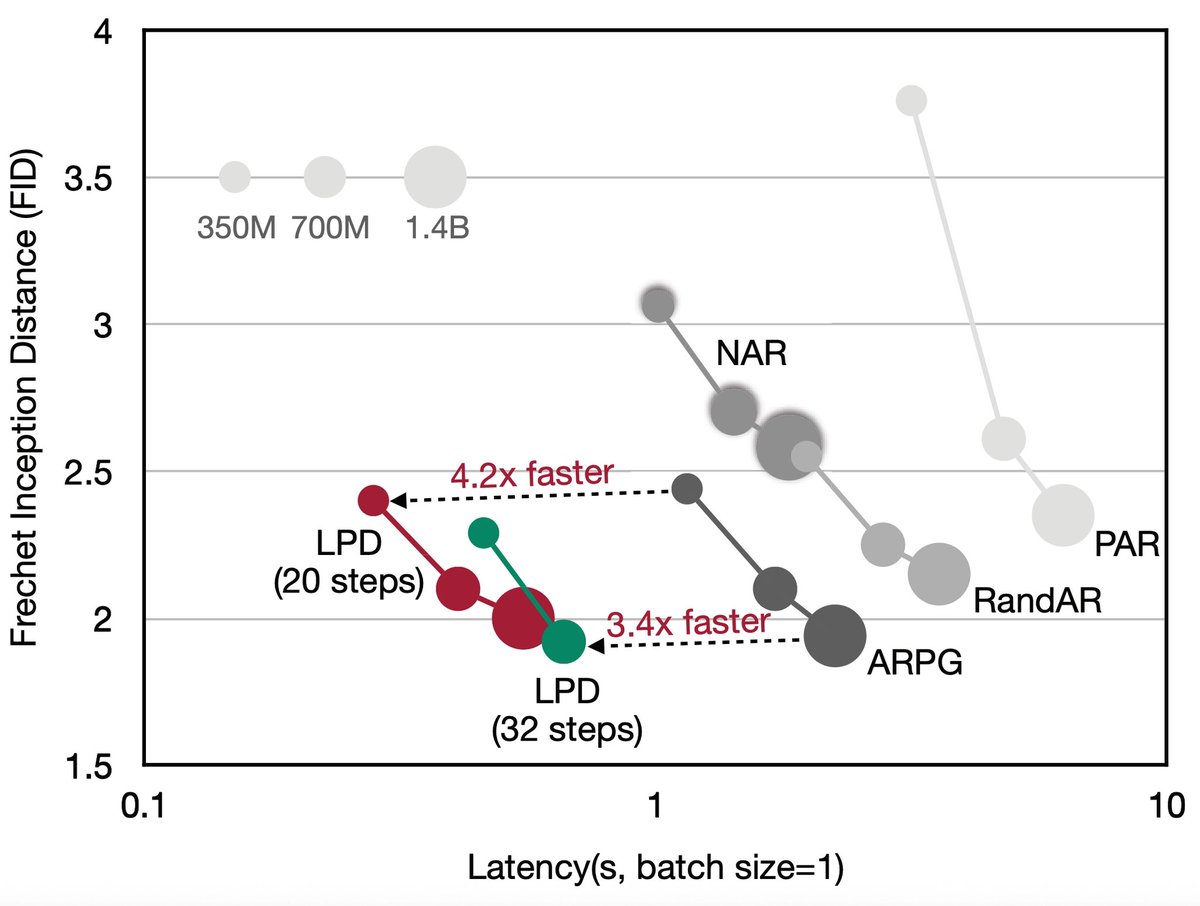
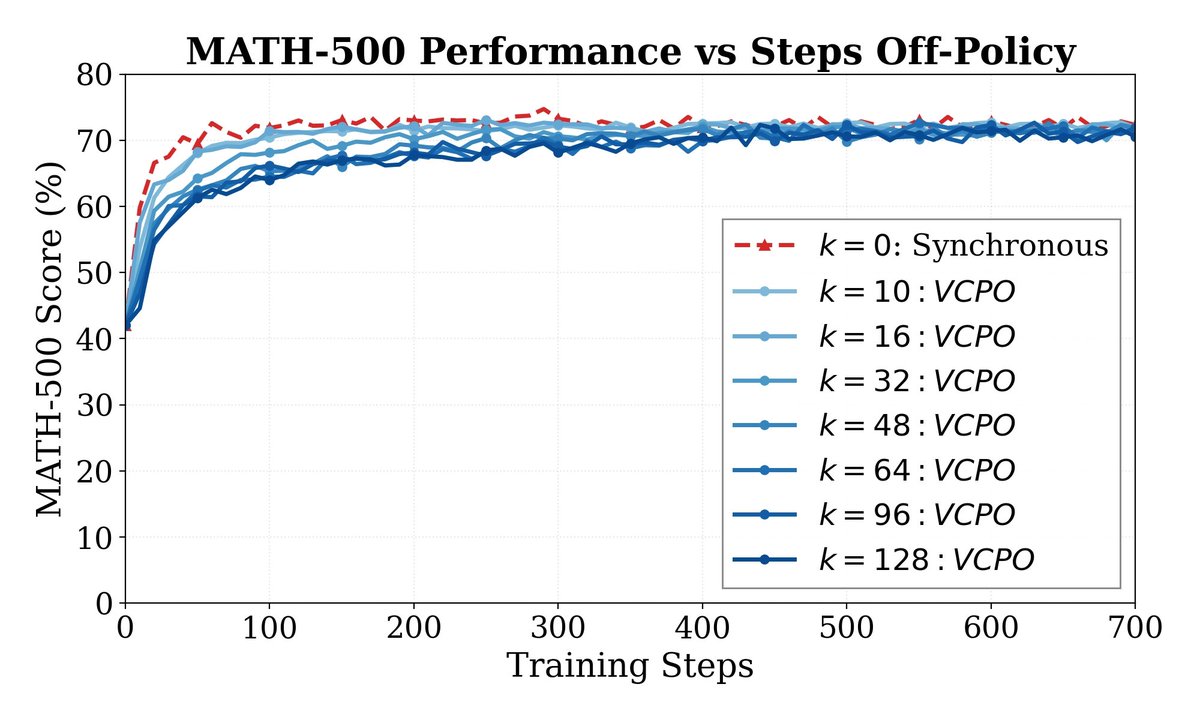
Sabitlenmiş Tweet

We introduce Variance Controlled Policy Optimization (VCPO), a method for explicit variance-targeted controls for policy-gradient objectives in off-policy RL — enabling stable, scalable Async RL training.
✨ Seamlessly integrates into common policy-gradient methods like REINFORCE/RLOO/GRPO 🚀 2.5x faster Async RL training while matching Synchronous RL performance 🧠 Robust training stability under high off-policy settings (at least 128 steps off-policy)
📄Paper: arxiv.org/abs/2602.17616
🔗Code: github.com/mit-han-lab/vc…
🧵👇

English