv.org/abs/2601.11895
💻 github.com/microsoft/devb…
1/7
English
Jeyong Lee retweetledi

Remember that Al HIlal vs Man City upset?! Come join The Beautiful Game to visualize any action on your favorite teams / players with our new zonal representation 🔥⚽️
Join us: thebeautifulgame.global
🧵1/2
English
Jeyong Lee retweetledi

For the confused, it's actually super easy:
- GPT 4.5 is the new Claude 3.6 (aka 3.5)
- Claude 3.7 is the new o3-mini-high
- Claude Code is the new Cursor
- Grok is the new Perplexity
- o1 pro is the 'smartest', except for o3, which backs Deep Research
Obviously. Keep up.
English
Jeyong Lee retweetledi

🚨 Multi-agent systems are no longer safe from prompt injection!
In our paper, we introduce Prompt Infection—an infectious prompt injection attack that spreads like a virus across LLM agents, turning your multi-agent system into a network of compromised agents.
TL;DR:
1. One malicious email, PDF, or webpage can steal your data and cost you thousands of dollars.
2. Bigger models ≠ Better security. More powerful LLMs, like GPT-4o, can actually be more vulnerable.
3. Imagine LLM town: a scenario where agents infect each other, leading to significant system failures.
4. We’ve explored solutions to mitigate this threat.
Paper: arxiv.org/abs/2410.07283
More on threads below 👇

English
Jeyong Lee retweetledi

I've made that point before:
- LLM: 1E13 tokens x 0.75 word/token x 2 bytes/token = 1E13 bytes.
- 4 year old child: 16k wake hours x 3600 s/hour x 1E6 optical nerve fibers x 2 eyes x 10 bytes/s = 1E15 bytes.
In 4 years, a child has seen 50 times more data than the biggest LLMs.
1E13 tokens is pretty much all the quality text publicly available on the Internet. It would take 170k years for a human to read (8 h/day, 250 word/minute).
Text is simply too low bandwidth and too scarce a modality to learn how the world works.
Video is more redundant, but redundancy is precisely what you need for Self-Supervised Learning to work well.
Incidentally, 16k hours of video is about 30 minutes of YouTube uploads.
Tom Osman 🐦⬛@tomosman
"A 4-year-old child has seen 50x more information than the biggest LLMs that we have." - @ylecun 20mb per second through the optical nerve for 16k wake hours 🤯 LLMs may have consumed all available text, but when it comes to other sensory inputs...they haven't even started.
English
Jeyong Lee retweetledi
Is inference compute a new dimension for scaling LLMs?
In our latest paper, we explore scaling inference compute by increasing the number of samples per input. Across several models and tasks, we observe that coverage – the fraction of problems solved by at least one attempt – grows almost log-linearly with the number of samples across four orders of magnitude!
Led by @jordanjuravsky, @brad19brown & @ryansehrlich, in collaboration with @ronnieclark__, @quocleix, and @HazyResearch!

English
Jeyong Lee retweetledi
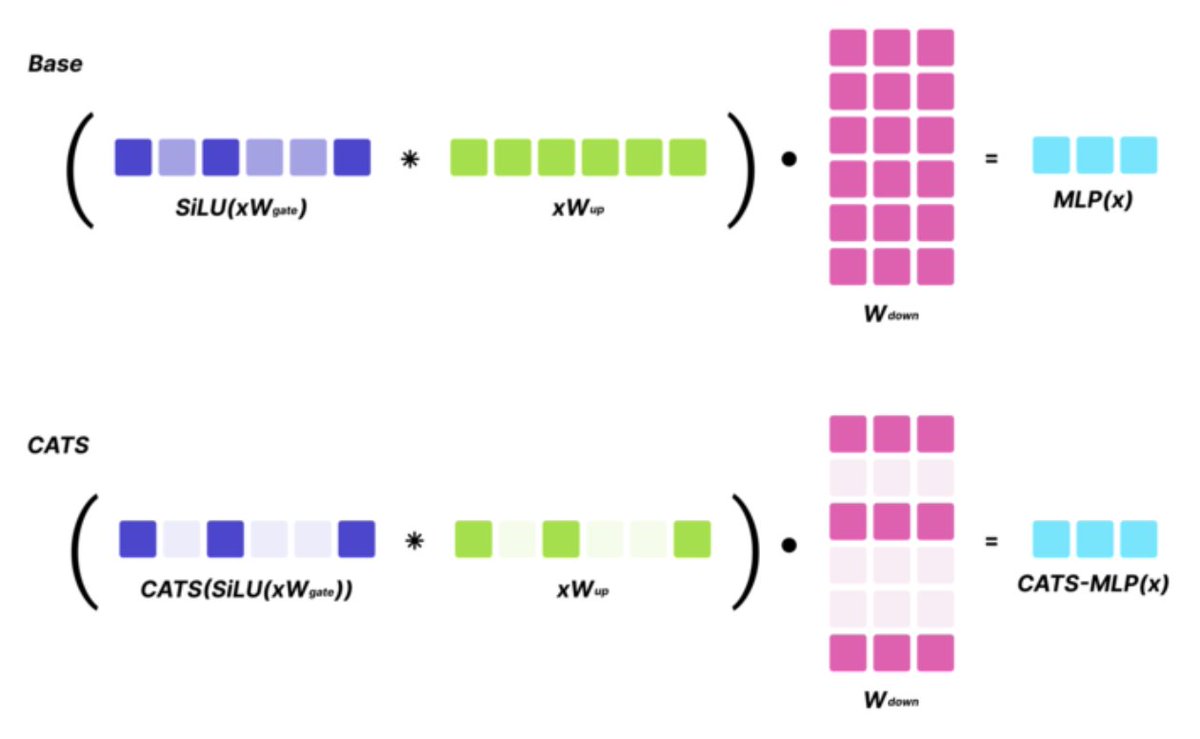
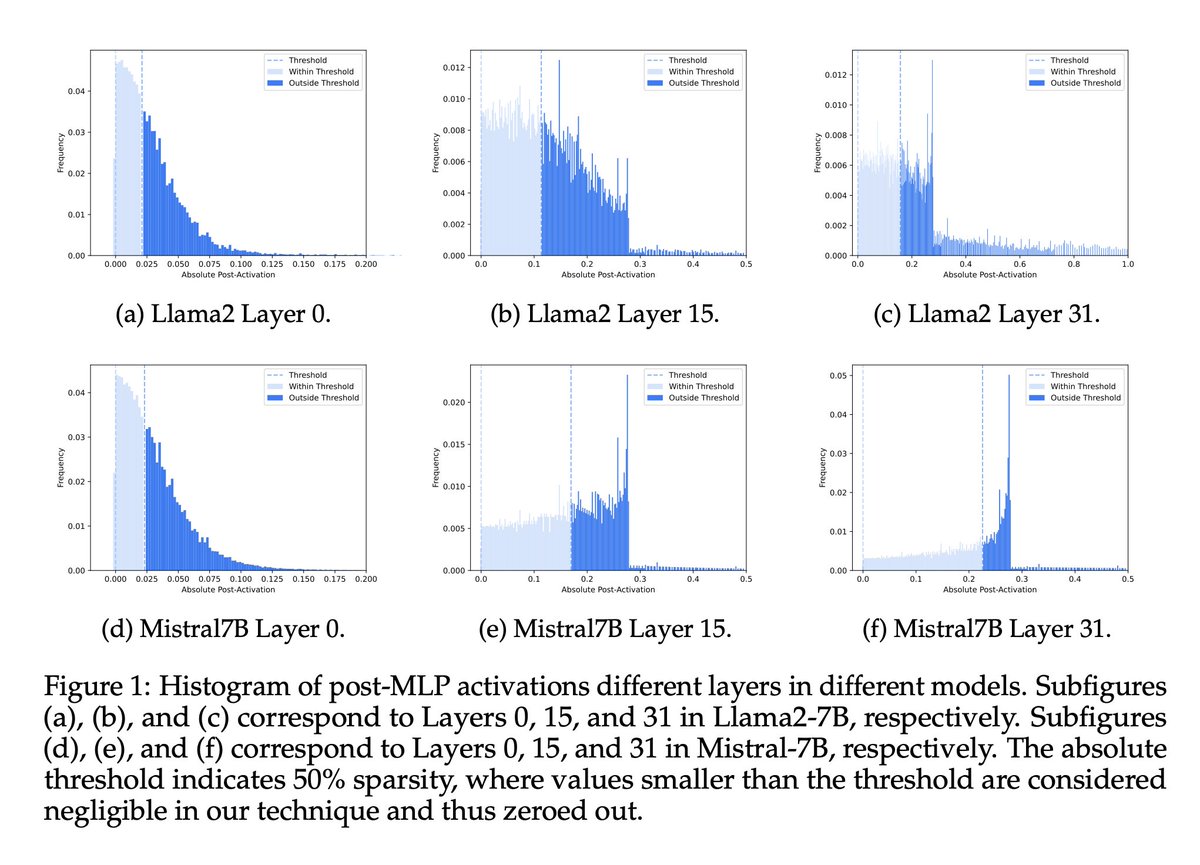
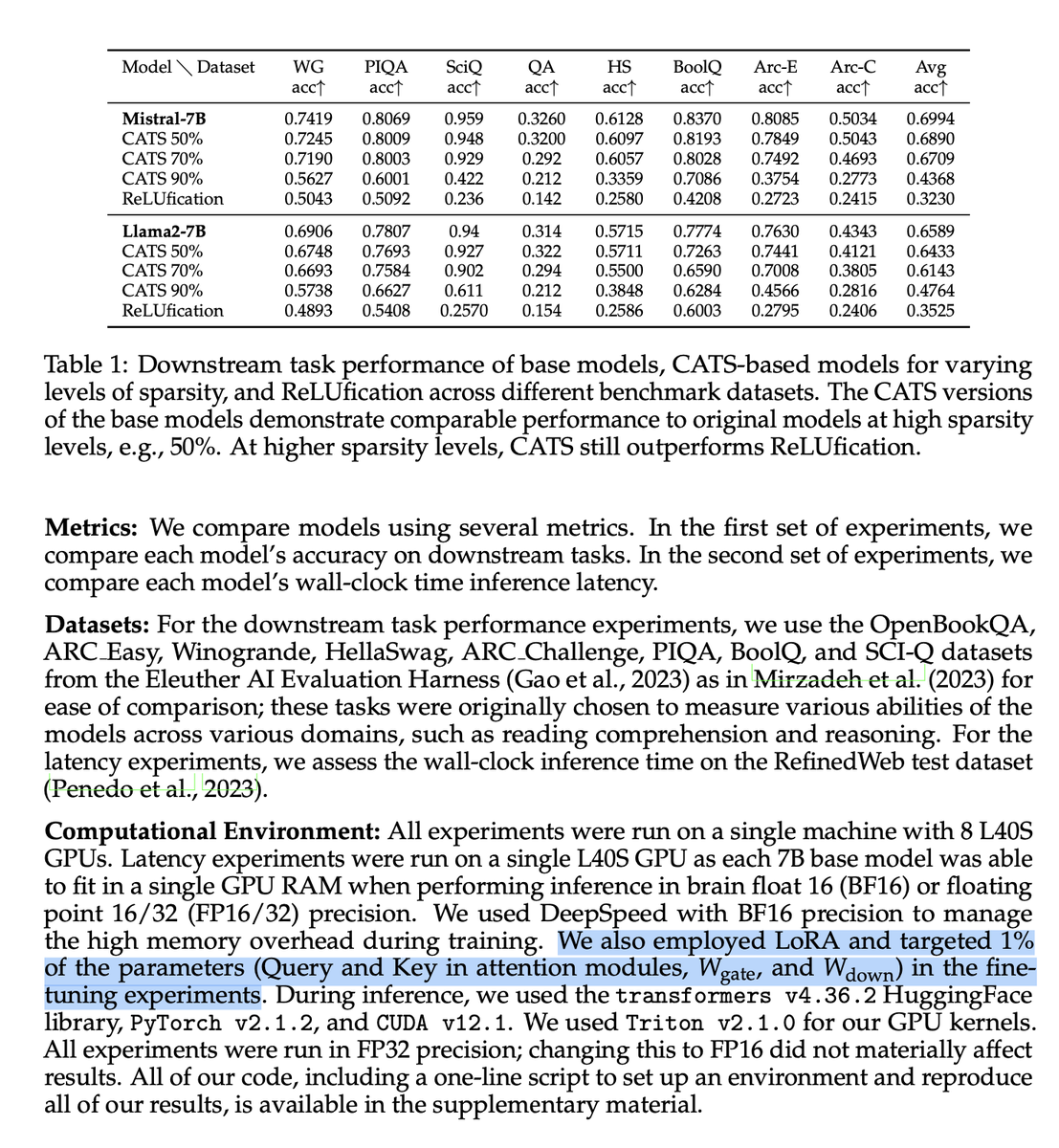
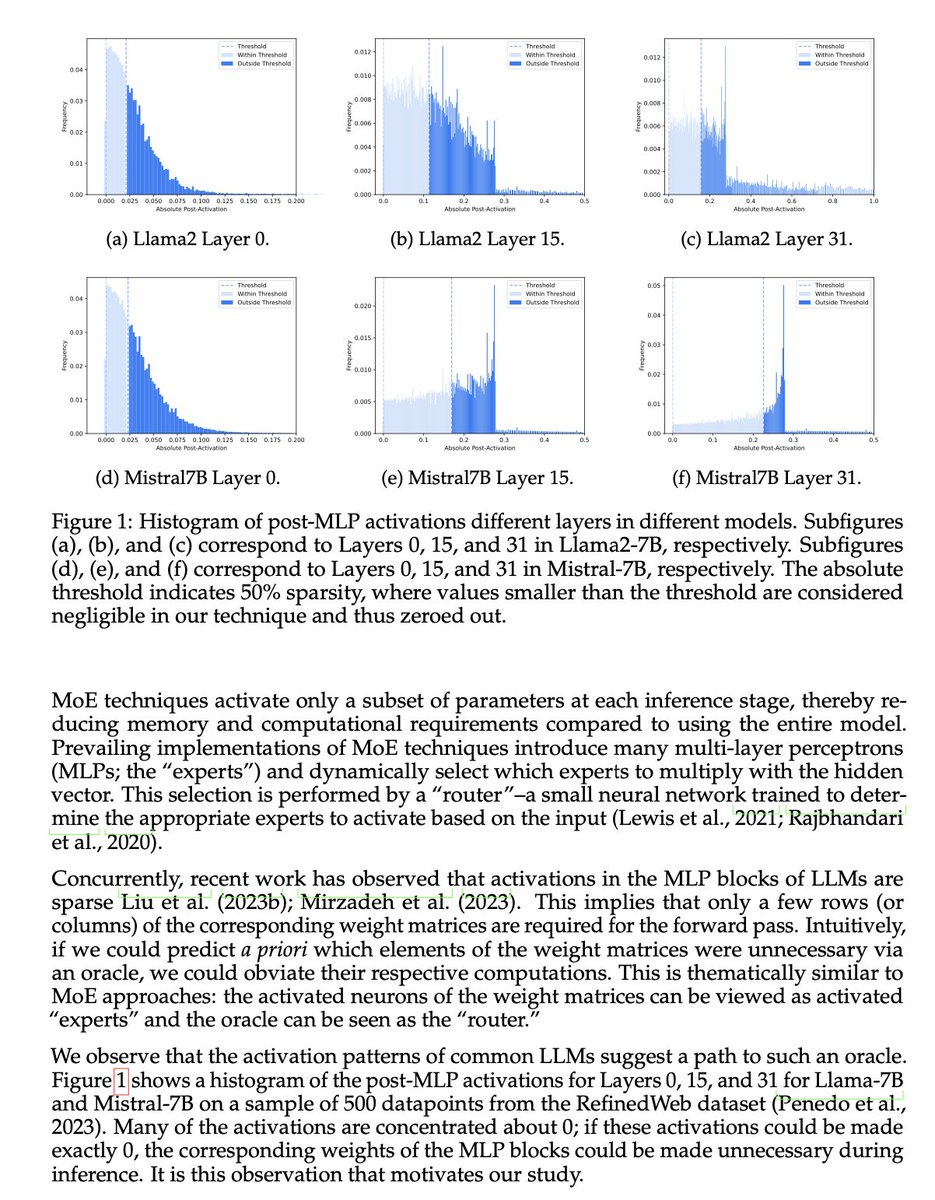
SoTA LLMs typically exhibit 99%+ non-zero activations, but it turns out that they are still intrinsically quite sparse!
We introduce CATS, a simple post-training technique that achieves 50% activation sparsity for MLP layers with almost no drop in downstream evals, while requiring little to no finetuning! With our custom GPU kernels, we leverage this sparsity to achieve 15% improvement in end-to-end generation latency for both Mistral-7B and Llama-7B models.
Work led by @vxbrandon00 and @luke_lee_ai in collaboration with @zhang677 and @mo_tiwari!
Check out our paper: arxiv.org/abs/2404.08763
English
@teortaxesTex The point on the l3-8b’s capacity is intriguing—we're keen on further exploring sparsity thresholds beyond 70%. Also, we’re planning a wider promotion alongside the publication of our codes, which should provide even more room for discussion and collaboration. Stay tuned!
English

Like I've referenced the paper a few times, but didn't notice the promotion from authors, so it didn't occur for me to give them a shout-out. Shame.
It's curious, beyond utility. Wonder if l3-8b is more "filled up".
Somebody use more compute to recheck limits of >70% sparsity pls

English
> @vxbrandon00
> 6 followers
> follows you
> Jeyong Lee, author "CATS: Contextually-Aware Thresholding for Sparsity in LLMs" (reducing FLOPs & latency for non-ReLU models w/no degradation)
Didn't even check if he's here. Some people just don't care for clout, man
Worth a follow



George@georgejrjrjr
@teortaxesTex @teknium @gwern cc: @vxbrandon00, @teortaxestex introduced me to your work here.
English
@teortaxesTex Appreciate the shout-out for our CATS paper! Yes, I’m here and love the engagement with our research.
English

English

I'm happy to return to a non-moe paradigm personally lol
Owen Colegrove@ocolegro
Looks like Llama3 is not a MoE - bearish
English