Kevin Huang (Wenqi) retweetledi
Kevin Huang (Wenqi)
782 posts


Kevin Huang (Wenqi)
@winkey_h
Founding Research @datacurve DeepSWE ∗ prev @openai, @nvidia, @tesla, @uwaterloo cs 26
Katılım Kasım 2016
1.8K Takip Edilen423 Takipçiler

Opus 4.8 is a clear efficiency step up over 4.7 on DeepSWE, same-or-better task success with fewer steps and fewer input tokens per task.
Worth noting DeepSWE measures backend/implementation, not frontend.
Hoping to release a deep dive soon.
Datacurve@datacurve
Opus 4.8 is now on DeepSWE. On the default high thinking effort, it scores 6% higher than Opus 4.7 xhigh, while also lowering average cost per task.
English
@thdxr This exactly.
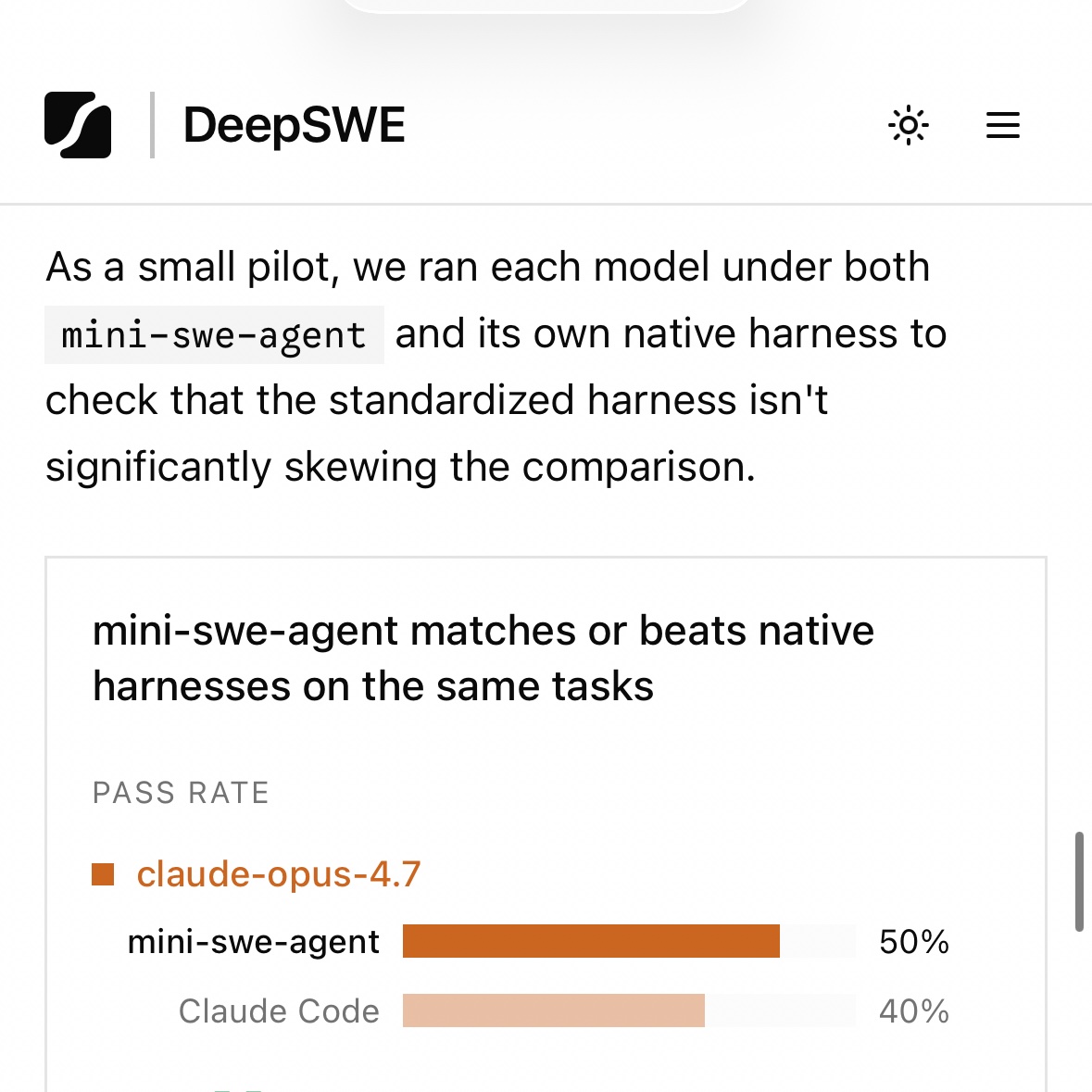
The takeaway is that mini-swe-agent system prompt prescribes a workflow better optimized for one shot problem solving.
And that using mini-swe-agent is not sandbagging models for eval sake.
English

imagine a benchmark of two editors
one opens a file 10x faster! wow it must be better. but oh wait they just disabled syntax highlighting
real products have to do things that make it worse on benchmarks but better in practice
Ben (no treats)@andersonbcdefg
official confirmation that the claude code harness has become slop btw
English
@latent_node @andersonbcdefg This is true!
Claude Code/Codex CLI system prompt is just not optimized for eval-style 1-shot problem solving.
English

I think the issue is official harnesses are not meant to be run without human in loop. A claude code comparison should have been with claude -p not sure if they did that, because if you give it just the same tools available to mini-swe-agent it does tend to do better from experience.
English

official confirmation that the claude code harness has become slop btw
Serena Ge (Datacurve)@serenaa_ge
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
English
Kevin Huang (Wenqi) retweetledi

It's truly amazing to see how the general sentiment has shifted in favor of Codex.
I'm reading so many posts saying that Codex is really good now with GPT-5.5, and that Claude Code is regularly preferred.
(I've become a huge Codex fan myself).
At the same time, the new DeepSWE benchmark shows that GPT-5.5 is now ranked number one in this measurement as well.

Serena Ge (Datacurve)@serenaa_ge
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
English
Kevin Huang (Wenqi) retweetledi

Not surprising for people using these models
Serena Ge (Datacurve)@serenaa_ge
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
English
Kevin Huang (Wenqi) retweetledi

Honestly, looks about right, harness (mini-swe-agent) affinities aside
Kimi is the closest to a mature autonomous SWE agent out of open models
DS is weak and needs handholding (though has isolated strengths like debugging)
a mark of good eval: stronger separation of top tier


Serena Ge (Datacurve)@serenaa_ge
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
English
Kevin Huang (Wenqi) retweetledi

This is probably the most correct benchmark out there. Everything in this bench reads spot on
Serena Ge (Datacurve)@serenaa_ge
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks. On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
English
"You should use tools as much as possible, ideally more than 100 times."
Anthropic climbs SWE-Bench Verified by asking agents to use tools 100 times

English
Introducing better-truncate-middle
Truncate very long strings in the middle with pretext without breaking the DOM
English

Here's how to triage:
1. Go to admin.google.com
2. Security → Access and data control → API controls → App access control → Manage Third-Party App Access
3. Search for client ID:
110671459871-30f1spbu0hptbs60cb4vsmv79i7bbvqj
if found → revoke / block
Vercel@vercel
Our investigation has revealed that the incident originated from a third-party AI tool with hundreds of users whose Google Workspace OAuth app was compromised. We recommend that Google Workspace Administrators check for usage of this app immediately. #indicators-of-compromise-iocs" target="_blank" rel="nofollow noopener">vercel.com/kb/bulletin/ve…
English

The Canada Computers grand opening sale is fucking stupid. $6 network switch??? $300 SN850X??? 9800X3D+TUF mobo+32GB DDR5 for $1k???


English
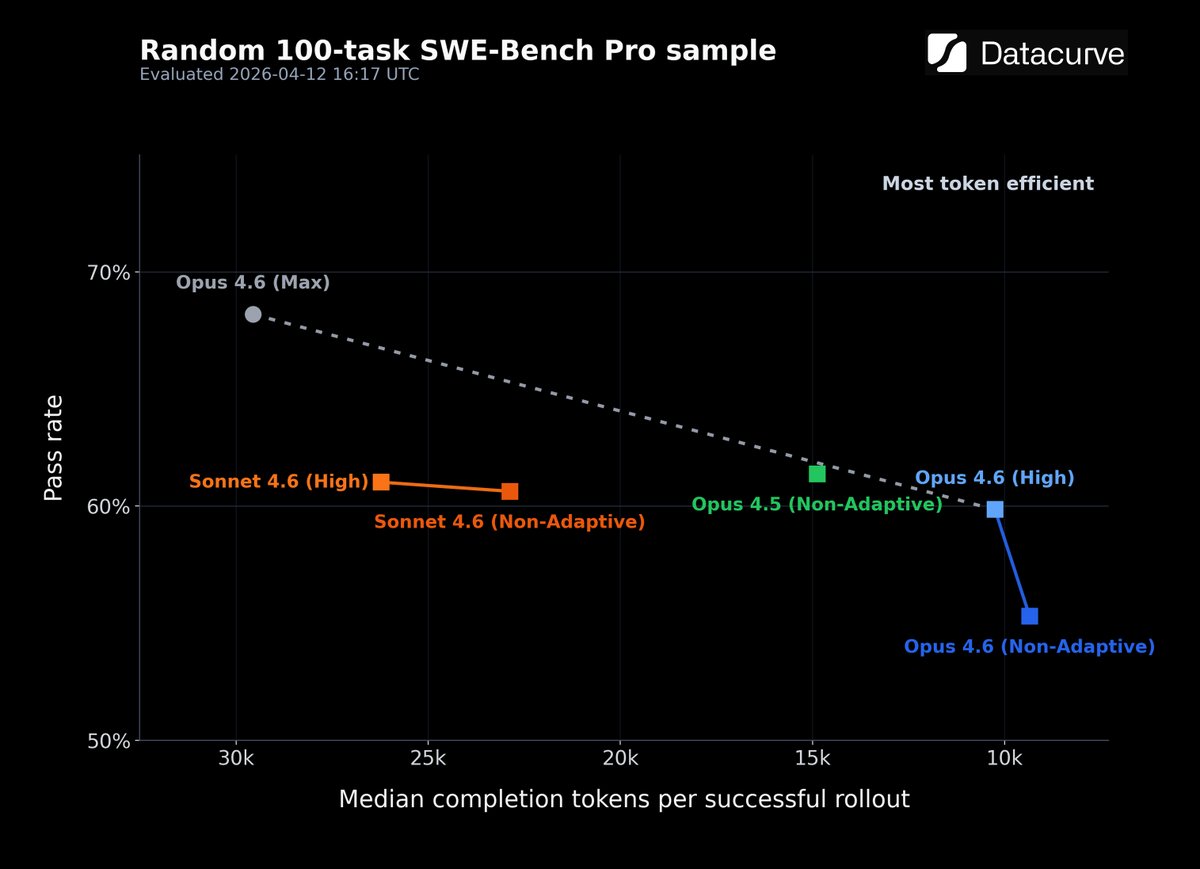
If Opus 4.6 has felt worse lately, this may be part of why:
On a 100-task swe-bench pro sample, opus 4.6 on high finished behind both sonnet 4.6 and opus 4.5 on the same setting!
Turning off adaptive reasoning didn’t seem to change much but max effort did
Evan You@evanyou
Honestly don't know what happened to Claude Code. Tried a one-off simple task on a fresh directory yesterday, tried a bunch of things that didn't work, asked for a ton of permissions, and then got stuck for 4 minutes before I got tired of waiting and killed the session. This was on medium effort. Switched to Codex gpt 5.4 with medium effort and one shotted the task in under 1 minute.
English
“Please listen carefully as our menu options have recently changed”
Dara A.@daradoescode
Just realized @nextjs adds this in the agents.md LOL
English
Kevin Huang (Wenqi) retweetledi

Kevin Huang (Wenqi) retweetledi

We need a name for performative agent parallelization
I propose: “slop theater”
Yiliu@yiliush
source code now available github.com/collaborator-a…
English
Kevin Huang (Wenqi) retweetledi

找回人类溢价的50个隐藏支线任务:
01. 赶在日出前醒来,不戴耳机,去楼下纯粹地走20分钟。
02. 一个人去咖啡店,手机揣兜里别拿出来,干坐着喝完一杯咖啡。
03. 抬头看天,认全夜空里的10个星座,亲手在星图里定位。
04. 写一封永远不会寄出去的信,给曾经的某人或未来的自己。
05. 找一个你从没去过的国家的菜谱,去菜场买菜,亲手做出来。
06. 拿一本纸质书去户外,感受微风翻动纸张的物理阻力。
07. 拿纸笔画一张你家附近的“私房地图”,标出你最爱的隐秘角落。
08. 从零开始,亲手揉面做一顿面条或烤一个面包。
09. 在一个你平时绝不会出门的时间点,走一走你每天上班的老路。
10. 在阳台种一盆薄荷或小葱,亲手照料到它长出新芽。
11. 定个20分钟闹钟,随便画画桌上的水杯或钥匙,不管多难看。
12. 去楼下捡几片落叶或野花,夹在书里做成标本。
13. 买本字帖或拿张废纸,静下心来练一个星期的字。
14. 给你人生当前的“这个章节”,建立一个专属的BGM歌单。
15. 坐在街角咖啡店窗边,记录路人的神态,做一次人类观察员。
16. 学一招关键时刻能自救的防身招式。
17. 解锁一个全新的拉伸姿势,把僵硬的身体抻开。
18. 一个人逛博物馆,没人催你,想在哪一幅画前站多久就站多久。
19. 真诚地夸奖一个陌生人,说完就走,不求反馈。
20. 去看一场线下的脱口秀开放麦,或者听一场冷门讲座。
21. 悄悄去做一次志愿者,重点是:绝对不要发朋友圈。
22. 拼一个复杂的乐高,或者做个木工,用双手造个实物。
23. 拿起工具,把家里那个坏了半年的水龙头或椅子修好。
24. 找一部影史经典,关掉弹幕,不快进地从头看到尾。
25. 挑个周末拔掉网线,做一次24小时的纯粹数字排毒。
26. 拿起相机,去拍十张不同材质的特写:树皮、铁锈、老墙。
27. 随便背一首短诗,单纯为了浪漫。
28. 钻研出一款只属于你个人口味的秘制灵魂蘸酱。
29. 每天给自己留10分钟,什么都不干,原地发呆。
30. 换一种交通工具通勤,如果平时开车,今天试试坐公交看窗外。
31. 去二手书店或旧货市场,淘一件有故事的小玩意。
32. 尝试跟AI聊一个下午的哲学问题,看看它的边界在哪。
33. 给很久没联系的老友打个电话,不发微信,直接拨过去。
34. 学会一首你最喜欢的歌的完整歌词,不看屏幕也能唱完。
35. 尝试连续三天不点外卖,所有的食物都经过自己的手。
36. 在下雨天不撑伞,稍微淋一会儿雨,感受雨水的温度。
37. 去花鸟市场买一束花,亲手修剪并插进瓶子里。
38. 练习一个魔术小戏法,直到能骗过朋友的眼睛。
39. 去附近的公园,坐在草地上观察蚂蚁搬家,看足15分钟。
40. 换一种穿衣风格出门,哪怕只是换个颜色的袜子。
41. 尝试用非惯用手刷牙或者写字,刺激一下大脑。
42. 整理一次旧照片,删掉模糊的,留下那些让你瞬间想笑的。
43. 学习一种新的呼吸法,在焦虑时试着调控自己的频率。
44. 去爬一座山或者登顶一座高楼,俯瞰你生活的城市。
45. 亲手洗一次车,或者深度打扫一次房间的死角。
46. 给自己买一份以前觉得“没用”但一直很想要的小礼物。
47. 尝试在公共场合大声笑出来,如果你遇到有趣的事。
48. 学会说一句小语种里的“谢谢”或“你好”。
49. 找一个绝对安静的地方,听一听自己的心跳声。
50. 睡一个没有任何闹钟、自然醒的觉。
中文
Kevin Huang (Wenqi) retweetledi

I had the same thought so I've been playing with it in nanochat. E.g. here's 8 agents (4 claude, 4 codex), with 1 GPU each running nanochat experiments (trying to delete logit softcap without regression). The TLDR is that it doesn't work and it's a mess... but it's still very pretty to look at :)
I tried a few setups: 8 independent solo researchers, 1 chief scientist giving work to 8 junior researchers, etc. Each research program is a git branch, each scientist forks it into a feature branch, git worktrees for isolation, simple files for comms, skip Docker/VMs for simplicity atm (I find that instructions are enough to prevent interference). Research org runs in tmux window grids of interactive sessions (like Teams) so that it's pretty to look at, see their individual work, and "take over" if needed, i.e. no -p.
But ok the reason it doesn't work so far is that the agents' ideas are just pretty bad out of the box, even at highest intelligence. They don't think carefully though experiment design, they run a bit non-sensical variations, they don't create strong baselines and ablate things properly, they don't carefully control for runtime or flops. (just as an example, an agent yesterday "discovered" that increasing the hidden size of the network improves the validation loss, which is a totally spurious result given that a bigger network will have a lower validation loss in the infinite data regime, but then it also trains for a lot longer, it's not clear why I had to come in to point that out). They are very good at implementing any given well-scoped and described idea but they don't creatively generate them.
But the goal is that you are now programming an organization (e.g. a "research org") and its individual agents, so the "source code" is the collection of prompts, skills, tools, etc. and processes that make it up. E.g. a daily standup in the morning is now part of the "org code". And optimizing nanochat pretraining is just one of the many tasks (almost like an eval). Then - given an arbitrary task, how quickly does your research org generate progress on it?
Thomas Wolf@Thom_Wolf
How come the NanoGPT speedrun challenge is not fully AI automated research by now?
English
Kevin Huang (Wenqi) retweetledi


Kevin Huang (Wenqi) retweetledi

software is still about thinking
software has always been about taking ambiguous human needs and crystallizing them into precise, interlocking systems. the craft is in the breakdown: which abstractions to create, where boundaries should live, how pieces communicate.
coding with ai today creates a new trap: the illusion of speed without structure. you can generate code fast, but without clear system architecture – the real boundaries, the actual invariants, the core abstractions – you end up with a pile that works until it doesn't. it's slop because there's no coherent mental model underneath.
ai doesn't replace systems thinking – it amplifies the cost of not doing it. if you don't know what you want structurally, ai fills gaps with whatever pattern it's seen most. you get generic solutions to specific problems. coupled code where you needed clean boundaries. three different ways of doing the same thing because you never specified the one way.
as Cursor handles longer tasks, the gap between "vaguely right direction" and "precisely understood system" compounds exponentially. when agents execute 100 steps instead of 10, your role becomes more important, not less.
the skill shifts from "writing every line" to "holding the system in your head and communicating its essence":
- define boundaries – what are the core abstractions? what should this component know? where does state live?
- specify invariants – what must always be true? what are the constants and defaults that make the system work?
- guide decomposition – how should this break down? what's the natural structure? what's stable vs likely to change?
- maintain coherence – as ai generates more code, you ensure it fits the mental model, follows patterns, respects boundaries.
this is what great architects and designers do: they don't write every line, but they hold the system design and guide toward coherence. agents are just very fast, very literal team members.
the danger is skipping the thinking because ai makes it feel optional. people prompt their way into codebases they don't understand. can't debug because they never designed it. can't extend because there's no structure, just accumulated features.
people who think deeply about systems can now move 100x faster. you spend time on the hard problem – understanding what you're building and why – and ai handles mechanical translation. you're not bogged down in syntax, so you stay in the architectural layer longer.
the future isn't "ai replaces programmers" or "everyone can code now." it's "people who think clearly about systems build incredibly fast, and people who don't generate slop at scale."
the skill becomes: holding complexity, breaking it down cleanly, communicating structure precisely. less syntax, more systems. less implementation, more architecture. less writing code, more designing coherence.
humans are great at seeing patterns, understanding tradeoffs, making judgment calls about how things should fit together.
ai can't save you from unclear thinking – it just makes unclear thinking run faster.
English