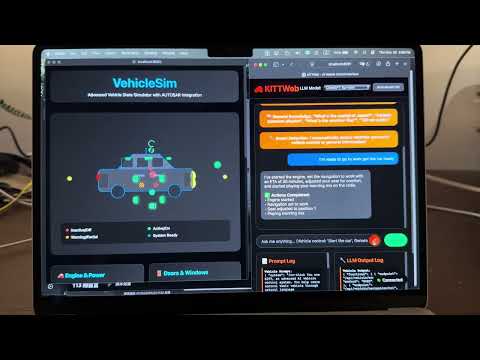
I had the same thought so I've been playing with it in nanochat. E.g. here's 8 agents (4 claude, 4 codex), with 1 GPU each running nanochat experiments (trying to delete logit softcap without regression). The TLDR is that it doesn't work and it's a mess... but it's still very pretty to look at :)
I tried a few setups: 8 independent solo researchers, 1 chief scientist giving work to 8 junior researchers, etc. Each research program is a git branch, each scientist forks it into a feature branch, git worktrees for isolation, simple files for comms, skip Docker/VMs for simplicity atm (I find that instructions are enough to prevent interference). Research org runs in tmux window grids of interactive sessions (like Teams) so that it's pretty to look at, see their individual work, and "take over" if needed, i.e. no -p.
But ok the reason it doesn't work so far is that the agents' ideas are just pretty bad out of the box, even at highest intelligence. They don't think carefully though experiment design, they run a bit non-sensical variations, they don't create strong baselines and ablate things properly, they don't carefully control for runtime or flops. (just as an example, an agent yesterday "discovered" that increasing the hidden size of the network improves the validation loss, which is a totally spurious result given that a bigger network will have a lower validation loss in the infinite data regime, but then it also trains for a lot longer, it's not clear why I had to come in to point that out). They are very good at implementing any given well-scoped and described idea but they don't creatively generate them.
But the goal is that you are now programming an organization (e.g. a "research org") and its individual agents, so the "source code" is the collection of prompts, skills, tools, etc. and processes that make it up. E.g. a daily standup in the morning is now part of the "org code". And optimizing nanochat pretraining is just one of the many tasks (almost like an eval). Then - given an arbitrary task, how quickly does your research org generate progress on it?
I think congrats again to OpenAI for cooking with GPT-5 Pro. This is the third time I've struggled on something complex/gnarly for an hour on and off with CC, then 5 Pro goes off for 10 minutes and comes back with code that works out of the box. I had CC read the 5 Pro version and it wrote up 2 paragraphs admiring it (very wholesome). If you're not giving it your hardest problems you're probably missing out.
So vibe coding turned into Context Engineering, which makes much more sense. The LLMs's limitations are the pre-training, context window and all the external tools, so what you will be responsible for, highly depends on what your provide and arrange in context window? @karpathy
@karpathy For the 2 point, in human conversation, we often build up the whole conversation context from scratch and then build further context based on the previous frame of conversation, not everything from scratch, so is the graphical context. The problem is today’s LLMs can’t do that. ?
"Chatting" with LLM feels like using an 80s computer terminal. The GUI hasn't been invented, yet but imo some properties of it can start to be predicted.
1 it will be visual (like GUIs of the past) because vision (pictures, charts, animations, not so much reading) is the 10-lane highway into brain. It's the highest input information bandwidth and ~1/3 of brain compute is dedicated to it.
2 it will be generative an input-conditional, i.e. the GUI is generated on-demand, specifically for your prompt, and everything is present and reconfigured with the immediate purpose in mind.
3 a little bit more of an open question - the degree of procedural. On one end of the axis you can imagine one big diffusion model dreaming up the entire output canvas. On the other, a page filled with (procedural) React components or so (think: images, charts, animations, diagrams, ...). I'd guess a mix, with the latter as the primary skeleton.
But I'm placing my bets now that some fluid, magical, ephemeral, interactive 2D canvas (GUI) written from scratch and just for you is the limit as capability goes to \infty. And I think it has already slowly started (e.g. think: code blocks / highlighting, latex blocks, markdown e.g. bold, italic, lists, tables, even emoji, and maybe more ambitiously the Artifacts tab, with Mermaid charts or fuller apps), though it's all kind of very early and primitive.
Shoutout to Iron Man in particular (and to some extent Start Trek / Minority Report) as popular science AI/UI portrayals barking up this tree.
Is #MCP really needed?
Do we need to invent another kind of STOP sign or Traffic Lights just for Autopilot?
Is MCP a temporary thing because current #LLMs are not smart enough?
AI Agents 101: 𝗔𝗜 𝗔𝗴𝗲𝗻𝘁 𝗠𝗲𝗺𝗼𝗿𝘆.
In general, the memory for an agent is something that we provide via context in the prompt passed to LLM that helps the agent to better plan and react given past interactions or data not immediately available.
It is useful to group the memory into four types:
𝟭. Episodic - This type of memory contains past interactions and actions performed by the agent. After an action is taken, the application controlling the agent would store the action in some kind of persistent storage so that it can be retrieved later if needed. A good example would be using a vector Database to store semantic meaning of the interactions.
𝟮. Semantic - Any external information that is available to the agent and any knowledge the agent should have about itself. You can think of this as a context similar to one used in RAG applications. It can be internal knowledge only available to the agent or a grounding context to isolate part of the internet scale data for more accurate answers.
𝟯. Procedural - This is systemic information like the structure of the System Prompt, available tools, guardrails etc. It will usually be stored in Git, Prompt and Tool Registries.
𝟰. Occasionally, the agent application would pull information from long-term memory and store it locally if it is needed for the task at hand.
𝟱. All of the information pulled together from the long-term or stored in local memory is called short-term or working memory. Compiling all of it into a prompt will produce the prompt to be passed to the LLM and it will provide further actions to be taken by the system.
We usually label 1. - 3. as Long-Term memory and 5. as Short-Term memory.
A visual explanation of potential implementation details 👇
And that is it! The rest is all about how you architect the topology of your Agentic Systems.
What do you think about memory in AI Agents?
#LLM#AI#MachineLearning
@smjain@Aurimas_Gr ultimately it will be need to be trained into the model itself, and before that, it will be in RAG, maybe memory first being migrated to local model and then into server model? or bringing the history into the LLM directly, question is how? fine-tuning?
Why do we want #AGI (being sentient or conscious) to compete with the current human population? What we want is highly specialized & safe artificial super intelligence (#ASI) as tools for human population. Agree?
@DrJimFan This is the ChatGPT moment to Ray Tracing ... Congratulations! overtime, I am expecting the true impact to replace Ray Tracing the ground true output...
Y'all expecting RTX 5090, cool specs and stuff. But do you fully internalize what Jensen said about graphics? That the new card uses neural nets to generate 90+% of the pixels for your games? Traditional ray-tracing algorithms only render ~10%, kind of a "rough sketch", and then a generative model fills in the rest of fine details. In one forward pass. In real time.
AI is the new graphics, ladies and gentlemen.