Alex
865 posts


Alex
@wadeAlexC
Oolong maximalist. Bureaucracy minimalist. | Prev: breaking things @eigenlayer, @ConsenSysAudits, @EtherealVC
[REDACTED] Katılım Temmuz 2018
311 Takip Edilen1.9K Takipçiler


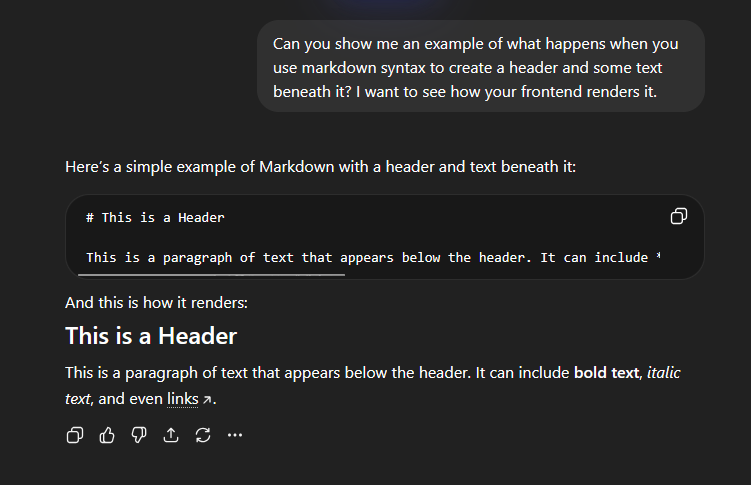
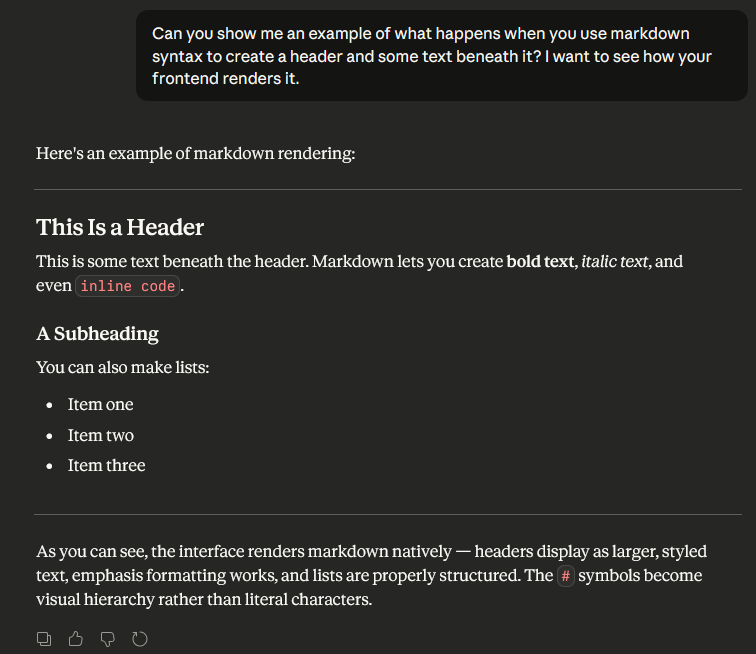
ChatGPT's interface is hot garbage.
There's very little contrast between different UI elements - it's black, on dark grey, on charcoal. It's peak modern design - everything's round and bubbly in a way that gives icons and elements a samey vibe.
I really like Claude's interface.
It's warmer overall, but they darken the users' message background so it pops out. They use a serif'ed font for Claude that makes it really easy to read (to me). They also use more straight lines in their icons/elements that create clearer borders to divide up the screen.
English

I have uploaded a blood test result to both @ChatGPTapp and @claudeai.
ChatGPT really needs to improve drastically the way it "render" the output. Claude's UI/UX is orders of magnitude better than ChatGPT.
The way ChatGPT writes back to you is always so disorganized and visually confusing, it's like it's puking a wall of text back to me with random bullet points and emojis.
English
@0xClandestine that's wild. i wonder if it'd be faster if it also used RAM
English

@wadeAlexC Funny enough it doesn’t even use much of my 64gb ram, few gbs. Flash-moe aggressively streams the entire model from ssd.
English
Running Qwen3.5 397B on my 64GB M4 Max at 5 tok/s (4-bit) using flash-moe. Local frontier intelligence is almost here.
Dan Woods@danveloper
English
@Duffaluffaguss Not sure what you're asking. I haven't personally gotten into Openclaw, but you could for sure hook up a local model to it 😊
English

I ditched cloud LLMs for self-hosted last year.
24/7 availability. My phone. My laptop. My GPU.
It's faster than ChatGPT. Almost as smart.
It's not being used by the DoD to conduct warrantless surveillance.
No data leaves my server. I own everything. When things break, I can fix them myself.
I can ask anything I want and get an answer back 10-20x faster than I can read.
It costs pennies to run. Why isn't everyone doing this?
English
A good way to test would be to try out some of the target models you'll want to run via OpenRouter.
With 256-512 GB, you'll probably want to look at these:
- Qwen3.5-397B-A17B
- Minimax M2.5
- GLM 5
(you'll need quantized versions of these, and im not personally familiar with their game; I stick to models < 100B params)
English
@Duffaluffaguss @LLMJunky I'm not 100% sure what your usecase is. You said "self-maintaining business with ongoing research" -- sounds like you don't care if your llm is slow, it just needs to be smart?
Mac Studios are, what, 256-512 GB unified memory? Yeah, that'll let you run some really great models.
English
@Duffaluffaguss Local models are capable of that, but you need an interface that feels intuitive to use and hides a lot of that complexity from the user.
Ex: Qwen3.5 can't output images. If I wanted to add that feature, I would need my interface to do some fancy routing to image-gen models.
English
@Duffaluffaguss For generic chat, 95% of the time you won't notice a difference between local and frontier. Frontier is only decent because their interface has a lot of features.
For example, you go to chatgpt, and it can ingest and output images, do web search, write/execute code.
English
@TheCesarCross Qwen3.5-35B-A3B is my go to. Absolute beast. I posted more details about my setup in the other replies :)
English

Models: Qwen3.5-35B-A3B and Qwen3.5-27B
Unsloth Q4 quants for both. Both easily fit <24 GB VRAM at 100k context.
Device: I have an NVIDIA RTX 5090 and keep everything on-GPU. However, with these models/quants, you can accomplish the same even with a 4090.
I haven't tried any Mac products. I hear good things, but my understanding is you're getting slower inference (but maybe you can run larger models).
Whether you want an NVIDIA setup or a Mac setup probably comes down to your usecase.
- If you mainly want to support a "chat app" or "personal assistant", you want the nicest GPU you can get, because you're gonna want the speed.
- If you want like... home assistant/automation/coding agents, maybe opt for something with better capacity for larger models? Mac Studio, DGX Spark, things like that. I can't advise as much here because I went the GPU route.
English
@wadeAlexC What models and on what device? I'm trying to figure out what I need and how well it will perform and I feel like everything I read suggests something different. Mac studio with 256 ram, custom Nvidia setup. Which models. Ty ser
English
@auryn_macmillan Qwen3.5-35B-A3B and Qwen3.5-27B
Unsloth Q4 quants for both. Both easily fit <24 GB VRAM at 100k context.
English

@0xClandestine Qwen3.5-35B-A3B is the goat for both speed and intelligence. Handles most of my daily usage.
English
@wadeAlexC What models are you enjoying the most? I like the Qwen 3.5 family.
English
Alex retweetledi

He was found guilty on the charge that directly contradicts FinCEN's guidance. Unbelievable.
English
Alex retweetledi

OK - now in US v. Roman Storm, closing arguments matthewrussellleeicp.substack.com/p/extra-in-rom… Unsealing bid in storage.courtlistener.com/recap/gov.usco… Inner City Press put out book on the case, Crypto Tornado amazon.com/dp/B0FHXTCNCR & will live tweet, thread below

English

Vibe or get left behind by our robot overlords. 😘🤖🔥
tintinweb.github.io/portfolio/
#nocode #agenticAI #vibecoding
English